Python Seaborn分布图
数据STUDIO 人气:0前言
在本文中,我们将介绍10个示例,以掌握如何使用用于Python的Seaborn库创建图表。
任何数据产品的第一步都应该是理解原始数据。对于成功和高效的产品,这一步骤占据了整个工作流程的很大一部分。
有几种方法用于理解和探索数据。其中之一是创建数据可视化。它们帮助我们探索和解释数据。
通过创建适当和设计良好的可视化,我们可以发现数据中的底层结构和关系。
分布区在数据分析中起着至关重要的作用。它们帮助我们检测异常值和偏态,或获得集中趋势(平均值、中值和模态)度量的概述。
对于示例,我们将使用Kaggle上可用的墨尔本住房数据集中的一个小样本。
我们从导入库并将数据集读入Pandas数据帧开始。
import pandas as pd import seaborn as sns sns.set(style="darkgrid", font_scale=1.2) df = pd.read_csv( "/content/melb_housing.csv", usecols=["Regionname", "Type", "Rooms", "Distance", "Price"] ) df.head()
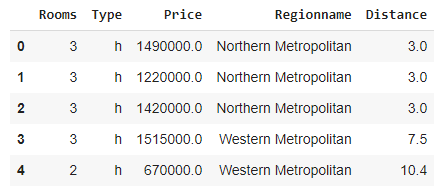
该数据集包含了墨尔本房屋的一些特征及其价格。
Seaborn的离散函数允许创建3种不同类型的分布区,分别是:
- 柱状图
- Kde(核密度估计)图
- Ecdf图
我们只需要调整kind参数来选择plot的类型。
示例 1
第一个例子是创建一个基本直方图。它将连续变量的取值范围划分为离散的箱子,并显示每个箱子中有多少个值。
sns.displot( data=df, x="Price", kind="hist", aspect=1.4 )
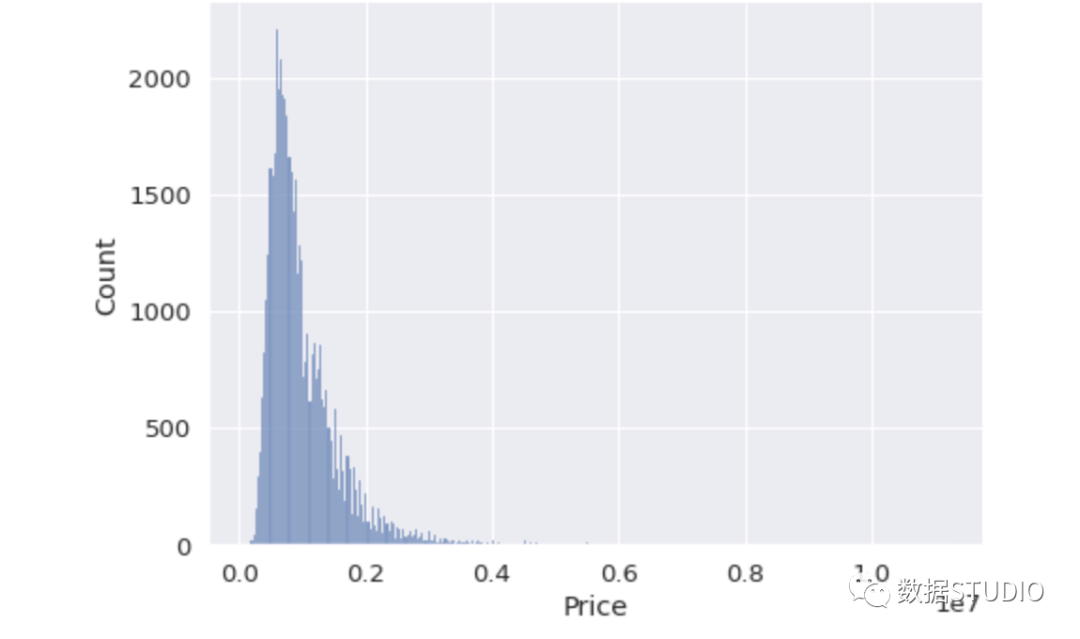
我们将df的名称传递给数据参数。参数x接受要绘制的列名。aspect参数调整大小的宽高比。它也可以改变高度。
示例 2
在第一个例子中,我们可以清楚地看到价格栏中有一些异常值。柱状图在右边有一条长尾,这表明价格非常高的房子很少。
减少这种异常值影响的一种方法是对值取对数。displot函数可以使用log_scale参数执行此操作。
sns.displot( data=df, x="Price", kind="hist", aspect=1.4, log_scale=10 )
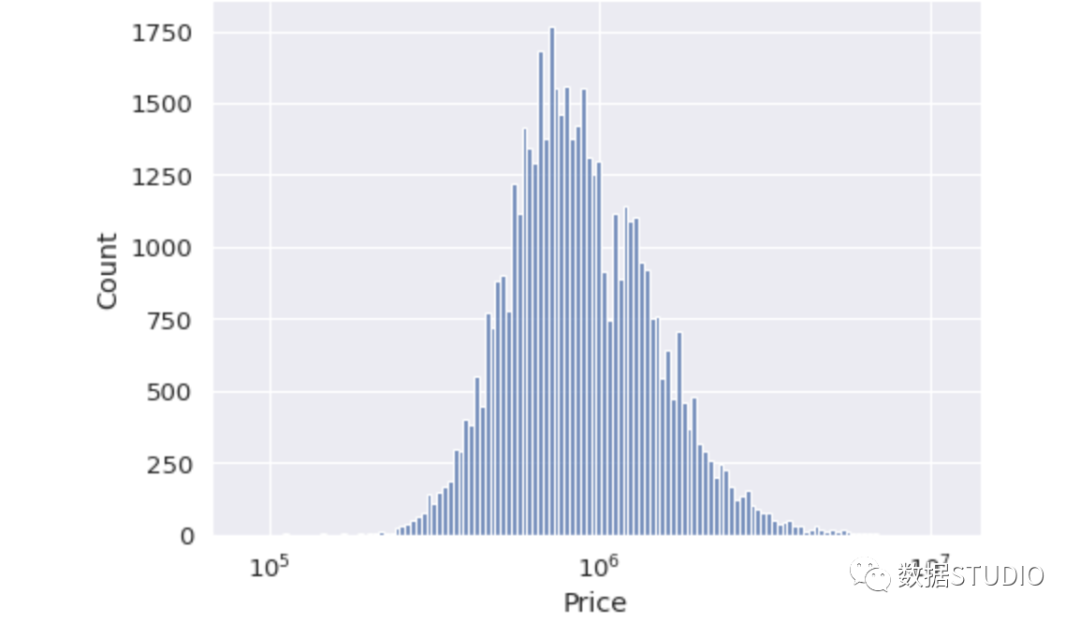
价格以10的幂表示。现在我们对房价的分布有了一个更好的概述。
示例 3
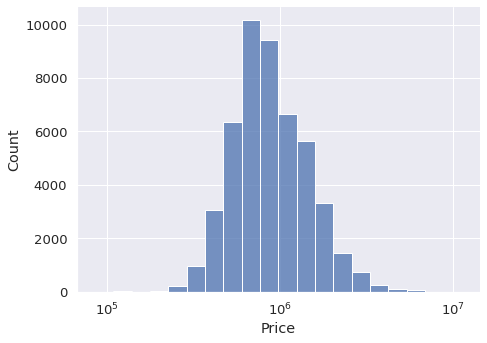
我们还可以调整直方图中的箱数量。在某些情况下,最好使用较少的箱数量,这样我们就可以得到一个更结构化的概述。
用于此调整的参数是box。
sns.displot( data=df, x="Price", kind="hist", aspect=1.4, log_scale=10, bins=20 )
示例 4
数据集还包含分类变量。例如,类型列有3个类别,分别是h(房屋)、t(联排房屋)和u(单位)。我们可能需要分别检查每款的分布情况。
一种选择是在相同的可视化中用不同的颜色显示它们。我们只需要将列的名称传递给hue参数。
sns.displot( data=df, x="Price", hue="Type", kind="hist", aspect=1.4, log_scale=10, bins=20 )
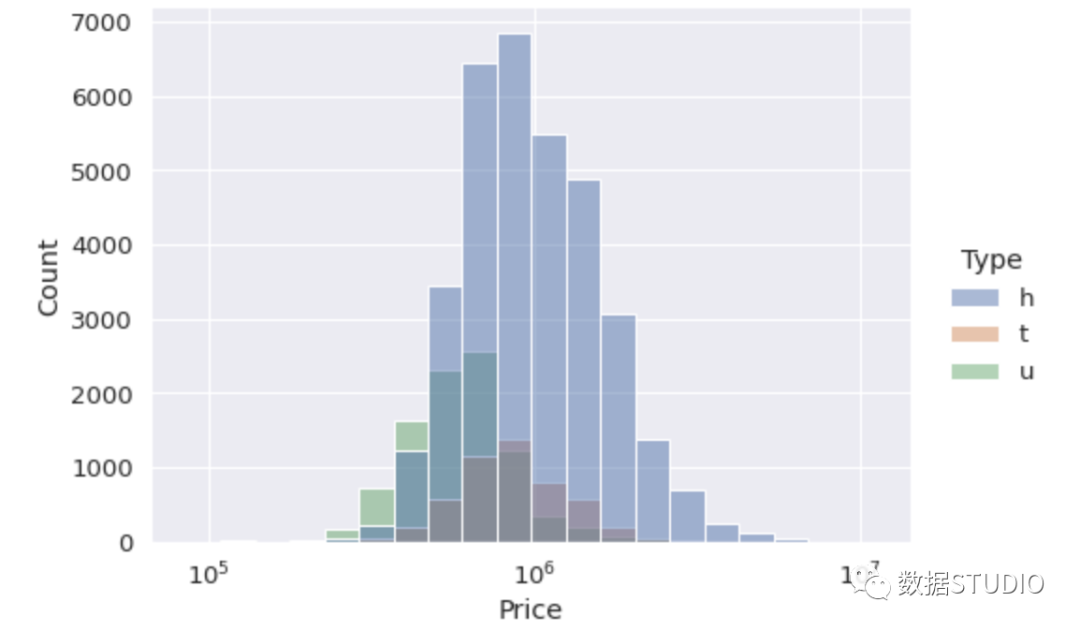
这个图为我们提供了2条信息:
- 每个类别的大小与房屋的数量有关。h类是最大的一类。
- 每类房屋的价格分布。
示例 5
另一个检查每个类别分布的选项是创建单独的子图。我们可以对这个任务使用col或row参数。给定列中的每个类别都有一个子图。
sns.displot( data=df, x="Price", col="Type", kind="hist", aspect=1.4, log_scale=10, bins=20 )
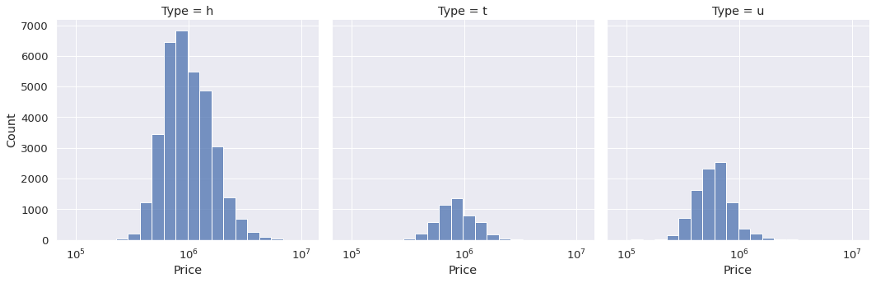
例子 6
displot函数还允许生成二维直方图。因此,我们得到了关于两列中值的观察值(即行)分布的概述。
我们使用价格和距离列创建一个。我们只是将列名传递给x和y参数。
sns.displot( data=df, x="Price", y="Distance", col="Type", kind="hist", height=5, aspect=1.2, log_scale=(10,0), bins=20 )
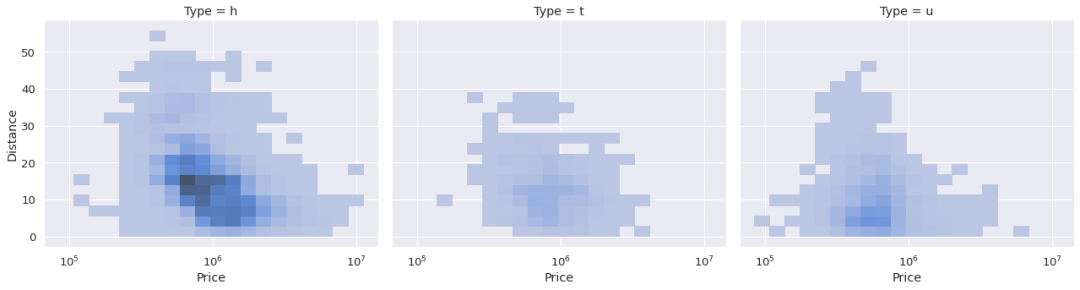
较暗的区域密度更大,所以它们包含了更多的观测数据。两列看起来都是正态分布,因为密集的区域在中心。
你可能已经注意到,我们使用了一个元组作为log_scale参数的参数。因此,我们可以为每个列传递不同的比例。
例子 7
Kde图还可以用于可视化变量的分布。它们和直方图很相似。然而,kde图使用连续的概率密度曲线来表示分布,而不是使用离散的箱。
kind参数设置为“kde”,以生成kde图。
sns.displot( data=df, x="Price", kind="kde", aspect=1.4, log_scale=10 )
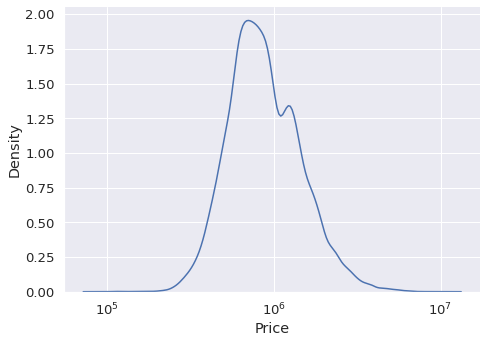
示例 8
与直方图类似,可以为不同的类别分别绘制kde图。我们的数据集包含房屋的区域信息。我们看看不同地区的价格变化。
sns.displot( data=df, x="Price", hue="Regionname", kind="kde", height=6, aspect=1.4, log_scale=10 )
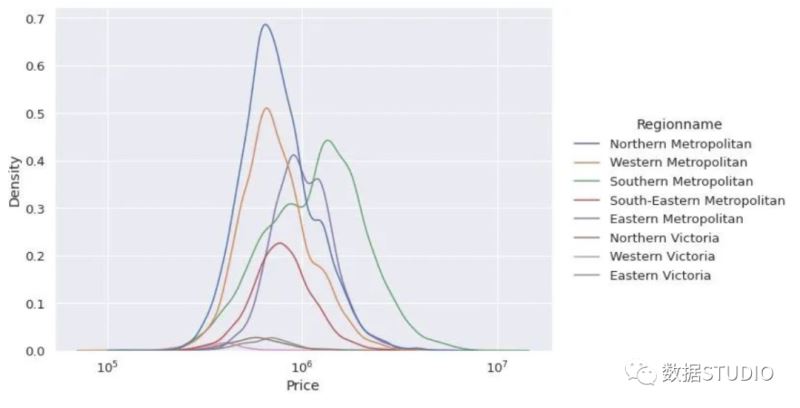
南方大都市区的平均房价似乎最高。
示例 9
另一种检查变量分布的方法是使用ecdf图。它表示低于给定列中每个唯一值的观察值的比例或计数。
这是一种可视化的累计和。因此,我们能够看到更密集的值范围。
sns.displot( data=df, x="Distance", kind="ecdf", height=6, aspect=1.4, stat="count" )
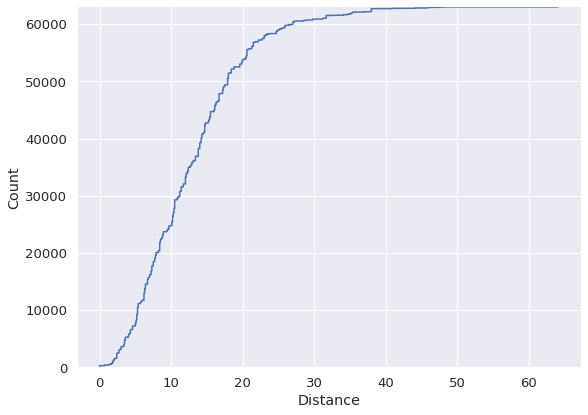
曲线斜率高的值范围有更多的观测值。例如,我们没有很多房子的距离超过30。与此相反,在10到15的距离范围内有很多房子。
示例10
ecdf图也支持hue、col和row参数。因此,我们可以在一个列中区分不同类别之间的分布。
sns.displot( data=df, x="Distance", kind="ecdf", hue="Type", height=6, aspect=1.4, stat="count" )
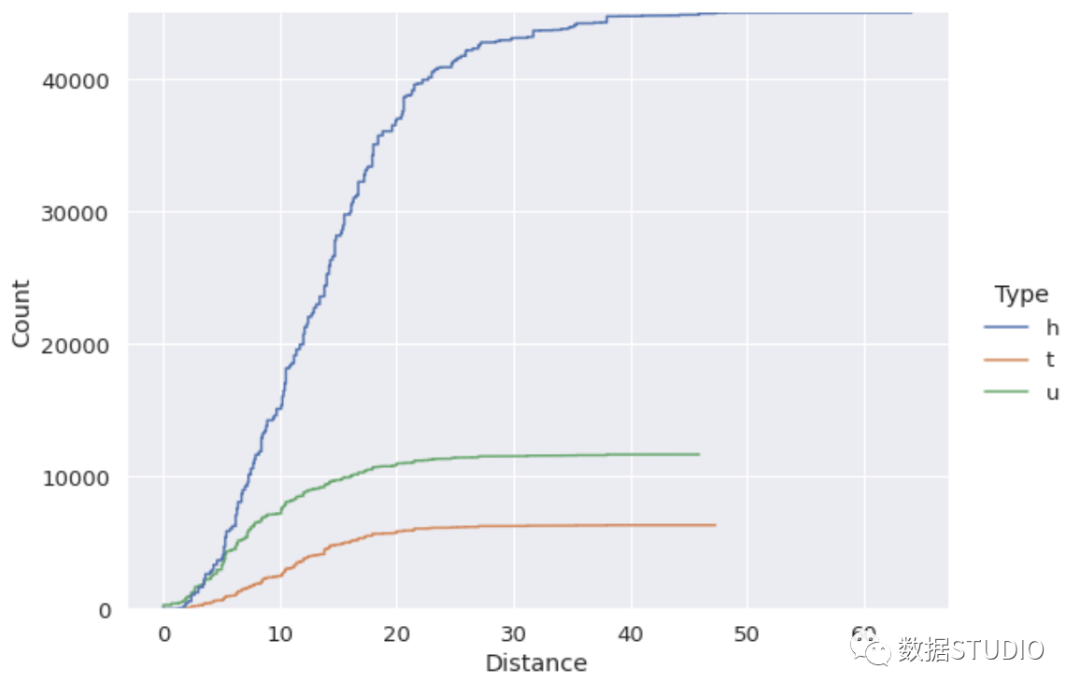
对于数据分析或机器学习任务,了解变量(即特征)的分布是非常重要的。我们如何处理给定的任务可能取决于分布。
在这篇文章中,我们看到了如何使用Seaborn的displot函数来分析价格和距离栏的分布。
加载全部内容