C++类与对象
小白又菜 人气:1面向过程编程也叫结构化编程。虽然结构化编程的理念提高了程序的清晰度,可靠性,并且方便维护。但它再编写大型的程序时,仍然面临这巨大的挑战,OOP(面向对象编程)提供了一种新的方法。与强调算法的过程性编程不同的是,OOP强调的是数据。--引自《C++ Primer Plus(第六版)》
1.面向对象编程
C++ 是 基于面向对象 的, 关注 的是 对象 ,将一件事情拆分成不同的对象,靠对象之间的交互完成。
在C++中,类是一种规范,它描述了这种新型数据格式,对象是根据这种规范构造的特定数据结构。这里有小伙伴会问,类是什么?这个问题会在(3.类的引入) 中重点介绍。
2.面向过程性编程和面向对象编程
通过下面这个例子,可以更加清晰的揭示OOP的观点和过程性编程的差别。
此举例改变自《C++ Primer Plus(第六版)》:
曼联足球俱乐部的一名新成员被要求记录球队的统计数据。很自然他会借助计算机来完成这项任务。
如果这个新成员是过程性程序员,可能会这样考虑:
我要输入每名运动员的姓名,进球数,助攻数,登场数等其他重要的基本统计数据。之所以使用计算机,是为了简化统计工作,因此让他来计算某些数据。另外,我还希望程序能够显示这些结果。应该如何组织呢?我让main()调用一个函数来获取输入,调用另外一个函数来进行计算,然后调用第三个函数来显示结果。那么,获得下一场比赛的数据后,又改怎么做呢?当然不想从头开始,可以添加一个函数来更新统计数据。可能需要在main函数中添加一个菜单,选择是输入,计算,更新还是显示数据等。则如何表示这些数据呢。可以使用一个字符串来存储选手的姓名,用另外一个数组来存储每位球员的进球数,再用一个数组存储助攻数等等。这种方法太不灵活了。因此可以设计一个结构体来存储每位球员的所有信息,然后用这种结构组成的数组来表示整个球队。
总之,采用过程性编程时,首先要考虑遵守的步骤,然后考虑如何表示这些数据。
如果换成一个OOP程序员,又将如何考虑呢?
首先要考虑数据——不仅要考虑如何表示数据,还要考虑如何使用数据:
OOP程序员会想,我要跟踪的是什么?当然是球员。因此要有一个对象表示整个球员的各个方面(不仅仅是进球数或助攻数)。因此这将是基本数据单元——一个表示球员的姓名和统计数据的对象。我需要一些处理该对象的方法。首先需要一种将基本信息加入到该单元中的方法;其次,计算机应计算一些东西,如进球率。因此要添加一些执行计算的方法。程序应自动完成这些计算,而无需用户的干扰。另外,还需要一些更新和显示信息的方法。所以,用户与数据交互的方式有三种:初始化,更新和报告——这就是用户接口。
总之,采用OOP方法时,首先从用户的角度考虑对象——描述对象所需的数据以及描述用户与数据交互所需的操作。完成对接口的描述之后,需要确定如何实现接口和数据存储。最后,使用寻得设计方案创建出程序。
3.类的引入
在过程化编程中我们用结构体来描述一个复杂对象(这里用C语言举例)。在C语言中,结构体中只能定义变量。结构体关键字是struct。在C++中,结构体内不仅可以定义变量,还可以定义函数
struct Student
{
void SetStudentInfo(const char* name, const char* gender, int age)
{
strcpy(_name, name);
strcpy(_gender, gender);
_age = age;
}
void PrintStudentInfo()
{
cout << _name << " " << _gender << " " << _age << endl;
}
char _name[20];
char _gender[3];
int _age;
};
int main()
{
Student s;
s.SetStudentInfo("Peter", "男", 18);
return 0;
}上面结构体的定义, 在 C++ 中更喜欢用 class 来代替
4.类的定义
class className
{
// 类体:由成员函数和成员变量组成
}; // 一定要注意后面的分号
class为定义类的关键字,ClassName为类的名字,{}中为类的主体,注意类定义结束时后面分号。
类中的元素称为类的成员:类中的数据称为类的属性或者成员变量; 类中的函数称为类的方法或者成员函数。
4.1类的两种定义方式
4.1.1声明和定义全部放在类体中
需要注意:成员函数如果在类中定义 ,编译器可能会将其当成 内联函数 处理。
class Student
{
public:
void SetStudentInfo(const char* name, const char* gender, int age)
{
strcpy(_name, name);
strcpy(_gender, gender);
_age = age;
}
void PrintStudentInfo()
{
cout << _name << " " << _gender << " " << _age << endl;
}
public:
char _name[20];
char _gender[3];
int _age;
};4.2.2.声明和定义不放在类体中
声明放在.h文件中,类的定义放在.cpp文件中
//student.h
//学生
class Student
{
public:
void SetStudentInfo(const char* name, const char* gender, int age);
void PrintStudentInfo();
public:
char _name[20];
char _gender[3];
int _age;
};
//test.cpp
#include "student.h"
void Student::SetStudentInfo(const char* name, const char* gender, int age)
{
strcpy(_name, name);
strcpy(_gender, gender);
_age = age;
}
void Student::PrintStudentInfo()
{
cout << _name << " " << _gender << " " << _age << endl;
}

一般情况下,更期望采用第二种方式。
5.类的访问限定符及封装
5.1 访问限定符
在刚刚的代码中,细心的小伙伴可以发现在类中出现了public这个词,那这到底有什么用呢?这就是我们现在要说明的访问限定符。在C++中,除了public(公有)外,还有private(私有),protected(保护)限定符。
那么为什么要引入访问限定符呢?
C++实现封装的方式:用类将对象的属性与方法结合在一块,让对象更加完善,通过访问权限选择性的将其接口提供给外部的用户使用。
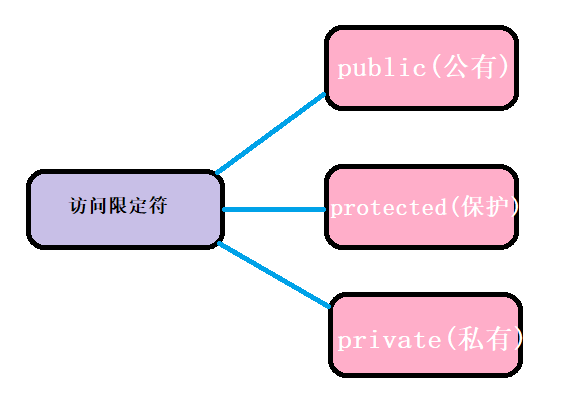
那么他们都有什么含义呢?
【访问限定符说明】
1. public修饰的成员在类外可以直接被访问
2. protected和private修饰的成员在类外不能直接被访问(此处protected和private是类似的)
3. 访问权限作用域从该访问限定符出现的位置开始直到下一个访问限定符出现时为止
4. class的默认访问权限为private,struct为public(因为struct要兼容C)
注意:
1.访问限定符只在编译时有用,当数据映射到内存后,没有任何访问限定符上的区别。
2.C++需要兼容C语言,所以C++中struct可以当成结构体去使用。另外C++中struct还可以用来定义类。和class是定义类是一样的,区别是struct的成员默认访问方式是public,class是的成员默认访问方式是private。
5.2封装
什么是封装?
封装:将数据和操作数据的方法进行有机结合,隐藏对象的属性和实现细节,仅对外公开接口来和对象进行交互。封装的本质是一种管理。 我们使用类数据和方法都封装到一下。 不想给别人看到的,我们使用 protected/private 把成员 封装 起来。 开放 一些共有的成员函数对成员合理的访 问。所以封装本质是一种管理。
在C语言中,大多数情况中调用者和定义结构者不是同一个人,就可能会存在调用者测出bug的可能。
//C语言中数据和方法是分离的
struct Stack
{
int* _a;
int _top;
int _capacity;
};
void StackInit(struct Stack* ps)
{
assert(ps);
ps->_a = NULL;
ps->_capacity = 0;
ps->_top = 0;
}
void StackPush(struct Stack* ps, int x)
{
}
struct Stack StackTop(struct Stack* ps)
{
}
int main()
{
struct Stack st;
StackInit(&st);
StackPush(&st, 1);
StackPush(&st, 2);
StackPush(&st, 3);
printf("%d\n", StackTop(&st));
printf("%d\n", st._a[st._top]); //可能就存在误用
printf("%d\n", st._a[st._top - 1]); //可能就存在误用
}这是我们在数据结构阶段用C语言实现的一个栈,在主函数中,我们想要访问栈顶的元素。在常规情况下,我们调用StackTop函数即可访问到栈顶元素。但是我们也可以使用访问数组下标的方式拿到栈顶元素,此时如果调用者不清楚使用者的定义方式,就有可能存在误用。例如:这段代码我们定义_top是栈顶元素的下一个元素的下标,因此栈顶元素的下标应该是_top-1,而调用者如果误以为top就是栈顶元素的下标,即有可能存在误用。因此这里太过自由。
为了解决这一问题,在C++中,结构体不仅可以定义变量,还可以定义函数。我们如果把函数定义在类中,我们把成员变量封装在类中,外界函数无法调用。因此如果此时我们想调用栈顶元素,我们只能调用Top函数的接口。这就避免了上述问题的发生。
class Stack
{
private:
void Checkcapacity()
{
}
public:
void Init()
{
}
void Push(int x)
{
}
void Top()
{
}
private:
int* _a;
int _top;
int _capacity;
};6.类的作用域
类定义了一个新的作用域 ,类的所有成员都在类的作用域中 。 在类体外定义成员,需要使用 :: 作用域解析符指明成员属于哪个类域。 就像在这段代码中,我们想要在类作用域外定义成员,就要使用::

7.类的实例化
用类类型创建对象的过程,称为类的实例化
1. 类只是 一个 模型 一样的东西,限定了类有哪些成员,定义出一个类 并没有分配实际的内存空间 来存储它
2. 一个类可以实例化出多个对象, 实例化出的对象 占用实际的物理空间,存储类成员变量
3. 做个比方。 类实例化出对象就像现实中使用建筑设计图建造出房子,类就像是设计图 ,只设计出需要什么东西,但是并没有实体的建筑存在,同样类也只是一个设计,实例化出的对象才能实际存储数据,占用物理空间
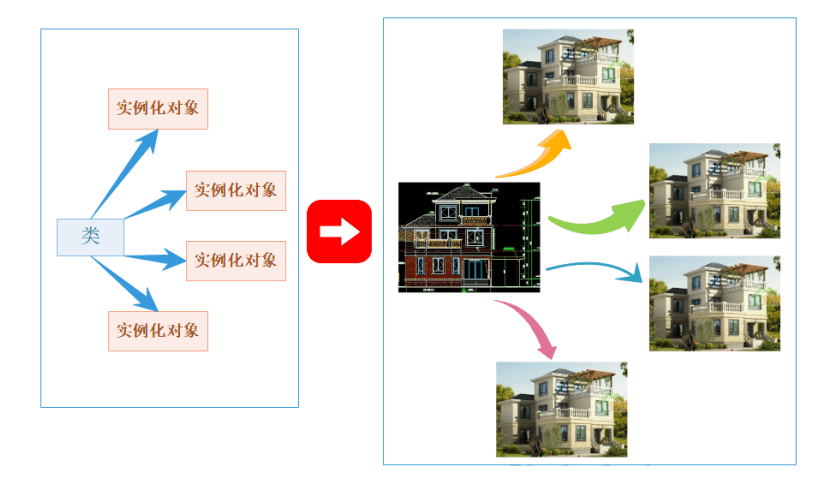
我们继续引用我们刚刚用C++所写的栈,其中st就是一个实例化对象。
class Stack
{
private:
void Checkcapacity()
{
}
public:
void Init()
{
}
void Push(int x)
{
}
void Top()
{
}
private:
int* _a;
int _top;
int _capacity;
};
int main()
{
Stack st;
st.Init();
st.Push(1);
st.Top();
return 0;
}
8.类对象模型
如何计算类对象的大小
在C语言中,我们在学习结构体的时候知道,由于结构体中只定义变量,因此我们是可以计算出结构体的大小的。sizeof计算的是定义类型对象的大小。

那在C++中,由于类中不仅定义变量,还定义函数,那么类的大小是怎么计算的呢?
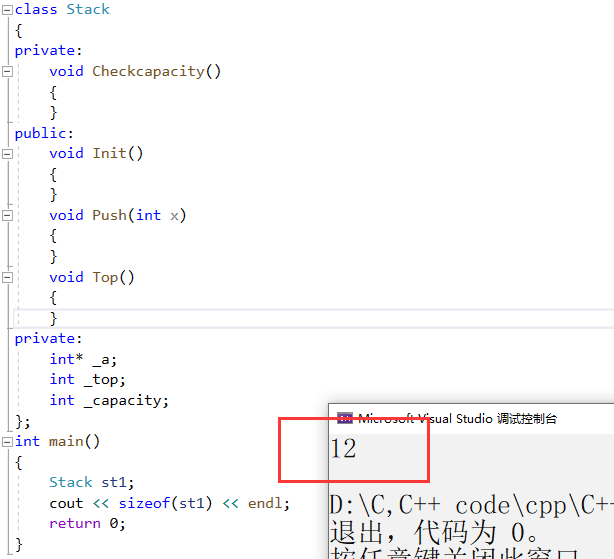
我们发现此类的大小还是12。
因此我们猜测:类对象的存储方式只保存成员变量,成员函数存放在公共的代码段。
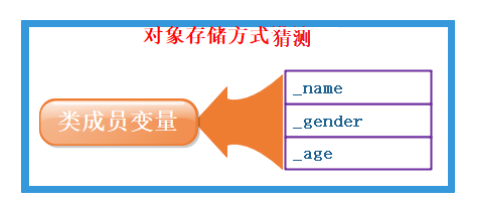
那我们思考为什么采用这种方式呢?
在上述中说到,类就像是一份建筑图纸,而所建造的每一个房子中的name,capacity,top应当是不一样的。但是所调用的方法Init(),Top()应当是同一个方法。因此没有必要把函数在对象中存一份。我们也可以通过汇编看看不同的对象是否调用同一个函数。
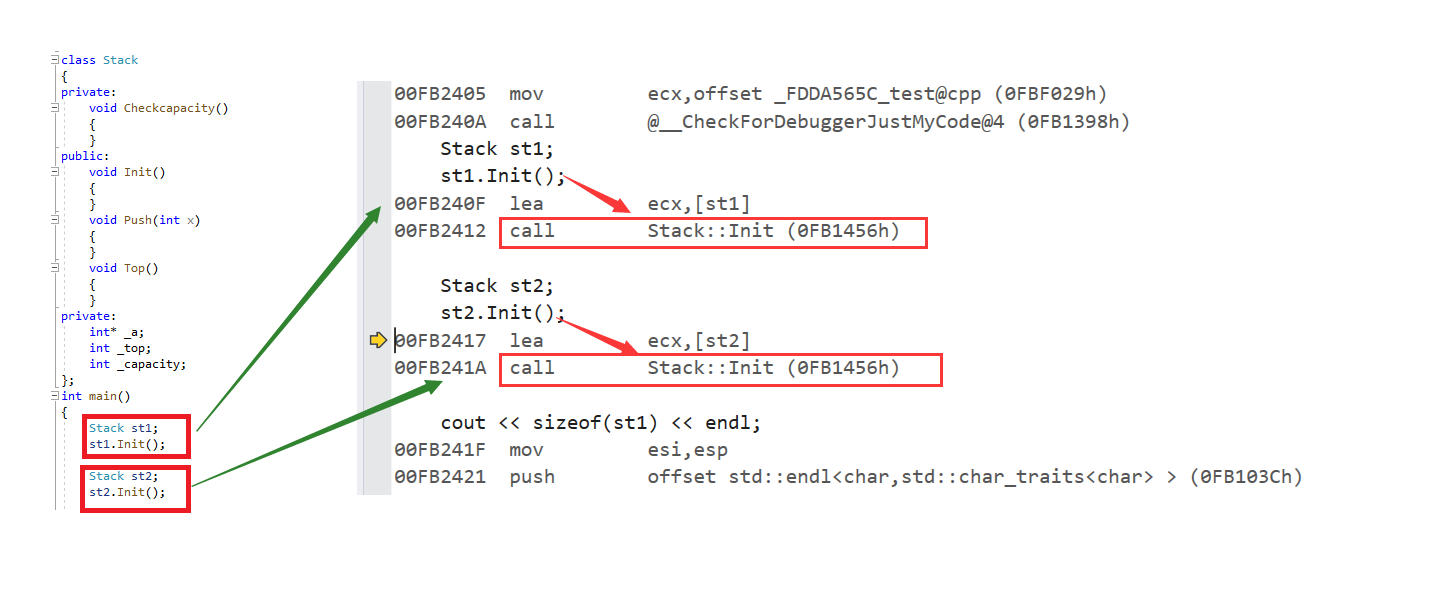
我们能够发现st1和st2所调用得Init()函数是同一份。因此如果都把函数存在类中,就会造成浪费。因此我们可以把函数放在一个公共的区域,这个区域叫做代码段。
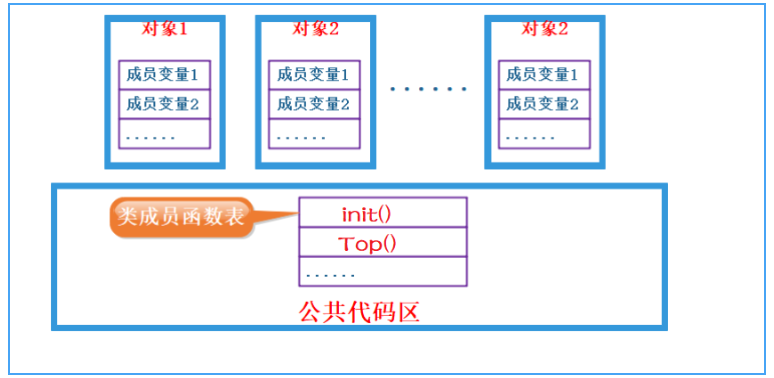
结论:一个类的大小,实际就是该类中”成员变量”之和,当然也要进行内存对齐,注意空类的大小,空类比较特殊,编译器给了空类一个字节来唯一标识这个类。注意:最小内存单元是1.操作系统规定都要有地址记录,就像sizeof(void) = 1。
加载全部内容