python DataFrame groupby()
侯小啾 人气:0groupby()函数
在python的DataFrame中对数据进行分组统计主要使用groupby()函数。
1. groupby基本用法
1.1 一级分类_分组求和
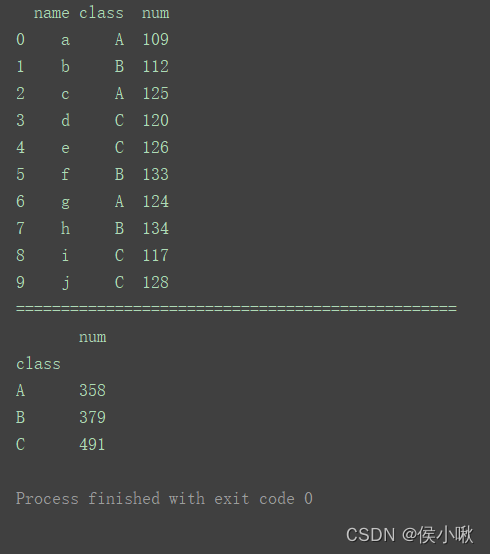
import pandas as pd
data = [['a', 'A', 109], ['b', 'B', 112], ['c', 'A', 125], ['d', 'C', 120],
['e', 'C', 126], ['f', 'B', 133], ['g', 'A', 124], ['h', 'B', 134],
['i', 'C', 117], ['j', 'C', 128]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
columns = ['name', 'class', 'num']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("=================================================")
df1 = df.groupby('class').sum() # 分组统计求和
print(df1)
1.2 二级分类_分组求和
给groupby()传入一个列表,列表中的元素为分类字段,从左到右分类级别增大。(一级分类、二级分类…)
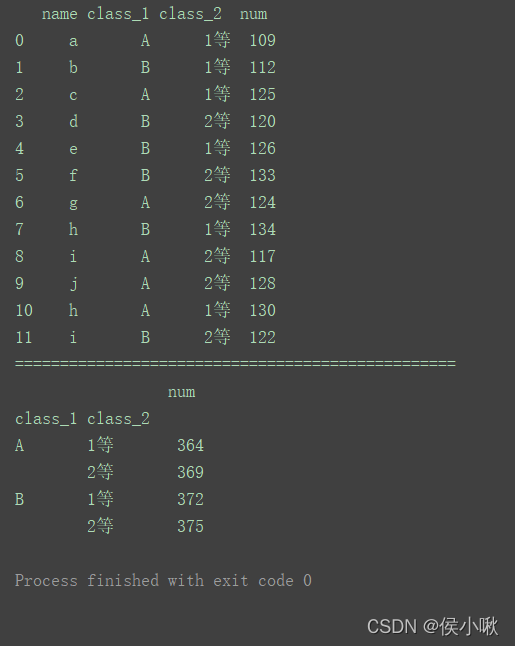
import pandas as pd
data = [['a', 'A', '1等', 109], ['b', 'B', '1等', 112], ['c', 'A', '1等', 125], ['d', 'B', '2等', 120],
['e', 'B', '1等', 126], ['f', 'B', '2等', 133], ['g', 'A', '2等', 124], ['h', 'B', '1等', 134],
['i', 'A', '2等', 117], ['j', 'A', '2等', 128], ['h', 'A', '1等', 130], ['i', 'B', '2等', 122]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("=================================================")
df1 = df.groupby(['class_1', 'class_2']).sum() # 分组统计求和
print(df1)
1.3 对DataFrameGroupBy对象列名索引(对指定列统计计算)
其中,df.groupby(‘class_1’)得到一个DataFrameGroupBy对象,对该对象可以使用列名进行索引,以对指定的列进行统计。
如:df.groupby(‘class_1’)[‘num’].sum()
import pandas as pd
data = [['a', 'A', '1等', 109], ['b', 'B', '1等', 112], ['c', 'A', '1等', 125], ['d', 'B', '2等', 120],
['e', 'B', '1等', 126], ['f', 'B', '2等', 133], ['g', 'A', '2等', 124], ['h', 'B', '1等', 134],
['i', 'A', '2等', 117], ['j', 'A', '2等', 128], ['h', 'A', '1等', 130], ['i', 'B', '2等', 122]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("=================================================")
df1 = df.groupby('class_1')['num'].sum()
print(df1)
代码运行结果同上。
2. 对分组数据进行迭代
2.1 对一级分类的DataFrameGroupBy对象进行遍历
for name, group in DataFrameGroupBy_object
其中,name指分类的类名,group指该类的所有数据。
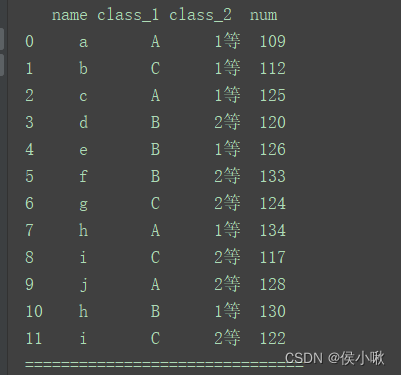
import pandas as pd
data = [['a', 'A', '1等', 109], ['b', 'C', '1等', 112], ['c', 'A', '1等', 125], ['d', 'B', '2等', 120],
['e', 'B', '1等', 126], ['f', 'B', '2等', 133], ['g', 'C', '2等', 124], ['h', 'A', '1等', 134],
['i', 'C', '2等', 117], ['j', 'A', '2等', 128], ['h', 'B', '1等', 130], ['i', 'C', '2等', 122]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("===============================")
# 获取目标数据。
df1 = df[['name', 'class_1', 'num']]
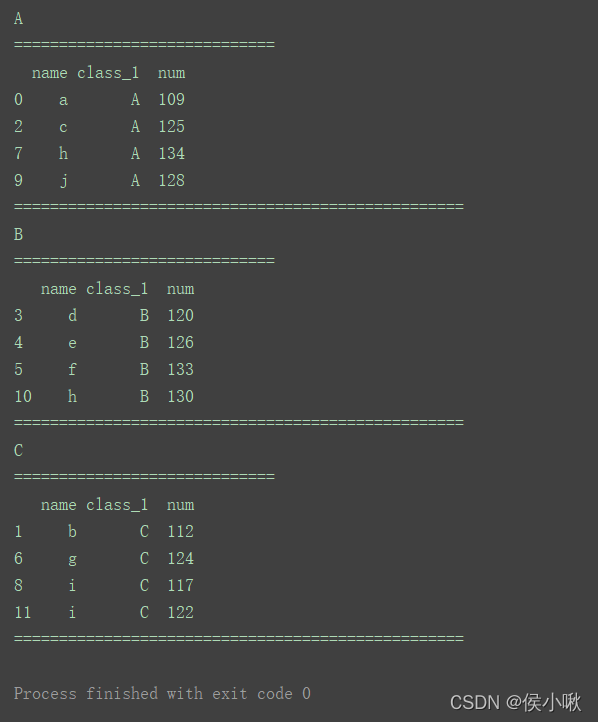
for name, group in df1.groupby('class_1'):
print(name)
print("=============================")
print(group)
print("==================================================")
2.2 对二级分类的DataFrameGroupBy对象进行遍历
对二级分类的DataFrameGroupBy对象进行遍历,
以for (key1, key2), group in df.groupby([‘class_1’, ‘class_2’]) 为例
不同于一级分类的是, (key1, key2)是一个由多级类别组成的元组,而group表示该多级分类类别下的数据。
import pandas as pd
data = [['a', 'A', '1等', 109], ['b', 'C', '1等', 112], ['c', 'A', '1等', 125], ['d', 'B', '2等', 120],
['e', 'B', '1等', 126], ['f', 'B', '2等', 133], ['g', 'C', '2等', 124], ['h', 'A', '1等', 134],
['i', 'C', '2等', 117], ['j', 'A', '2等', 128], ['h', 'B', '1等', 130], ['i', 'C', '2等', 122]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("===============================")
for (key1, key2), group in df.groupby(['class_1', 'class_2']):
print(key1, key2)
print("=============================")
print(group)
print("==================================================")
程序运行结果如下:
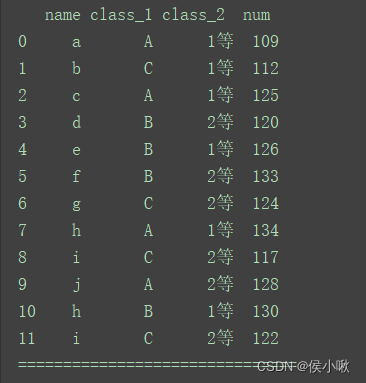
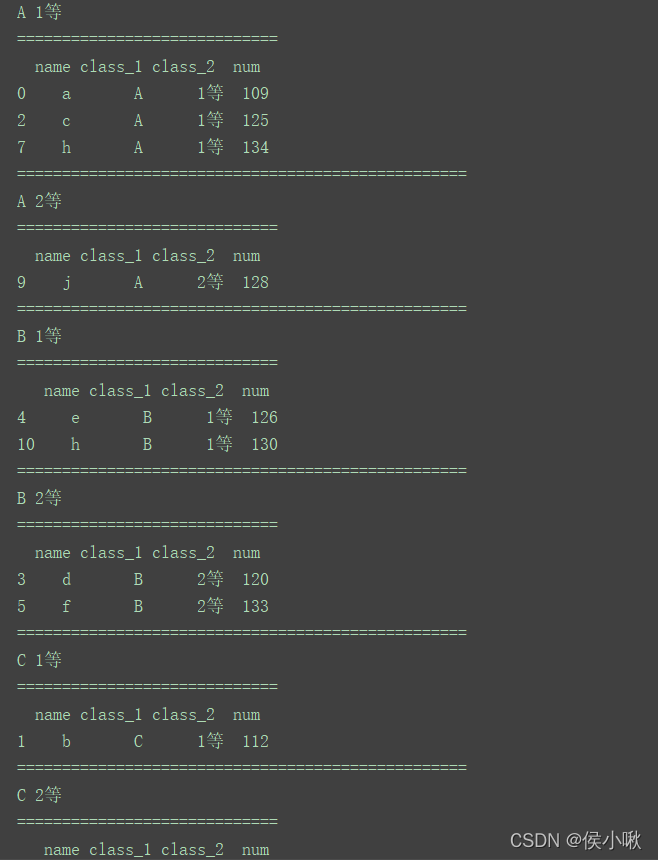
(部分)
3. agg()函数
使用groupby()函数和agg()函数 实现 分组聚合操作运算。
3.1一般写法_对目标数据使用同一聚合函数
以 分组求均值、求和 为例
给agg()传入一个列表
df1.groupby([‘class_1’, ‘class_2’]).agg([‘mean’, ‘sum’])
import pandas as pd
data = [['a', 'A', '1等', 109, 144], ['b', 'C', '1等', 112, 132], ['c', 'A', '1等', 125, 137], ['d', 'B', '2等', 120, 121],
['e', 'B', '1等', 126, 136], ['f', 'B', '2等', 133, 127], ['g', 'C', '2等', 124, 126], ['h', 'A', '1等', 134, 125],
['i', 'C', '2等', 117, 125], ['j', 'A', '2等', 128, 133], ['h', 'B', '1等', 130, 122], ['i', 'C', '2等', 122, 111]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num1', 'num2']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("===============================")
df1 = df[['class_1', 'class_2', 'num1', 'num2']]
print(df1.groupby(['class_1', 'class_2']).agg(['mean', 'sum']))
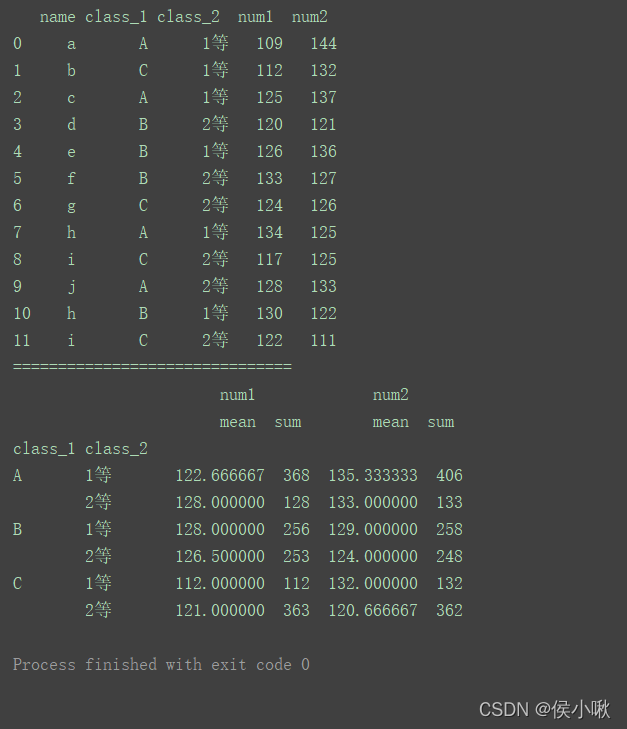
3.2 对不同列使用不同聚合函数
给agg()方法传入一个字典
import pandas as pd
data = [['a', 'A', '1等', 109, 144], ['b', 'C', '1等', 112, 132], ['c', 'A', '1等', 125, 137], ['d', 'B', '2等', 120, 121],
['e', 'B', '1等', 126, 136], ['f', 'B', '2等', 133, 127], ['g', 'C', '2等', 124, 126], ['h', 'A', '1等', 134, 125],
['i', 'C', '2等', 117, 125], ['j', 'A', '2等', 128, 133], ['h', 'B', '1等', 130, 122], ['i', 'C', '2等', 122, 111]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num1', 'num2']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("===============================")
df1 = df[['class_1', 'num1', 'num2']]
print(df1.groupby('class_1').agg({'num1': ['mean', 'sum'], 'num2': ['sum']}))
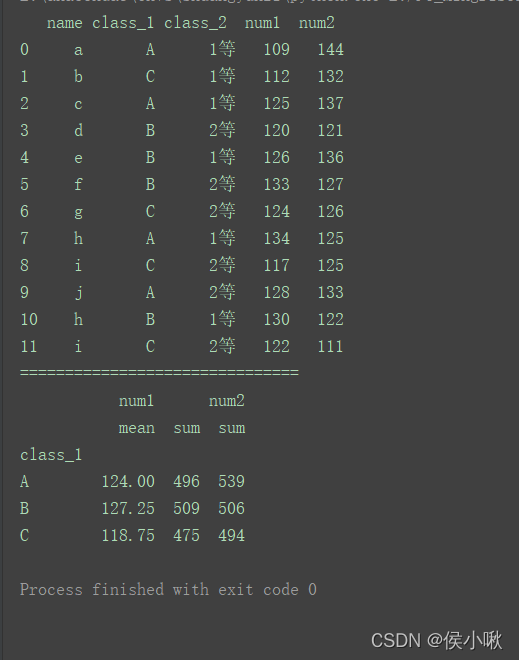
3.3 自定义函数写法
也可以自定义一个函数(以名为max1为例)传入agg()中。
import pandas as pd
data = [['a', 'A', '1等', 109, 144], ['b', 'C', '1等', 112, 132], ['c', 'A', '1等', 125, 137], ['d', 'B', '2等', 120, 121],
['e', 'B', '1等', 126, 136], ['f', 'B', '2等', 133, 127], ['g', 'C', '2等', 124, 126], ['h', 'A', '1等', 134, 125],
['i', 'C', '2等', 117, 125], ['j', 'A', '2等', 128, 133], ['h', 'B', '1等', 130, 122], ['i', 'C', '2等', 122, 111]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num1', 'num2']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("===============================")
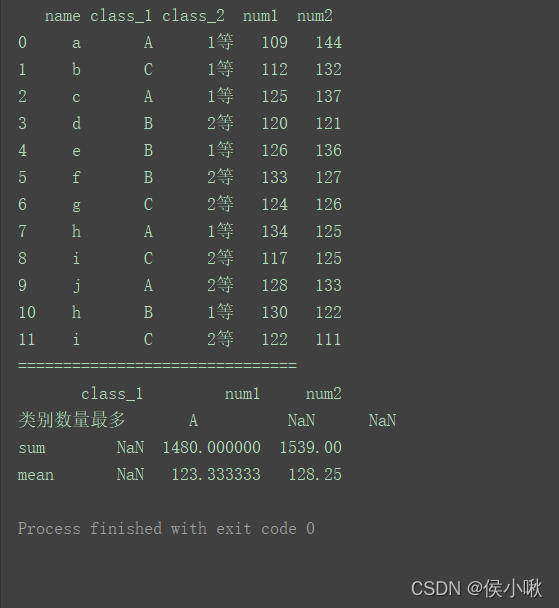
max1 = lambda x: x.value_counts(dropna=False).index[0]
max1.__name__ = "类别数量最多"
df1 = df.agg({'class_1': [max1],
'num1': ['sum', 'mean'],
'num2': ['sum', 'mean']})
print(df1)
4. 通过 字典 和 Series 对象进行分组统计
groupy()不仅仅可以传入单个列,或多个列组成的列表,
也可以传入一个字典或者一个Series来实现分组。
4.1通过一个字典
import pandas as pd
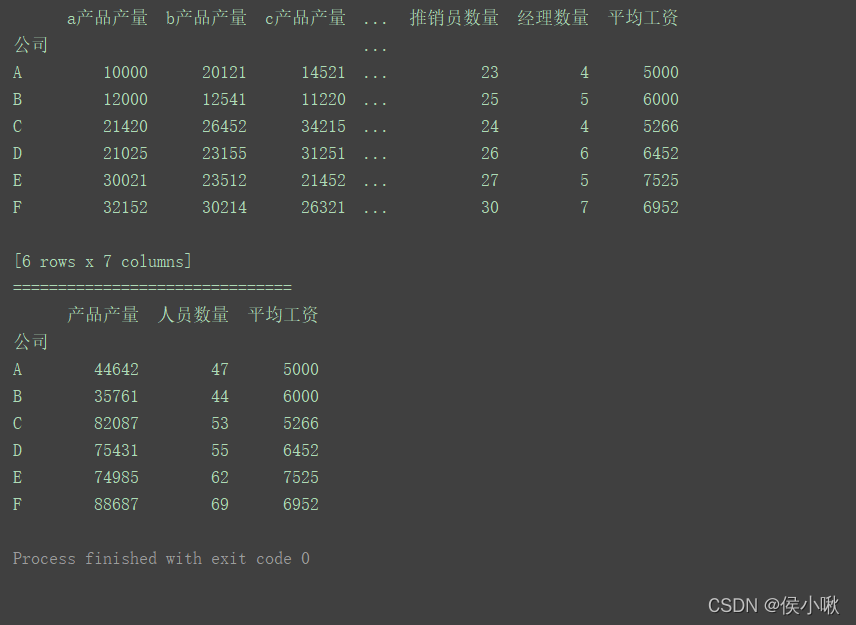
data = [['A', 10000, 20121, 14521, 20, 23, 4, 5000],
['B', 12000, 12541, 11220, 14, 25, 5, 6000],
['C', 21420, 26452, 34215, 25, 24, 4, 5266],
['D', 21025, 23155, 31251, 23, 26, 6, 6452],
['E', 30021, 23512, 21452, 30, 27, 5, 7525],
['F', 32152, 30214, 26321, 32, 30, 7, 6952]]
columns = ['公司', 'a产品产量', 'b产品产量', 'c产品产量', '搬运工数量', '推销员数量', '经理数量', '平均工资']
pd.set_option('display.unicode.east_asian_width', True)
df = pd.DataFrame(data=data, columns=columns)
df = df.set_index(['公司'])
print(df)
print("===============================")
mapping = {
'a产品产量': '产品产量', 'b产品产量': '产品产量',
'c产品产量': '产品产量', '搬运工数量': '人员数量',
'推销员数量': '人员数量', '经理数量': '人员数量',
'平均工资': '平均工资'
}
df1 = df.groupby(mapping, axis=1).sum()
print(df1)
程序运行结果:
4.2通过一个Series
import pandas as pd
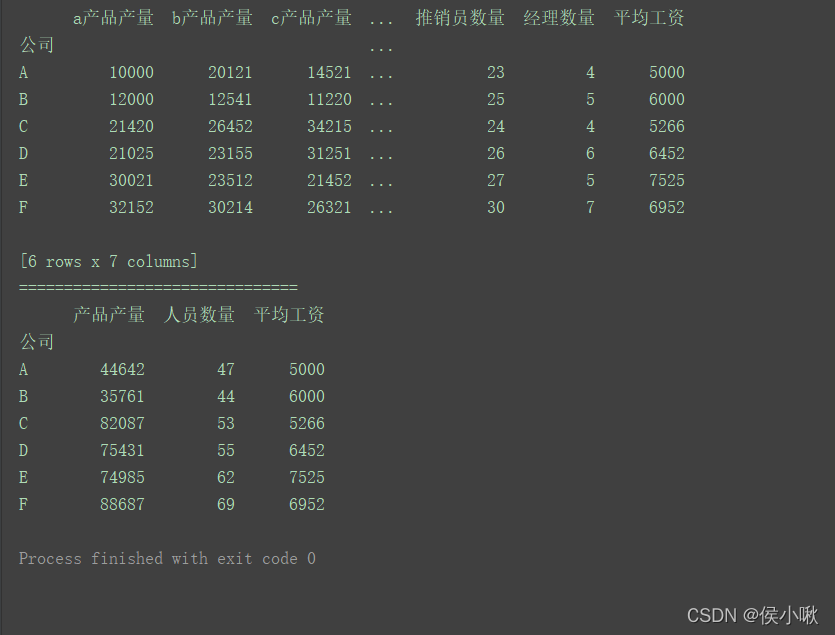
data = [['A', 10000, 20121, 14521, 20, 23, 4, 5000],
['B', 12000, 12541, 11220, 14, 25, 5, 6000],
['C', 21420, 26452, 34215, 25, 24, 4, 5266],
['D', 21025, 23155, 31251, 23, 26, 6, 6452],
['E', 30021, 23512, 21452, 30, 27, 5, 7525],
['F', 32152, 30214, 26321, 32, 30, 7, 6952]]
columns = ['公司', 'a产品产量', 'b产品产量', 'c产品产量', '搬运工数量', '推销员数量', '经理数量', '平均工资']
pd.set_option('display.unicode.east_asian_width', True)
df = pd.DataFrame(data=data, columns=columns)
df = df.set_index(['公司'])
print(df)
print("===============================")
data = {
'a产品产量': '产品产量', 'b产品产量': '产品产量',
'c产品产量': '产品产量', '搬运工数量': '人员数量',
'推销员数量': '人员数量', '经理数量': '人员数量',
'平均工资': '平均工资'
}
s1 = pd.Series(data)
df1 = df.groupby(s1, axis=1).sum()
print(df1)
程序运行结果:
参考资源: python数据分析从入门到精通 明日科技编著 清华大学出版社
加载全部内容