Redis内存碎片处理
Java面试365 人气:0Redis内存碎片处理
不知道我们在执行删除操作时有没有注意过这样一个现象,删除一些bigkey后内存分配器分配的容量并没有减少,实际容量减少了,这是为什么呢?演示如下
模拟bigkey删除
创建生成bigkey的脚本文件createdata.sh
#!/bin/bash
cd /opt/redis/redis-6.0.6/bin/
for i in {1..10000}
do
echo "key${i} ${i}"
redis-cli hset obj key${i} ${i}
done赋执行权限
[root@zzf993 redis-6.0.6]# chmod +x createdata.sh ### 执行权限如果分不清可以赋予所有权限 [root@zzf993 redis-6.0.6]# chmod 777 createdata.sh
执行createdata.sh脚本,等待执行完毕
查看内存容量
########## 执行createdata.sh脚本前的内存容量 127.0.0.1:6379> info memory # Memory used_memory:864192 used_memory_human:843.94K used_memory_rss:4681728 used_memory_rss_human:4.46M ########## 执行createdata.sh脚本后的内存容量 # Memory used_memory:1565384 used_memory_human:1.49M used_memory_rss:5992448 used_memory_rss_human:5.71M
将key为obj的键值删除后,查看内存容量
127.0.0.1:6379> info memory # Memory used_memory:896416 used_memory_human:875.41K used_memory_rss:5746688 used_memory_rss_human:5.48M
删除bigkey后used_memory_rss波动很小,而used_memory波动很大,因为used_memory_rss是系统向redis分配的内存空间,而used_memory是redis实际使用的内存空间,上述实验表明redis删除键值后并没有马上的将内存空间回收,所以即使删除了一些bigkey的键值,redis占用的空间依然还是那么大,这些空间后续还会不会使用呢?这个需要分情况
如果删除的键值空间是连续的那么后续新增键值还是可以用来存储数据。
如果删除的键值空间不连续那么这就有可能形成的内存碎片。
那么这些内存碎片能不能重复利用呢?我们可以接着往下面思考。
什么是内存碎片
内存碎片一句话描述就是有那么多内存但是放不下那么多数据,我们以高铁买票为例解释,张三、李四、王五去订票这三个人想订连在一起的三个座位,而最近一趟车有100个座位,已售97个,剩余三个座位并不相邻,那么他们三个只能改换下一趟高铁,因为座位不符合他们的预期,那么这趟车就有三个座位空闲,这就是座位碎片。

将碎片概念放到内存中就是连续空闲的空间放不下那么多数据,如下图,需要向内存中放入一个3字节的数据,虽然内存中存在3字节空闲的内存,但空闲内存不连续所以无法存放,这就是内存碎片
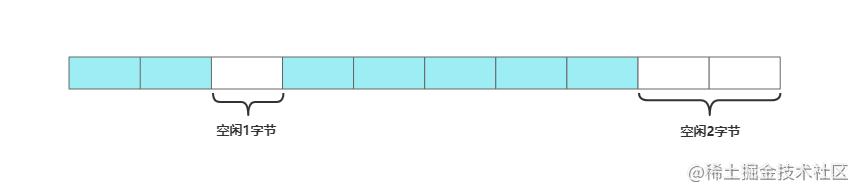
内存碎片如何产生
内存分配器
在Redis中有多种内存分配策略如libc、jemalloc、tcmalloc,默认使用jemalloc,操作系统的内存分配器根据这些分配策略分配内存,但是内存分配器无法做到按需分配,一般按照固定大小分配,以默认分配策略jemalloc为例,一般按照2的整数次幂分配如2、4、8、16、32等等,如redis申请一个6字节的内存,操作系统就会分配一个8字节的内存给redis使用,那么多出来的2个字节空间,如果后续没有其它操作,那么这2个字节就是内存碎片。
那这样分配是不是完全没有优势呢?显然不是,如redis第一次向操作系统申请了24字节的内存,分配器给redis分配了32字节的空间,当下次redis写入需要8字节以内的空间就不需要再次向操作系统申请了,现有的内存空间完全可以满足要求,所以这样的分配方式可以减少向操作系统申请空间分配。
键值大小不同
因为内存分配器不是按需分配,而不同的键值大小也就会给redis带来不一样的碎片,如键值key1占用内存5个字节,键值key2占用内存7个字节,向操作系统申请时都会给分配8个字节,key1键值的碎片就是3个字节,而key2键值的碎片就是1个字节。
键值的操作
键值的修改、删除也会造成碎片如下所示

碎片信息如何查看
碎片信息redis提供了info memory命令给用户监控碎片情况
127.0.0.1:6379> info memory # Memory used_memory:917256 used_memory_human:895.76K used_memory_rss:5488640 used_memory_rss_human:5.23M ....... mem_fragmentation_ratio:6.26
内存信息中mem_fragmentation_ratio指标就是内存的碎片率,碎片率计算如下
mem_fragmentation_ratio = used_memory_rss/used_memory
used_memory_rss:表示是由操作系统分配的内存大小。
used_memory:表示Redis实例占用的内存大小。
如redis向操作系统申请100字节的内存这就是used_memory,操作系统为redis分配128字节的内存这就是used_memory_rss,碎片率就是mem_fragmentation_ratio=1.28。
当mem_fragmentation_ratio<=1.5时,因为操作系统的分配器缘故碎片率避免不了,而且键值的修改,删除也会导致碎片率,所以这算是一个正常范畴。
当mem_fragmentation_ratio>1.5时,相当于碎片率超过了实际占用内存的50%,这就造成了内存的浪费,需要采取一些措施降低碎片率。
注意:如果线上数据显示mem_fragmentation_ratio<1,证明碎片率低,是不是碎片率越低就越好呢?显然不是,碎片率小于1说明used_memory_rss操作系统分配的内存少了,也就是说Redis能使用的物理内存不够了,这就会触发swap,将内存的数据换到磁盘中,后续客户端如果访问了磁盘中的数据将产生延迟。
碎片率如何降低
当Redis版本是4.0以下,那么我们只能通过重启实例解决问题,但需要注意的是重启会有部分数据丢失,即使开启了持久化。
当Redis版本是4.0以上,我们可以通过配置activedefrag yes自动碎片清理来完成,简单形容就是零换整的思想,将空闲内存碎片合并到一起,形成一片连续的空间,如下所示
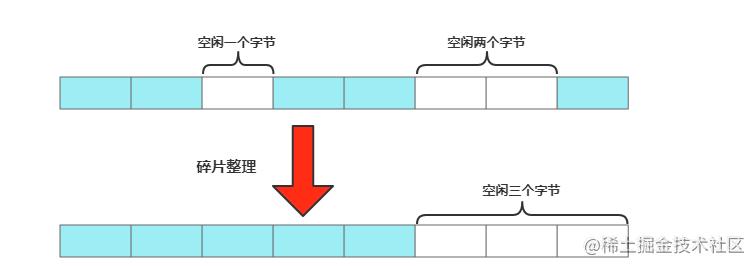
不过万事都有两面性,开启自动碎片清理后,会阻塞主线程,所以需要注意清理参数控制,参数如下
active-defrag-ignore-bytes 100mb:碎片清理的最小碎片内存,碎片内存到达100mb后开始清理。
active-defrag-threshold-lower 10:表示内存碎片空间占分配给redis总空间的10%开始清理和active-defrag-ignore-bytes必须同时满足,有一个不满足停止自动清理。
active-defrag-cycle-min 25:表示碎片清理占用CPU最少的比例,保证碎片清理可以正常运行。
active-defrag-cycle-max 75:表示碎片清理占用CPU最大的比例,不能让碎片清理影响业务正常处理。
如果碎片清理期间阻塞了主线程的业务处理,一般需要将active-defrag-cycle-max占用CPU的最大比例调小。
总结
加载全部内容