Docker-Compose搭建Spark集群
liedmirror 人气:4一、前言
在前文中,我们使用Docker-Compose完成了hdfs集群的构建。本文将继续使用Docker-Compose,实现Spark集群的搭建。
二、docker-compose.yml
对于Spark集群,我们采用一个mater节点和两个worker节点进行构建。其中,所有的work节点均分配1一个core和 1GB的内存。
Docker镜像选择了bitnami/spark的开源镜像,选择的spark版本为2.4.3,docker-compose配置如下:
master:
image: bitnami/spark:2.4.3
container_name: master
user: root
environment:
- SPARK_MODE=master
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
ports:
- '8080:8080'
- '7077:7077'
volumes:
- ./python:/python
worker1:
image: bitnami/spark:2.4.3
container_name: worker1
user: root
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://master:7077
- SPARK_WORKER_MEMORY=1G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
worker2:
image: bitnami/spark:2.4.3
container_name: worker2
user: root
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://master:7077
- SPARK_WORKER_MEMORY=1G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no在master节点中,也映射了一个/python目录,用于存放pyspark代码,方便运行。
对于master节点,暴露出7077端口和8080端口分别用于连接spark以及浏览器查看spark UI,在spark UI中,集群状态如下图(启动后):
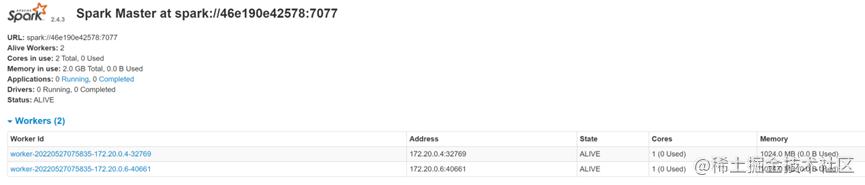
如果有需要,可以自行添加worker节点,其中可以修改SPARK_WORKER_MEMORY与SPARK_WORKER_CORES对节点分配的资源进行修改。
对于该镜像而言,默认exec进去是无用户的,会导致一些安装命令权限的不足,无法安装。例如需要运行pyspark,可能需要安装numpy、pandas等库,就无法使用pip完成安装。而通过user: root就能设置默认用户为root用户,避免上述问题。
三、启动集群
同上文一样,在docker-compose.yml的目录下执行docker-compose up -d命令,就能一键构建集群(但是如果需要用到numpy等库,还是需要自己到各节点内进行安装)。
进入master节点执行spark-shell,成功进入:

四、结合hdfs使用
将上文的Hadoop的docker-compose.yml与本次的结合,得到新的docker-compose.yml:
version: "1.0"
services:
namenode:
image: bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8
container_name: namenode
ports:
- 9870:9870
- 9000:9000
volumes:
- ./hadoop/dfs/name:/hadoop/dfs/name
- ./input:/input
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
datanode:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode
depends_on:
- namenode
volumes:
- ./hadoop/dfs/data:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
resourcemanager:
image: bde2020/hadoop-resourcemanager:2.0.0-hadoop3.2.1-java8
container_name: resourcemanager
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864"
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8
container_name: nodemanager
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:2.0.0-hadoop3.2.1-java8
container_name: historyserver
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
volumes:
- ./hadoop/yarn/timeline:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
master:
image: bitnami/spark:2.4.3-debian-9-r81
container_name: master
user: root
environment:
- SPARK_MODE=master
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
ports:
- '8080:8080'
- '7077:7077'
volumes:
- ./python:/python
worker1:
image: bitnami/spark:2.4.3-debian-9-r81
container_name: worker1
user: root
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://master:7077
- SPARK_WORKER_MEMORY=1G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
worker2:
image: bitnami/spark:2.4.3-debian-9-r81
container_name: worker2
user: root
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://master:7077
- SPARK_WORKER_MEMORY=1G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no运行集群(还需要一个hadoop.env文件见上文)长这样:
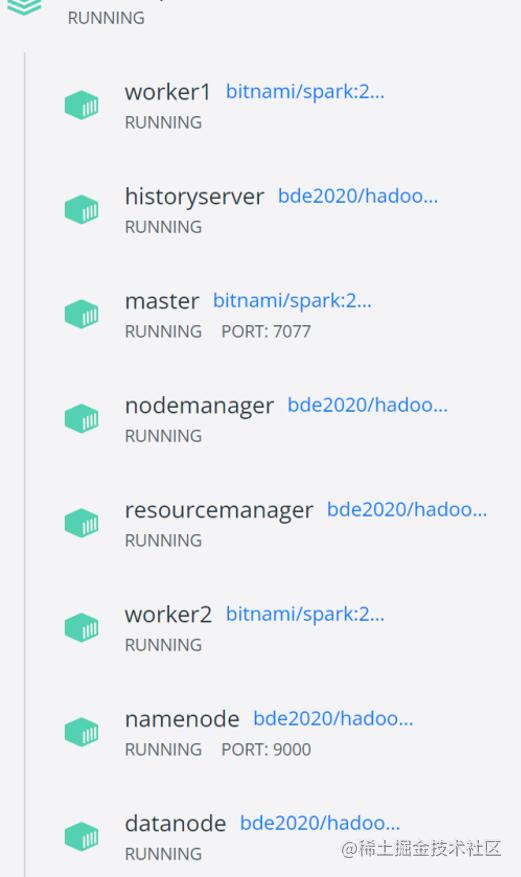
通过Docker容器的映射功能,将本地文件与spark集群的master节点的/python进行了文件映射,编写的pyspark通过映射可与容器中进行同步,并通过docker exec指令,完成代码执行:

运行了一个回归程序,集群功能正常:


加载全部内容