MySQL创建测试数据表
涛姐涛哥 人气:0一、数据插入思路
如果一条一条插入普通表的话,效率太低下,但内存表插入速度是很快的,可以先建立一张内存表,插入数据后,在导入到普通表中。
1、创建内存表
View Code
2、创建普通表
普通表参数设置和内存表相同,否则从内存表往普通标导入数据会报错。
View Code
3、创建存储函数
产生伪随机码user_id 要用到存储函数。
View Code
4、创建存储过程
存储过程是保存起来的可以接受和返回用户提供的参数的Transact-SQL 语句的集合,可以创建一个过程供永久使用。
View Code
5、调用存储过程
call 就是调用存储过程或者函数,这里调用存储过程1000000次
CALL add_vote_memory(1000000)
6、导入数据
将内存表中的数据导入普通表。
INSERT into vote_record SELECT * from vote_record_memory
7、内存不足
如果报错内存满了,报错信息如下:
CALL add_vote_memory(1000000) > 1114 - The table 'vote_record_memory' is full > 时间: 74.61s
则可以使用命令查看内存表和临时表允许写入的最大值:
show variables like '%%table_size%'
MySQL默认16M:
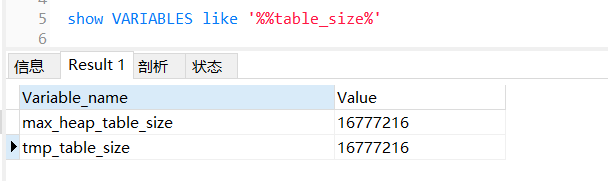
修改默认内存配置:
set session tmp_table_size=1024*1024*1024; set session max_heap_table_size=1024*1024*1024;
配置修改后,再执行上述调用存储过程和数据导入步骤。
8、查看结果
查看记录,是否有插入100W条数据。
select count(*) AS total from vote_record

9、插入800W条数据
测试插入800W条数据,call 调用存储过程800W次。
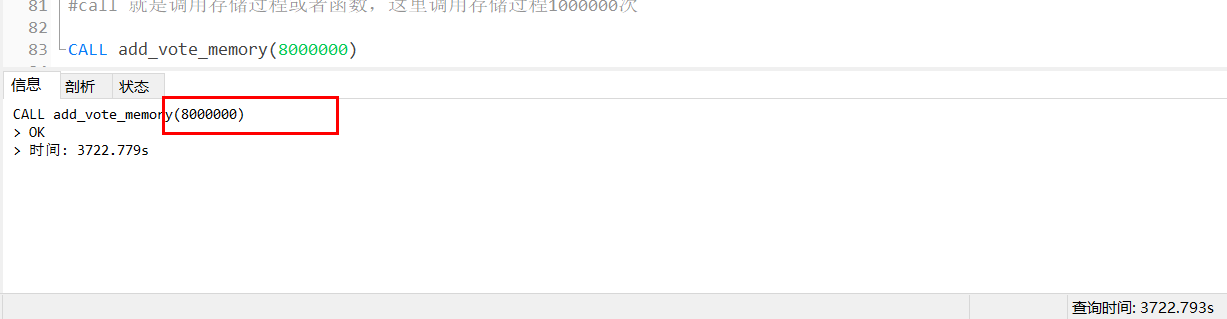
查看结果:

800W条测试数据插入OK,想插入多少条测试数据就调用n次存储过程,CALL add_vote_memory(n)。
二、MySQL深度分页
所谓的深度分页问题,涉及到mysql分页的原理。通常情况下,mysql的分页是这样写的:
select id, user_id, vote_id, group_id from vote_record limit 200, 10
SQL意思就是从vote_reccord 表里查200到210这10条数据即【201,210】,mysql会把前210条数据都查出来,抛弃前200条,返回10条。当分页所以深度不大的时候当然没问题,随着分页的深入,sql可能会变成这样:
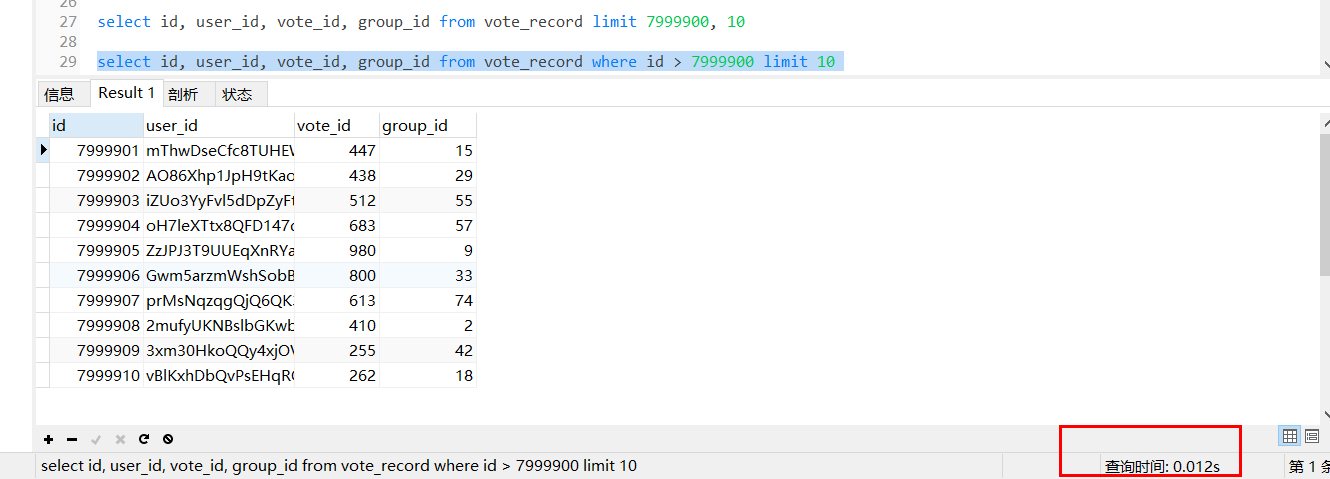
select id, user_id, vote_id, group_id from vote_record limit 7999900, 10
这个时候,mysql会查出来7999920条数据,抛弃前7999900条,如此大的数据量,速度一定快不起来。
那如何解决呢?一般情况下,最简单的方式是增加一个条件,利用表的覆盖索引来加速分页查询:
select id, user_id, vote_id, group_id from vote_record where id > 7999900 limit 10
我们都知道,利用了索引查询的语句中如果只包含了那个索引列(覆盖索引),那么这种情况会查询很快。
因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。上述vote_record 表的id字段是主键,自然就包含了默认的主键索引,这样,mysql会走主键索引,直接连接到7999900处,然后查出来10条数据。但是这个方式需要接口的调用方配合改造,把上次查询出来的最大id以参数的方式传给接口提供方,会有一定沟通成本。
1、测试深度分页
优化前,查询耗时2.362s,随着数据的增大耗时会更多,limit语句的查询时间与起始记录的位置成正比。

优化后,耗时0.012s,性能提升了196.8倍。
加载全部内容