numpy converters和usecols
温欣' 人气:0用Python打开Excel数据,读取时需要将”学号“和“ID"转换成字符,以便后续操作
df = pd.read_excel(path, converters={'学号': str, 'ID': str})

以下是我的经历来体会:
我在从Excel读入python的数据时,发现读出的是空值:
import pandas as pd
df=pd.read_excel("D:/Python/05DataMineML/2022STU(1).xlsx")
df
但是分明是有数据的,大概率出现的原因是sheetname(表的名称)出现了问题。
那就试试其他的方法:
下图是Excel的表头,共有115行数据。

方法一:使用usecols
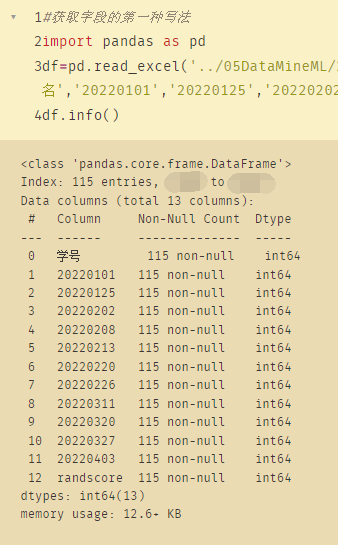
#获取字段的第一种写法
import pandas as pd
df=pd.read_excel('../05DataMineML/2022STU(1).xlsx',usecols=['学号','姓名','20220101','20220125','20220202','20220208','20220213','20220220','20220226','20220311','20220320','20220327','20220403','randscore'],index_col='姓名',sheet_name='2022STUMOOC')
df.info()
index_col:指定作为表格的索引值
usecols:pandas读取excel使用read_excel()中的usecols参数读取指定的列
sheet_name:表名

重点:要使用usecols参数,sheet_name必须显式写出来。
方法二:使用numpy
#获取字段的第二种写法:使用numpy
import pandas as pd
import numpy as np
df=pd.read_excel('../05DataMineML/2022STU(1).xlsx',converters={'学号':str},usecols=np.arange(3,16),index_col='姓名',sheet_name='2022STU')
df.head()
这里就涉及converters:
converters={'学号':str}:将学号转换为字符类型,以便后续操作。
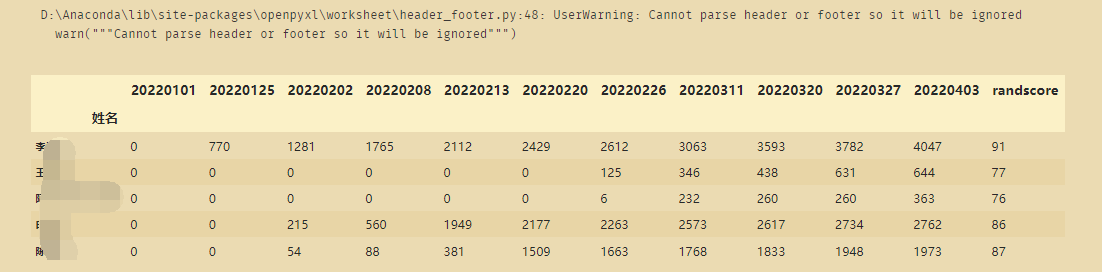
这里使用了usecols=np.arange(3,16)

方法三:使用切片区间
#获取字段的第三种写法:切片区间
import pandas as pd
import numpy as np
df=pd.read_excel('../05DataMineML/2022STUMOOC (1).xlsx',converters={'学号':str},usecols=("D:P"),index_col='姓名',sheet_name='2022STUMOOC')
df
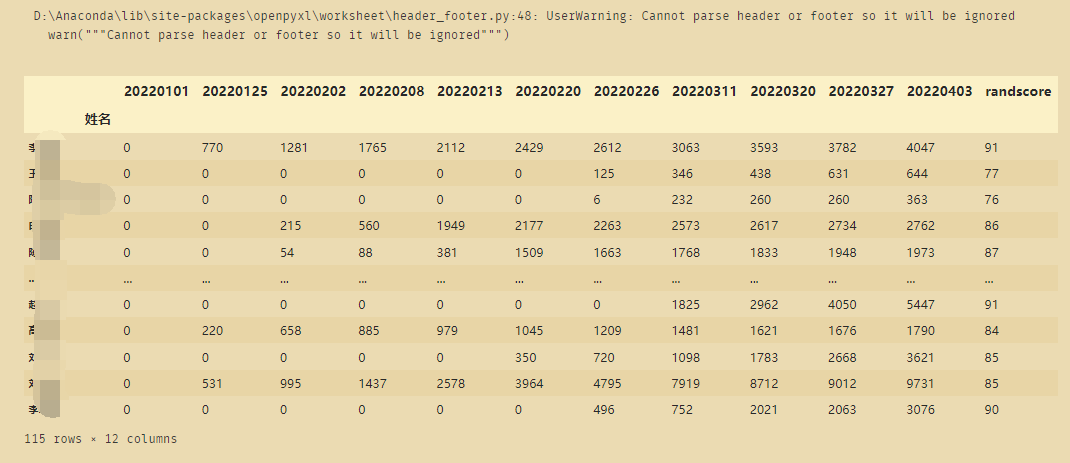
这里使用了usecols=("D:P"),也就是使用了如下图每列的序号值做切片

总结:
converters用法:转换类型。比如将Excel数据一列从int变成str
usecols用法
usecols=[‘学号',‘姓名'] usecols=np.arange(3,16) usecols=(“D:P”)
加载全部内容