Go rune 类型
技术颜良 人气:0刚接触 Go 语言时,就听说有一个叫rune的数据类型,即使查阅过一些资料,对它的理解依旧比较模糊,加之对陌生事物的天然排斥,在之后很长一段时间的编程工作中,我都没有让它出现在我的代码里。
逃避虽然有用,但是似乎有些可耻,想要成为一名成熟、优秀的 Go 语言开发工程师,必须要有直面陌生事物并且成功运用的勇气和能力,带着这样的觉悟,让我们一起走近rune,直视它!
了解一下,rune类型究竟是什么?
rune类型是 Go 语言的一种特殊数字类型。在builtin/builtin.go文件中,它的定义:type rune = int32;官方对它的解释是:rune是类型int32的别名,在所有方面都等价于它,用来区分字符值跟整数值。使用单引号定义 ,返回采用 UTF-8 编码的 Unicode 码点。Go 语言通过rune处理中文,支持国际化多语言。
众所周知,Go 语言有两种类型声明方式:一种叫类型定义声明,另一种叫类型别名声明。其中,别名的使用在大型项目重构中作用最为明显,它能解决代码升级或迁移过程中可能存在的类型兼容性问题。而rune跟byte是 Go 语言中仅有的两个类型别名,专门用来处理字符。当然,我们也可以通过type关键字加等号的方式声明更多的类型别名。
学习一下,rune类型怎么用?
我们知道,字符串由字符组成,字符的底层由字节组成,而一个字符串在底层的表示是一个字节序列。在 Go 语言中,字符可以被分成两种类型处理:对占 1 个字节的英文类字符,可以使用byte(或者unit8);对占 1 ~ 4 个字节的其他字符,可以使用rune(或者int32),如中文、特殊符号等。
下面,我们通过示例应用来具体感受一下。
统计带中文字符串长度
// 使用内置函数 len() 统计字符串长度
fmt.Println(len("Go语言编程")) // 输出:14 前面说到,字符串在底层的表示是一个字节序列。其中,英文字符占用 1 字节,中文字符占用 3 字节,所以得到的长度 14 显然是底层占用字节长度,而不是字符串长度,这时,便需要用到rune类型。
// 转换成 rune 数组后统计字符串长度
fmt.Println(len([]rune("Go语言编程"))) // 输出:6这回对了。很容易,我们解锁了rune类型的第一个功能,即统计字符串长度。
- 截取带中文字符串
如果想要截取字符串中 ”Go语言“ 这一段,考虑到底层是一个字节序列,或者说是一个数组,通常情况下,我们会这样:
s := "Go语言编程" // 8=2*1+2*3 fmt.Println(s[0:8]) // 输出:Go语言
结果符合预期。但是,按照字节的方式进行截取,必须预先计算出需要截取字符串的字节数,如果字节数计算错误,就会显示乱码,比如这样:
s := "Go语言编程" fmt.Println(s[0:7]) // 输出:Go语�
此外,如果截取的字符串较长,那通过字节的方式进行截取显然不是一个高效准确的办法。那有没有不用计算字节数,简单又不会出现乱码的方法呢?不妨试试这样:
s := "Go语言编程" // 转成 rune 数组,需要几个字符,取几个字符 fmt.Println(string([]rune(s)[:4])) // 输出:Go语言
到这里,我们解锁了rune类型的第二个功能,即截取字符串。
思考一下,为什么rune类型可以做到?
通过上面的示例,我们发现似乎在处理带中文的字符串时,都需要用到rune类型,这究竟是为什么呢?除了使用rune类型,还有其他方法吗?
在深入思考之前,我们需要首先弄清楚string、byte、rune三者间的关系。
字符串在底层的表示是由单个字节组成的一个不可修改的字节序列,字节使用UTF-8[1]编码标识Unicode[2]文本。Unicode 文本意味着.go文件内可以包含世界上的任意语言或字符,该文件在任意系统上打开都不会乱码。UTF-8 是 Unicode 的一种实现方式,是一种针对 Unicode 可变长度的字符编码,它定义了字符串具体以何种方式存储在内存中。UFT-8 使用 1 ~ 4 为每个字符编码。
Go 语言把字符分byte和rune两种类型处理。byte是类型unit8的别名,用于存放占 1 字节的 ASCII 字符,如英文字符,返回的是字符原始字节。rune是类型int32的别名,用于存放多字节字符,如占 3 字节的中文字符,返回的是字符 Unicode 码点值。如下图所示:
s := "Go语言编程" // byte fmt.Println([]byte(s)) // 输出:[71 111 232 175 173 232 168 128 231 188 150 231 168 139] // rune fmt.Println([]rune(s)) // 输出:[71 111 35821 35328 32534 31243]
它们的对应关系如下图:
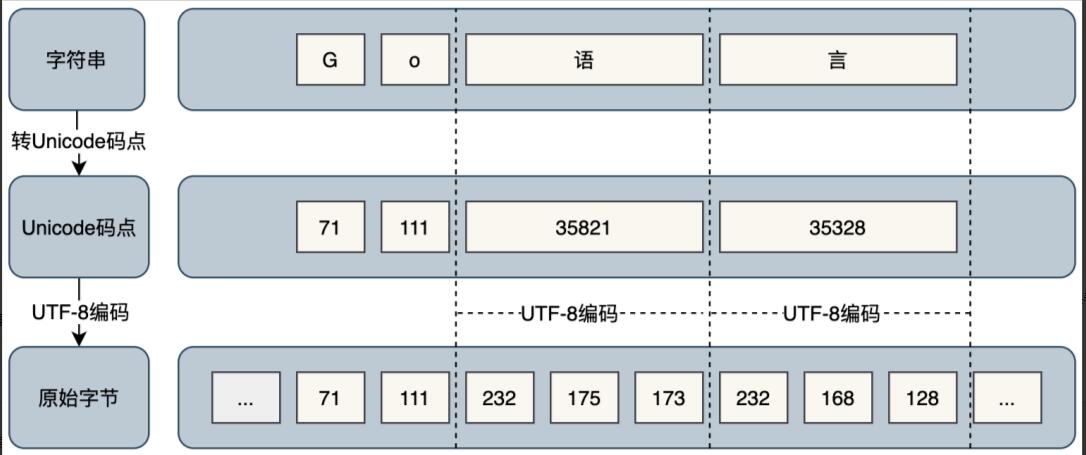
了解了这些,我们再回过来看看,刚才的问题是不是清楚明白很多?接下来,让我们再来看看源码中是如何处理的,以utf8.RuneCountInString()[3]函数为例。
示例:
// 统计字符串长度
fmt.Println(utf8.RuneCountInString("Go语言编程")) // 输出:6源码:
// RuneCountInString is like RuneCount but its input is a string.
func RuneCountInString(s string) (n int) {
// 调用 len() 函数得到字节数
ns := len(s)
for i := 0; i < ns; n++ {
c := s[i]
// 如码点值小于 128,则为占 1 字节的 ASCII 字符(或者说英文字符),长度 + 1
if c < RuneSelf { // RuneSelf = 128
// ASCII fast path
i++
continue
}
// 查询首字节信息表,得到中文占 3 字节,所以这里的 x = 3
x := first[c]
// 判断 x = 3,xx = 241(0xF1)
if x == xx {
i++ // invalid.
continue
}
// 提取有效的 UTF-8 字节长度编码信息,size = 3
size := int(x & 7)
if i+size > ns {
i++ // Short or invalid.
continue
}
// 提取有效字节范围
accept := acceptRanges[x>>4]
// accept.lo,accept.hi,表示 UTF-8 中第二字节的有效范围
// locb = 0b10000000,表示 UTF-8 编码非首字节的数值下限
// hicb = 0b10111111,表示 UTF-8 编码非首字节的数值上限
if c := s[i+1]; c < accept.lo || accept.hi < c {
size = 1
} else if size == 2 {
} else if c := s[i+2]; c < locb || hicb < c {
size = 1
} else if size == 3 {
} else if c := s[i+3]; c < locb || hicb < c {
size = 1
}
i += size
}
return n
}调用该函数时,传入一个原始的字符串,代码会根据每个字符的码点大小判断是否为 ASCII 字符,如果是,则算做 1 位;如果不是,则查询首字节表,明确字符占用的字节数,验证有效性后再进行计数。
小小总结
在我看来,rune类型只是一种名称叫法,表示用来处理长度大于 1 字节( 8 位)、不超过 4 字节( 32 位)的字符类型。但万变不离其宗,我们使用函数时,无论传入参数的是原始字符串还是rune,最终都是对字节进行处理。看似陌生的事物,沉下心了解到其本质以后,才发现原来并不陌生,缺少的只是正视它的勇气!
[1]
UTF-8:https://zh.wikipedia.org/wiki/UTF-8
[2]
Unicode:https://zh.wikipedia.org/wiki/Unicode
[3]
utf8.RuneCountInString():https://golang.org/src/unicode/utf8/utf8.go
加载全部内容