PyTorch数据读取
SherlockLiao 人气:0前言
很多前人曾说过,深度学习好比炼丹,框架就是丹炉,网络结构及算法就是单方,而数据集则是原材料,为了能够炼好丹,首先需要一个使用称手的丹炉,同时也要有好的单方和原材料,最后就需要炼丹师们有着足够的经验和技巧掌握火候和时机,这样方能炼出绝世好丹。
对于刚刚进入炼丹行业的炼丹师,网上都有一些前人总结的炼丹技巧,同时也有很多炼丹师的心路历程以及丹师对整个炼丹过程的记录,有了这些,无疑能够非常快速知道如何炼丹。但是现在市面上的入门炼丹手册往往都是将原材料帮你放到了丹炉中,你只需要将丹炉开启,然后进行简单的调试,便能出丹。这样做无疑减少了大家入门的难度,但是往往到了自己真正炼丹的时候便会手足无措,不知道如何将原材料放入丹炉。
本篇炼丹入门指导便是使用PyTorch这个丹炉,教你如何将原材料放入丹炉,虽然这一步并不涉及太多算法,但是却是炼丹开始非常重要的一步。
PyTorch数据读入函数介绍
ImageFolder
在PyTorch中有一个现成实现的数据读取方法,是torchvision.datasets.ImageFolder,这个api是仿照keras写的,主要是做分类问题,将每一类数据放到同一个文件夹中,比如有10个类别,那么就在一个大的文件夹下面建立10个子文件夹,每个子文件夹里面放的是同一类的数据。
通过这个函数能够很简单的建立一个数据I/O,但是问题来了,如果我要处理的数据不是这样一个简单的分类问题,比如我要做机器翻译,那么我的输入和输出都是一个句子,这样该怎么进行数据读入呢?
这个问题非常容易解决,我们可以看看ImageFolder的实现,可以发现其是torch.utils.data.Dataset的子类,所以下面我们介绍一下torch.utils.data.Dataset这个类。
Dataset
我们可以发现Dataset的定义是下面这样

这里注释是说这是一个代表着数据集的抽象类,所有关于数据集的类都可以定义为其子类,只需要重写__getitem__和__len__就可以了。我们再回去看看ImageFolder的实现,确实是这样的,那么现在问题就变得很简单,对于机器翻译问题,我们只需要定义整个数据集的长度,同时定义取出其中一个索引的元素即可。
那么定义好了数据集我们不可能将所有的数据集都放到内存,这样内存肯定就爆了,我们需要定义一个迭代器,每一步产生一个batch,这里PyTorch已经为我们实现好了,就是下面的torch.utils.data.DataLoader。
DataLoader
DataLoader能够为我们自动生成一个多线程的迭代器,只要传入几个参数进行就可以了,第一个参数就是上面定义的数据集,后面几个参数就是batch size的大小,是否打乱数据,读取数据的线程数目等等,这样一来,我们就建立了一个多线程的I/O。
读到这里,你可能觉得PyTorch真的太方便了,这个丹炉真的好用,然后便迫不及待的尝试了一下,然后有可能性就报错了,而且你也是一步一步按着实现来的,怎么就报错了呢?不用着急,下面就来讲一下为什么会报错,以及这一块pyhon实现的解读,这样你就能够真正知道如何进行自定义的数据读入。
问题来源
通过上面的实现,可能会遇到各种不同的问题,Dataset非常简单,一般都不会有错,只要Dataset实现正确,那么问题的来源只有一个,那就是torch.utils.data.DataLoader中的一个参数collate_fn,这里我们需要找到DataLoader的源码进行查看这个参数到底是什么。
可以看到collate_fn默认是等于default_collate,那么这个函数的定义如下。

是不是看着有点头大,没有关系,我们先搞清楚他的输入是什么。这里可以看到他的输入被命名为batch,但是我们还是不知道到底是什么,可以猜测应该是一个batch size的数据。我们继续往后找,可以找到这个地方。
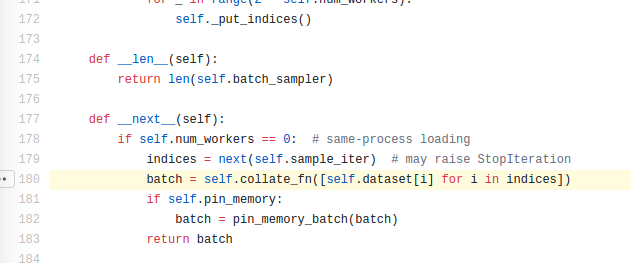
我们可以从这里看到collate_fn在这里进行了调用,那么他的输入我们就找到了,从这里看这就是一个list,list中的每个元素就是self.data[i],如果你在往上看,可以看到这个self.data就是我们需要预先定义的Dataset,那么这里self.data[i]就等价于我们在Dataset里面定义的__getitem__这个函数。
所以我们知道了collate_fn这个函数的输入就是一个list,list的长度是一个batch size,list中的每个元素都是__getitem__得到的结果。
这时我们再去看看collate_fn这个函数,其实可以看到非常简单,就是通过对一些情况的排除,然后最后输出结果,比如第一个if,如果我们的输入是一个tensor,那么最后会将一个batch size的tensor重新stack在一起,比如输入的tensor是一张图片,3x30x30,如果batch size是32,那么按第一维stack之后的结果就是32x3x30x30,这里stack和concat有一点区别就是会增加一维。
所以通过上面的源码解读我们知道了数据读入具体是如何操作的,那么我们就能够实现自定义的数据读入了,我们需要自己按需要重新定义collate_fn这个函数,下面举个例子。
自定义数据读入的举例实现
下面我们来举一个麻烦的例子,比如做文本识别,需要将一张图片上的字符识别出来,比如下面这些图片

那么这个问题的输入就是一张一张的图片,他的label就是一串字符,但是由于长度是变化的,所以这个问题比较麻烦。
下面我们就来简单实现一下。
我们有一个train.txt的文件,上面有图片的名称和对应的label,首先我们需要定义一个Dataset。
class custom_dset(Dataset):
def __init__(self,
img_path,
txt_path,
img_transform=None,
loader=default_loader):
with open(txt_path, 'r') as f:
lines = f.readlines()
self.img_list = [
os.path.join(img_path, i.split()[0]) for i in lines
]
self.label_list = [i.split()[1] for i in lines]
self.img_transform = img_transform
self.loader = loader
def __getitem__(self, index):
img_path = self.img_list[index]
label = self.label_list[index]
# img = self.loader(img_path)
img = img_path
if self.img_transform is not None:
img = self.img_transform(img)
return img, label
def __len__(self):
return len(self.label_list)这里非常简单,就是将txt文件打开,然后分别读取图片名和label,由于存放图片的文件夹我并没有放上去,因为数据太大,所以读取图片以及对图片做一些变换的操作就不进行了。
接着我们自定义一个collate_fn,这里可以使用任何名字,只要在DataLoader里面传入就可以了。
def collate_fn(batch):
batch.sort(key=lambda x: len(x[1]), reverse=True)
img, label = zip(*batch)
pad_label = []
lens = []
max_len = len(label[0])
for i in range(len(label)):
temp_label = [0] * max_len
temp_label[:len(label[i])] = label[i]
pad_label.append(temp_label)
lens.append(len(label[i]))
return img, pad_label, lens代码的细节就不详细说了,总体来讲就是先按label长度进行排序,然后进行长度的pad,最后输出图片,label以及每个label的长度的list。
下面我们可以验证一下,得到如下的结果。
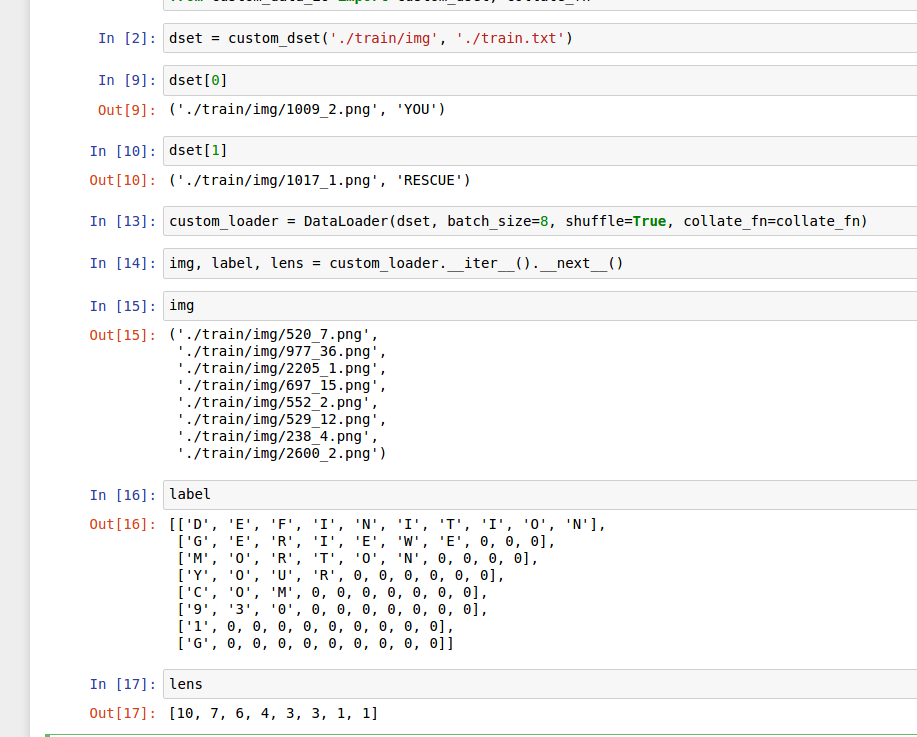
具体的操作大家可以去玩一下,改一改,能够实现任何你想要的输出,比如图片输出为一个32x3x30x30的tensor,将label中的字母转化为数字标示,然后也可以输出为tensor,任何你想要的操作都可以在上面显示的程序中执行。
以上就是本文所有的内容,后面的例子不是很完整,讲得也不是很详细,因为图片数据太大,不好传到github上,当然通过看代码能够更快的学习。通过本文的阅读,大家应该都能够掌握任何需要的数据读入,如果有问题欢迎评论留言。
总结
加载全部内容