Python标准库uuid模块
Gnbp 人气:0UUID (Universally Unique Identifier,通用唯一标识)是一个128位的用于计算机系统中以识别信息的数目,虽然生成UUID的概率不为零,但是无限接近零,因此可以忽略不记,如此一来,每个人都可以建立不与其他人冲突的UUID。
UUID格式组成
规范的文本中,UUID的十六个八位字节标识位32个十六进制(基数16)数字,显示在由字符分割的五个组中,8-4-4-4-12总格36个字符(32个字母数字字符和4个连字符),如:
123e4567-e89b-12d3-a456-426655440000
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
其中M代表版本,由下面的知识可知,这个UUID 可能是通过Python的 uuid.uuid1(node, clock_seq)生成
Python 中的uuid 模块
在Python 2.5以后引入,接口包括:不可变对象UUID(UUID类)和函数uuid1()、uuid3()、uuid4()、uuid5(),后面四个函数用于生成“RFC 4122” 规范中指定的第1、3、4、5版UUID。具体算法如下:
UUID()
class uuid.UUID([hex[, bytes[, bytes_le[, fields[, int[, version]]]]]])
该类用于从参数给定的内容中实例化UUID对象(hex, bytes, bytes_le, fields, int 必须且只能指定一个):
hex:指定32个字符以创建UUID对象,当指定一个32个字符构成的字符串来创建一个UUID对象时,花括号、连字符和URN前缀等都是可选的;
bytes:指定一个大端字节序的总长16字节的字节串来创建UUID对象;
bytes_le:指定一个小端字节序的总长16字节的字节串来创建UUID对象;
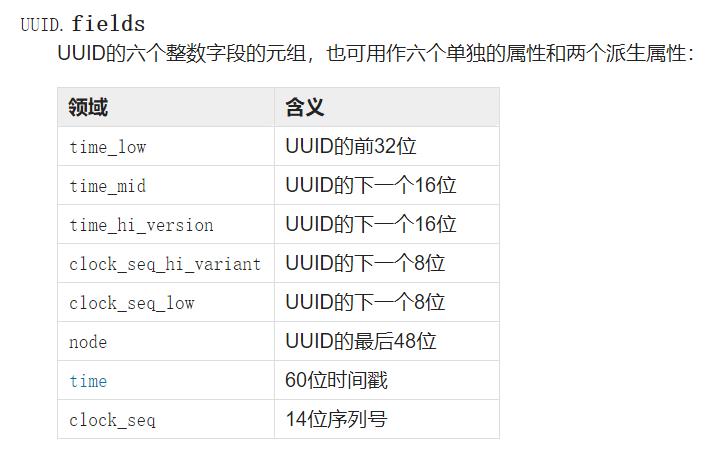
fields:指定6个整数域,共计128位来创建UUID(其中,32位作为time_low段,16位作为time_mid段,16位作为time_hi_version段,8位作为clock_seq_hi_variant段,8位作为clock_seq_low段,48位作为node段);
int:直接指定一个长度为128个二进制位的整数用于创建UUID对象;
version:(可选)指定UUID的版本,从1到5,一旦指定了该参数,生成的UUID将具有自己的变体(variant)和版本数,具体请参考RFC 4122
下面的各种方法创建相同的UUID对象
u = UUID('{12345678-1234-5678-1234-567812345678}')
u = UUID(hex = '12345678123456781234567812345678')
u = UUID('urn:uuid:12345678-1234-5678-1234-567812345678')
u = UUID(bytes='\x12\x34\x56\x78'*4)
u = UUID(bytes_le='\x78\x56\x34\x12\x34\x12\x78\x56' +
'\x12\x34\x56\x78\x12\x34\x56\x78')
u = UUID(fields=(0x12345678, 0x1234, 0x5678, 0x12, 0x34, 0x567812345678))
u = UUID(int=0x12345678123456781234567812345678)uuid1()
从主机ID、序列号和当前时间生成UUID。如果未给定“node”,则使用getnode() 获取硬件地址。如果给出“时钟序列”,则将其用作序列号;否则,将选择随机的14位序列号。
# 源码参考
def uuid(node=None, clock_seq=None): ... return UUID(fields=(time_low, time_mid, time_hi_version, clock_seq_hi_variant, clock_seq_low, node), version=1)
fields 各个参数含义如下图:
uuid3()
基于命名空间标识符(实质上是一个UUID)和一个名称(实质上是一个字符串)的MD5哈希值生成的UUID
# 源码参考
def uuid3(namespace, name):
"""Generate a UUID from the MD5 hash of a namespace UUID and a name."""
from hashlib import md5
hash = md5(namespace.bytes + bytes(name, "utf-8")).digest()
return UUID(bytes=hash[:16], version=3)
uuid4()
基于随机数生成的UUID
# 源码参考
import os
def uuid4():
"""Generate a random UUID."""
return UUID(bytes=os.urandom(16), version=4)
uuid5()
基于命名空间标识符(实质上是一个UUID)和一个名称(实质上是一个字符串)的SHA-1哈希值生成的UUID
# 源码参考
def uuid5(namespace, name):
"""Generate a UUID from the SHA-1 hash of a namespace UUID and a name."""
from hashlib import sha1
hash = sha1(namespace.bytes + bytes(name, "utf-8")).digest()
return UUID(bytes=hash[:16], version=5)
由源码可知,uuid1() 使用的是 UUID(fields=(...))
uuid3()、uuid4()、uuid5() 均使用的是 UUID(bytes=...)
“RFC 4122” 推荐使用版本5(SHA1)而不是版本3(MD5)
uuid1() 中的getnode()
获取硬件的地址并以48位二进制长度的整数形式返回,这里所说的硬件地址是指网络接口的MAC 地址,如果一个机器有多个网络接口,可能返回其中的任一个。如果获取失败,将按照“RFC 4122” 的规定随机返回48位数字,并将第8位设置为1(其组播位(第一个八位位组的最低有效位)设置为1)
关于uuid3()和uuid5()中提到的命名空间标识符,uuid模块定义了如下的备选项:
uuid.NAMESPACE_DNS
当指定该命名空间时,参数name 是一个完全限定的(fully-qualified)域名
uuid.NAMESPACE_URL
当指定该命名空间时,参数name 是一个URL
uuid.NAMESPACE_OID
当指定该命名空间时,参数name 是一个ISO OID
uuid.NAMESPACE_X500
当指定该命名空间时,参数name 是一个DER 中的X.500 DN或文本输出格式
这些标识符在源码中统一指向 UUID('6ba7b810-9dad-11d1-80b4-00c04fd430c8'),因此命名空间仅仅作为标识用,定义了name 参数的格式
UUID实际应用
uuid1 适应用分布式计算环境,具有高度的唯一性;
uuid3 和uuid5 适合于一定范围的名字唯一,且需要或可能重复生成UUID 的环境下;
uuid4 最简单,但完全随机,不可控,建议可以在DRF 生成和验证JWT 时做用户的SECRET_KEY 用,用来保证用户每次登录,异设备同时登录,修改密码等操作,JWT 失效问题
UUID 的劣势
1.varchar(36)字符串占用空间比较大,但携带的信息很少,且不直观
2.以此建立索引的时候,非常耗性能且慢
3.UUID 是无序的,但是业务系统很多时候希望生成的 是有序的,或者粗略有序
参考资料:
- uuid — UUID objects according to RFC 4122 https://docs.python.org/3/library/uuid.html
- Python--uuid http://www.cnblogs.com/Security-Darren/p/4252868.html
- Python 使用UUID 库生成唯一ID https://www.cnblogs.com/kaituorensheng/p/5530902.html
- Universally unique identifier https://en.wikipedia.org/wiki/Universally_unique_identifier
- 使用UUID的劣势 https://blog.csdn.net/woshiyexinjie/article/details/83351677
总结
加载全部内容