Pandas count()与values_count()用法
Elvirangel 人气:5Pandas count()与values_count()用法
count()
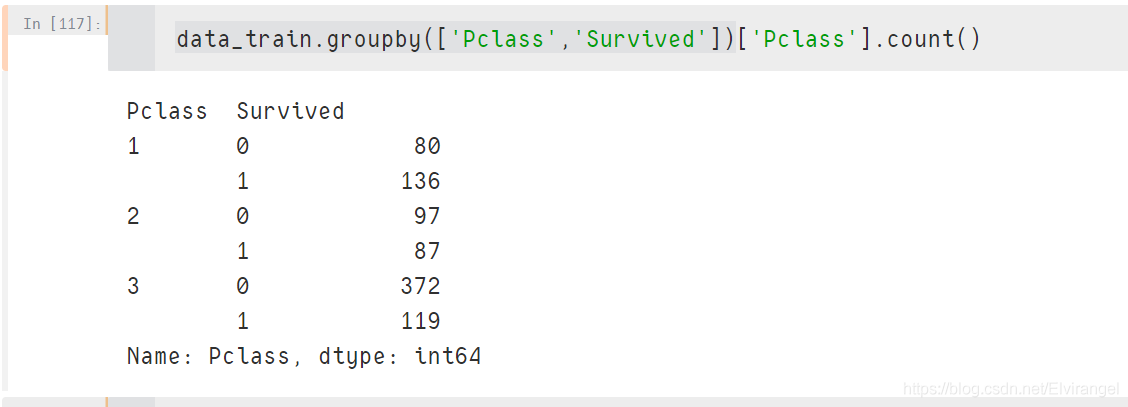
values_count()在指定的统计的列名上
结果多了该列:
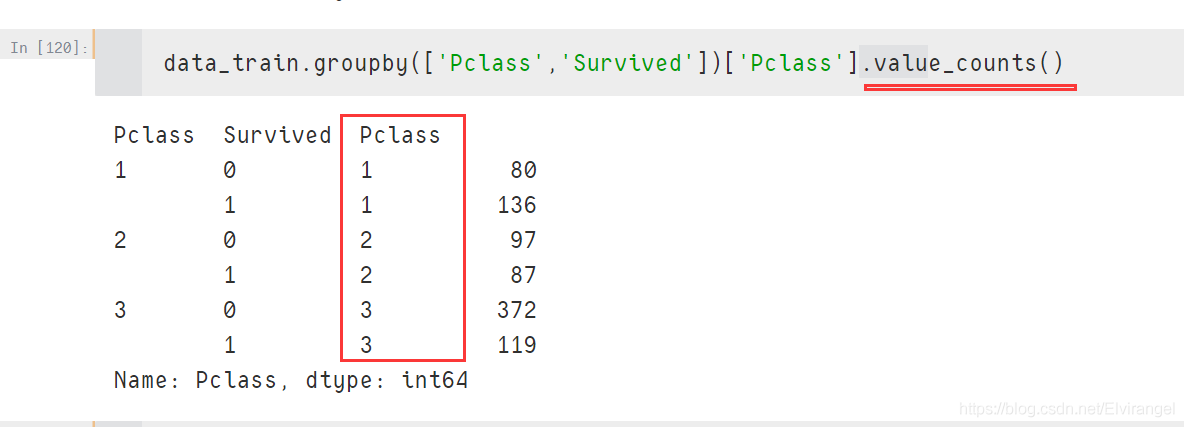
对比:
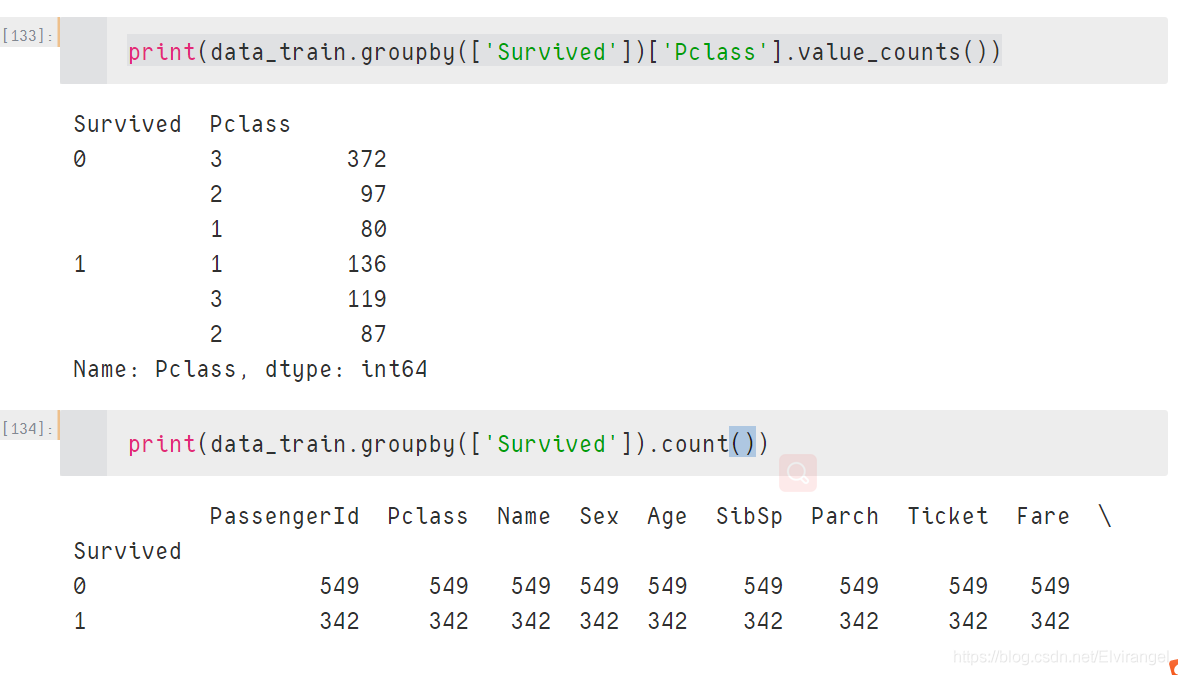
对比:
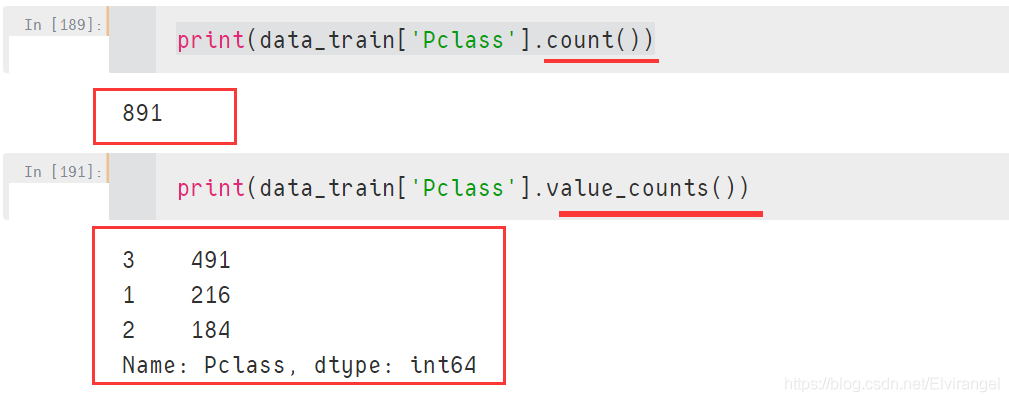
Pandas:count()与value_counts()对比
1. Series.value_counts(self, normalize=False, sort=True, ascending=False, bins=None, dropna=True)
返回一个包含所有值及其数量的 Series。 且为降序输出,即数量最多的第一行输出。
参数含义如下:
| Parameters: | normalize : boolean, default False If True then the object returned will contain the relative frequencies of the unique values. sort : boolean, default True Sort by frequencies. ascending : boolean, default False Sort in ascending order. bins : integer, optional Rather than count values, group them into half-open bins, a convenience for pd.cut, only works with numeric data. dropna : boolean, default True Don’t include counts of NaN. |
|---|---|
| Returns: | Series |
举例如下:
import pandas as pd index = pd.Index([3, 1, 2, 3, 4, np.nan]) index.value_counts() """ 输出为: 3.0 2 4.0 1 2.0 1 1.0 1 dtype: int64 """
如果 normalize 为 True的话,统计的结果会相加 = 1:
import pandas as pd s = pd.Series([3, 1, 2, 3, 4, np.nan]) s.value_counts(normalize=True) """ 输出为: 3.0 0.4 4.0 0.2 2.0 0.2 1.0 0.2 dtype: float64 """
2. Series.count(self, level=None)
返回非空值的数量。若是在 CSV 文件中可用来统计行数,如:
import pandas as pd
file = pd.read_csv('test.csv')
print(file['A'].count())
# 此时输出的即是 A 列的行数参数含义如下:
| Parameters: | level : int or level name, default None If the axis is a MultiIndex (hierarchical), count along a particular level, collapsing into a smaller Series. |
|---|---|
| Returns: | int or Series (if level specified) Number of non-null values in the Series. |
举例如下:
import pands as pd s = pd.Series([0.0, 1.0, np.nan]) s.count() # 此时输出为 2
这就是两者的区别和各自的用途。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容