Vue NodeJS大文件上传
YoYo君 人气:0常见的文件上传方式可能就是new一个FormData,把文件append进去以后post给后端就可以了。但如果采用这种方式来上传大文件就很容易产生上传超时的问题,而且一旦失败还得从新开始,在漫长的等待过程中用户还不能刷新浏览器,不然前功尽弃。因此这类问题一般都是通过切片上传。
整体思路
- 将文件切成多个小文件
- hash计算,需要计算一个文件的唯一标识,这样下次再传,就能筛选出剩余的切片进行上传。
- 所有切片上传后,通知服务端进行切片合成
- 上传成功通知前端文件路径
- 整个过程如果出现失败,下次再传时,由于之前计算过文件hash,可以筛选出未传数的切片续传(断点续传); 如果整个文件已经上传过,就不需要传输(秒传)
项目演示
这里用vue和node分别搭建前端和后端
前端界面
fileUpload.vue
<template>
<div class="wrap">
<div >
<el-upload
ref="file"
:http-request="handleFileUpload"
action="#"
class="avatar-uploader"
:show-file-list='false'
>
<el-button type="primary">上传文件</el-button>
</el-upload>
<div>
<div>计算hash的进度:</div>
<el-progress :stroke-width="20" :text-inside="true" :percentage="hashProgress"></el-progress>
</div>
<div>
<div>上传进度:</div>
<el-progress :stroke-width="20" :text-inside="true" :percentage="uploaedProgress"></el-progress>
</div>
</div>
</div>
</template>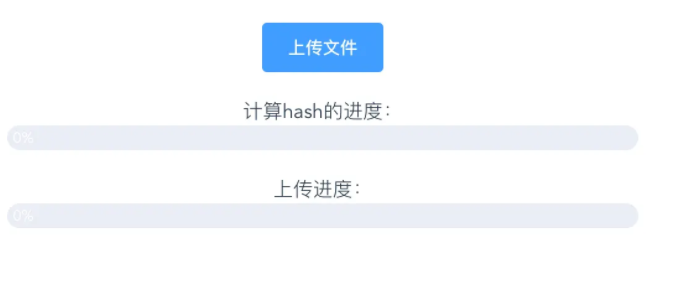
文件切片
利用 File.prototype.slice 的方法可以对文件进行切片 fileUpload.vue
const CHUNK_SIZE=1024*1024//每个切片为1M
import sparkMD5 from 'spark-md5'
export default {
name:'file-upload',
data(){
return {
file:null,//上传的文件
chunks:[],//切片
hashProgress:0,//hash值计算进度
hash:''
}
},
methods:{
async handleFileUpload(e){
if(!file){
return
}
this.file=file
this.upload()
},
//文件上传
async upload(){
//切片
const chunks=this.createFileChunk(this.file)
//...
//hash计算
const hash=await this.calculateHash1(chunks)
}
},
//文件切片
createFileChunk(size=CHUNK_SIZE){
const chunks=[];
let cur=0;
const maxLen=Math.ceil(this.file.size/CHUNK_SIZE)
while(cur<maxLen){
const start=cur*CHUNK_SIZE;
const end = ((start + CHUNK_SIZE) >= this.file.size) ? this.file.size : start + CHUNK_SIZE;
chunks.push({index:cur,file:this.file.slice(start,end)})
cur++
}
return chunks
},
}hash计算
利用md5可以计算出文件唯一的hash值
这里可以使用 spark-md5 这个库可以增量计算文件的hash值
calculateHash1(chunks){
const spark=new sparkMD5.ArrayBuffer()
let count =0
const len=chunks.length
let hash
const self=this
const startTime = new Date().getTime()
return new Promise((resolve)=>{
const loadNext=index=>{
const reader=new FileReader()
//逐片读取文件切片
reader.readAsArrayBuffer(chunks[index].file)
reader.onload=function(e){
const endTime=new Date().getTime()
chunks[count]={...chunks[count],time:endTime-startTime}
count++
//读取成功后利用spark做增量计算
spark.append(e.target.result)
if(count==len){
self.hashProgress=100
//返回整个文件的hash
hash=spark.end()
resolve(hash)
}else{
//更新hash计算进度
self.hashProgress+=100/len
loadNext(index+1)
}
}
}
loadNext(0)
})
},

可以看到整个过程还是比较费时间的,有可能会导致UI阻塞(卡),因此可以通过webwork等手段优化这个过程,这点我们放在最后讨论
查询切片状态
在知道了文件的hash值以后,在上传切片前我们还要去后端查询下文件的上传状态,如果已经上传过,那就没有必要再上传,如果只上传了一部分,那就上传还没有上过过的切片(断点续传)
前端 fileUpload.vue
//...
methods:{
//...
async upload(){
//...切片,计算hash
this.hash=hash
//查询是否上传 将hash和后缀作为参数传入
this.$http.post('/checkfile',{
hash,
ext:this.file.name.split('.').pop()
})
.then(res=>{
//接口会返回两个值 uploaded:Boolean 表示整个文件是否上传过 和 uploadedList 哪些切片已经上传
const {uploaded,uploadedList}=res.data
//如果已经上传过,直接提示用户(秒传)
if(uploaded){
return this.$message.success('秒传成功')
}
//这里我们约定上传的每个切片名字都是 hash+‘-'+index
this.chunks=chunks.map((chunk,index)=>{
const name=hash+'-'+index
const isChunkUploaded=(uploadedList.includes(name))?true:false//当前切片是否有上传
return {
hash,
name,
index,
chunk:chunk.file,
progress:isChunkUploaded?100:0//当前切片上传进度,如果有上传即为100 否则为0,这是用来之后计算总体上传进度
}
})
//上传切片
this.uploadChunks(uploadedList)
})
}
}
文件切片 this.chunks

服务端 server/index.js
const Koa=require('koa')
const Router=require('koa-router')
const koaBody = require('koa-body');
const path=require('path')
const fse=require('fs-extra')
const app=new Koa()
const router=new Router()
//文件存放在public下
const UPLOAD_DIR=path.resolve(__dirname,'public')
app.use(koaBody({
multipart:true, // 支持文件上传
}));
router.post('/checkfile',async (ctx)=>{
const body=ctx.request.body;
const {ext,hash}=body
//合成后的文件路径 文件名 hash.ext
const filePath=path.resolve(UPLOAD_DIR,`${hash}.${ext}`)
let uploaded=false
let uploadedList=[]
//判断文件是否已上传
if(fse.existsSync(filePath)){
uploaded=true
}else{
//所有已经上传过的切片被存放在 一个文件夹,名字就是该文件的hash值
uploadedList=await getUploadedList(path.resolve(UPLOAD_DIR,hash))
}
ctx.body={
code:0,
data:{
uploaded,
uploadedList
}
}
})
async function getUploadedList(dirPath){
//将文件夹中的所有非隐藏文件读取并返回
return fse.existsSync(dirPath)?(await fse.readdir(dirPath)).filter(name=>name[0]!=='.'):[]
}
切片上传(断点续传)
再得知切片上传状态后,就能筛选出需要上传的切片来上传。 前端 fileUpload.vue
uploadChunks(uploadedList){
//每一个要上传的切片变成一个请求
const requests=this.chunks.filter(chunk=>!uploadedList.includes(chunk.name))
.map((chunk,index)=>{
const form=new FormData()
//所有上传的切片会被存放在 一个文件夹,文件夹名字就是该文件的hash值 因此需要hash和name
form.append('chunk',chunk.chunk)
form.append('hash',chunk.hash)
form.append('name',chunk.name)
//因为切片不一定是连续的,所以index需要取chunk对象中的index
return {form,index:chunk.index,error:0}
})//所有切片一起并发上传
.map(({form,index})=>{
return this.$http.post('/uploadfile',form,{
onUploadProgress:progress=>{
this.chunks[index].progress=Number(((progress.loaded/progress.total)*100).toFixed(2)) //当前切片上传的进度
}
})
})
Promise.all(requests).then((res)=>{
//所有请求都成功后发送请求给服务端合并文件
this.mergeFile()
})
},
服务端
router.post('/uploadfile',async (ctx)=>{
const body=ctx.request.body
const file=ctx.request.files.chunk
const {hash,name}=body
//切片存放的文件夹所在路径
const chunkPath=path.resolve(UPLOAD_DIR,hash)
if(!fse.existsSync(chunkPath)){
await fse.mkdir(chunkPath)
}
//将文件从临时路径里移动到文件夹下
await fse.move(file.filepath,`${chunkPath}/${name}`)
ctx.body={
code:0,
message:`切片上传成功`
}
})
上传后切片保存的位置

文件总体上传进度
总体上传进度取决于每个切片上传的进度和文件总体大小,可以通过计算属性来实现
fileUpload.vue
uploaedProgress(){
if(!this.file || !this.chunks.length){
return 0
}
//累加每个切片已上传的部分
const loaded =this.chunks.map(chunk=>{
const size=chunk.chunk.size
const chunk_loaded=chunk.progress/100*size
return chunk_loaded
}).reduce((acc,cur)=>acc+cur,0)
return parseInt(((loaded*100)/this.file.size).toFixed(2))
},
合并文件
前端 fileUpload.vue
//要传给服务端文件后缀,切片的大小和hash值
mergeFile(){
this.$http.post('/mergeFile',{
ext:this.file.name.split('.').pop(),
size:CHUNK_SIZE,
hash:this.hash
}).then(res=>{
if(res && res.data){
console.log(res.data)
}
})
},
服务端
router.post('/mergeFile',async (ctx)=>{
const body=ctx.request.body
const {ext,size,hash}=body
//文件最终路径
const filePath=path.resolve(UPLOAD_DIR,`${hash}.${ext}`)
await mergeFile(filePath,size,hash)
ctx.body={
code:0,
data:{
url:`/public/${hash}.${ext}`
}
}
})
async function mergeFile(filePath,size,hash){
//保存切片的文件夹地址
const chunkDir=path.resolve(UPLOAD_DIR,hash)
//读取切片
let chunks=await fse.readdir(chunkDir)
//切片要按顺序合并,因此需要做个排序
chunks=chunks.sort((a,b)=>a.split('-')[1]-b.split('-')[1])
//切片的绝对路径
chunks=chunks.map(cpath=>path.resolve(chunkDir,cpath))
await mergeChunks(chunks,filePath,size)
}
//边读边写至文件最终路径
function mergeChunks(files,dest,CHUNK_SIZE){
const pipeStream=(filePath,writeStream)=>{
return new Promise((resolve,reject)=>{
const readStream=fse.createReadStream(filePath)
readStream.on('end',()=>{
//每一个切片读取完毕后就将其删除
fse.unlinkSync(filePath)
resolve()
})
readStream.pipe(writeStream)
})
}
const pipes=files.map((file,index) => {
return pipeStream(file,fse.createWriteStream(dest,{
start:index*CHUNK_SIZE,
end:(index+1)*CHUNK_SIZE
}))
});
return Promise.all(pipes)
}
大文件切片上传的功能已经实现,让我们来看下效果(这里顺便展示一下单个切片的上传进度)

可以看到由于大量的切片请求并发上传,虽然浏览器本身对同时并发的请求数有所限制(可以看到许多请求是pending状态),但还是造成了卡顿,因此这个流程还是需要做一个优化
优化
请求并发数控制
fileUpload.vue
逐片上传
这也是最直接的一种做法,可以看作是并发请求的另一个极端,上传成功一个再上传第二个,这里还要处理一下错误重试,如果连续失败3次,整个上传过程终止
uploadChunks(uploadedList){
console.log(this.chunks)
const requests=this.chunks.filter(chunk=>!uploadedList.includes(chunk.name))
.map((chunk,index)=>{
const form=new FormData()
form.append('chunk',chunk.chunk)
form.append('hash',chunk.hash)
form.append('name',chunk.name)
return {form,index:chunk.index,error:0}
})
// .map(({form,index})=>{
// return this.$http.post('/uploadfile',form,{
// onUploadProgress:progress=>{
// this.chunks[index].progress=Number(((progress.loaded/progress.total)*100).toFixed(2))
// }
// })
// })
// // console.log(requests)
// Promise.all(requests).then((res)=>{
// console.log(res)
// this.mergeFile()
// })
const sendRequest=()=>{
return new Promise((resolve,reject)=>{
const upLoadReq=(i)=>{
const req=requests[i]
const {form,index}=req
this.$http.post('/uploadfile',form,{
onUploadProgress:progress=>{
this.chunks[index].progress=Number(((progress.loaded/progress.total)*100).toFixed(2))
}
})
.then(res=>{
//最后一片上传成功,整个过程完成
if(i==requests.length-1){
resolve()
return
}
upLoadReq(i+1)
})
.catch(err=>{
this.chunks[index].progress=-1
if(req.error<3){
req.error++
//错误累加后重试
upLoadReq(i)
}else{
reject()
}
})
}
upLoadReq(0)
})
}
//整个过程成功后再合并文件
sendRequest()
.then(()=>{
this.mergeFile()
})
},
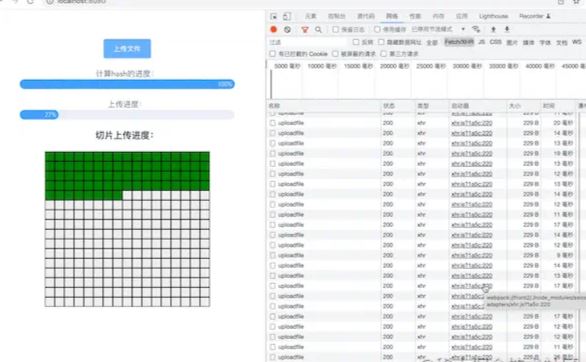
可以看到每次只有一个上传请求
最终生成的文件
多个请求并发
逐个请求的确是可以解决卡顿的问题,但是效率有点低,我们还可以在这个基础上做到有限个数的并发
一般这种问题的思路就是要形成一个任务队列,开始的时候先从requests中取出指定并发数的请求对象(假设是3个)塞满队列并各自开始请求任务,每一个任务结束后将该任务关闭退出队列然后再从request说中取出一个元素加入队列并执行,直到requests清空,这里如果某一片请求失败的话那还要再塞入request队首,这样下次执行时还能从这个请求开始达到了重试的目的
async uploadChunks(uploadedList){
console.log(this.chunks)
const requests=this.chunks.filter(chunk=>!uploadedList.includes(chunk.name))
.map((chunk,index)=>{
const form=new FormData()
form.append('chunk',chunk.chunk)
form.append('hash',chunk.hash)
form.append('name',chunk.name)
return {form,index:chunk.index,error:0}
})
const sendRequest=(limit=1,task=[])=>{
let count=0 //用于记录请求成功次数当其等于len-1时所有切片都已上传成功
let isStop=false //标记错误情况,如果某一片错误数大于3整个任务标记失败 并且其他并发的请求凭次标记也不在递归执行
const len=requests.length
return new Promise((resolve,reject)=>{
const upLoadReq=()=>{
if(isStop){
return
}
const req=requests.shift()
if(!req){
return
}
const {form,index}=req
this.$http.post('/uploadfile',form,{
onUploadProgress:progress=>{
this.chunks[index].progress=Number(((progress.loaded/progress.total)*100).toFixed(2))
}
})
.then(res=>{
//最后一片
if(count==len-1){
resolve()
}else{
count++
upLoadReq()
}
})
.catch(err=>{
this.chunks[index].progress=-1
if(req.error<3){
req.error++
requests.unshift(req)
upLoadReq()
}else{
isStop=true
reject()
}
})
}
while(limit>0){
//模拟形成了一个队列,每次结束再递归执行下一个任务
upLoadReq()
limit--
}
})
}
sendRequest(3).then(res=>{
console.log(res)
this.mergeFile()
})
},
hash值计算优化
除了请求并发需要控制意外,hash值的计算也需要关注,虽然我们采用了增量计算的方法,但是可以看出依旧比较费时,也有可能会阻塞UI
webWork
这相当于多开了一个线程,让hash计算在新的线程中计算,然后将结果通知会主线程
calculateHashWork(chunks){
return new Promise((resolve)=>{
//这个js得独立于项目之外
this.worker=new worker('/hash.js')
//切片传入现成
this.worker.postMessage({chunks})
this.worker.onmessage=e=>{
//线程中返回的进度和hash值
const {progress,hash}=e.data
this.hashProgress=Number(progress.toFixed(2))
if(hash){
resolve(hash)
}
}
})
},
hash.js
//独立于项目之外,得单独
// 引入spark-md5
self.importScripts('spark-md5.min.js')
self.onmessage = e=>{
// 接受主线程传递的数据,开始计算
const {chunks } = e.data
const spark = new self.SparkMD5.ArrayBuffer()
let progress = 0
let count = 0
const loadNext = index=>{
const reader = new FileReader()
reader.readAsArrayBuffer(chunks[index].file)
reader.onload = e=>{
count ++
spark.append(e.target.result)
if(count==chunks.length){
//向主线程返回进度和hash
self.postMessage({
progress:100,
hash:spark.end()
})
}else{
progress += 100/chunks.length
//向主线程返回进度
self.postMessage({
progress
})
loadNext(count)
}
}
}
loadNext(0)
}
时间切片
还有一种做法就是借鉴react fiber架构,可以通过时间切片的方式在浏览器空闲的时候计算hash值,这样浏览器的渲染是联系的,就不会出现明显卡顿
calculateHashIdle(chunks){
return new Promise(resolve=>{
const spark=new sparkMD5.ArrayBuffer()
let count=0
const appendToSpark=async file=>{
return new Promise(resolve=>{
const reader=new FileReader()
reader.readAsArrayBuffer(file)
reader.onload=e=>{
spark.append(e.target.result)
resolve()
}
})
}
const workLoop=async deadline=>{
//当切片没有读完并且浏览器有剩余时间
while(count<chunks.length && deadline.timeRemaining()>1){
await appendToSpark(chunks[count].file)
count++
if(count<chunks.length){
this.hashProgress=Number(((100*count)/chunks.length).toFixed(2))
}else{
this.hashProgress=100
const hash=spark.end()
resolve(hash)
}
}
window.requestIdleCallback(workLoop)
}
window.requestIdleCallback(workLoop)
})
}加载全部内容