Mybatis-Plus CRUD方法
扎哇太枣糕 人气:01 注解
1.1 @TableName
之前在入门案例中我们分析过:使用mp底层方法生成的SQL语句中,表名为mapper或者service接口传入的泛型首字母小写,表中字段名为泛型类的封装属性,如果表名与泛型名不对应的话,这个时候就需要在实体类上使用@TableName注解来修改实体类绑定的表
@TableName("对应的表名")
有些时候我们会将一个项目所用的所有表在命名上使用一个公共前缀,使用配置文件设置之后就会在所有的实体类所对应的的表名上拼接该前缀
mybatis-plus:
global-config:
db-config:
table-prefix: 表名的公共前缀
1.2 @TableId
mp中会默认将实体类中命名为id的属性作为主键与表的id主键相对应,但是如果实体类属性与表中的主键命名一致但不是id而是cid或者uid等的话,就会因为找不到主键而无法实现功能报错。于是就需要在实体类的属性上使用@TableId注解标注该属性对应的表中字段为该表的主键
@TableId
现在有这么一个情况,如果实体类中的属性与表中主键不一样的话,就该在实体类的属性上使用@TableId注解的value属性将两者对应起来
@TableId(value = "该属性在表中对应的字段名")
通过上一篇博客对mapper接口的insert方法测试发现,通过insert方法插入的记录,如果不设置id主键值的情况下,mp默认使用雪花算法(下面有拓展)生成一个id号插入到表中。如果想要将生成的id设置成根据表中主键值进行自增插入的话,首先应该将表中的主键字段设置成自增,然后将实体类的属性上使用@TableId注解的value属性设置
@TableId(type = IdType.AUTO)
除了使用注解单个设置实体类的主键生成策略之外,还可以通过配置文件设置所有实体类的主键生成策略
mybatis-plus:
global-config:
db-config:
id-type: auto
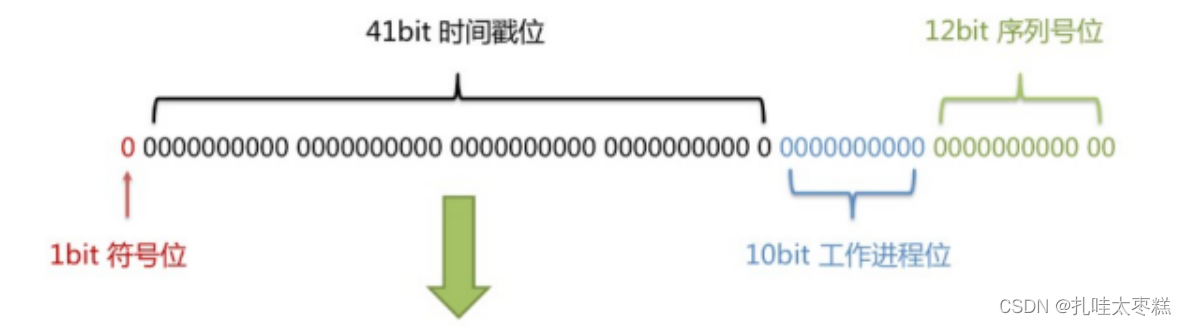
雪花算法
雪花算法是由Twitter公布的分布式主键生成算法,它能够保证不同表主键的不重复性,以及相同表主键的有序性。通过雪花算法生成的id长度共64bit(一个long型)。
- 最高1bit是符号位正0负1,id一般是正数
- 41bit时间截(毫秒级)
- 10bit作为机器的ID
- 12bit作为毫秒内的流水号
优点:整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞,并且效率较高
1.3 @TableField
mp会默认将表中的字段名里的下划线转换成驼峰命名,也就是将实体类中的userName属性与数据库中的user_name字段相对应。主键不对应的话使用@TableId注解,普通字段对应不上的话,就可以在实体类的属性上使用@TableField注解
@TableField("表中对应的字段名")
1.4 @TableLogic
@TableLogic注解就是设置字段为伪删除,也就是在执行删除方法的时候将该字段对应的值设置为1,再查询记录时不显示该字段为1的记录。 首先应该在数据库的表中创建一个字段用来标记是否删除(默认值为0即不删除),实体类创建相应的属性上用注解标注:
@TableLogic private Integer isDeleted;
使用@TableLogic注解之后,所有的删除操作都是伪删除,就是将标记字段的值改为1
@Test
public void deleteBatchIdsTest() {
List<Long> list = Arrays.asList(26L, 27L, 28L);
// UPDATE user SET is_deleted=1 WHERE cid IN ( ? , ? , ? ) AND is_deleted=0
int result = mapper.deleteBatchIds(list);
System.out.println("受影响的行数: " + result);
}
查询的时候会加入一个判断条件,就是标记字段的值要是0才显示
@Test
public void selectListTest() {
// SELECT cid AS uid,name,age,email,is_deleted FROM user WHERE is_deleted=0
List<User> users = mapper.selectList(null);
users.forEach(System.out::println);
}
在MP中mapper和service定义了很多的CRUD方法,可以像使用常见类API的方式直接调用使用,这些方法有很多按照方法参数的不同主要分为两大类,一种参数是wrapper放在下一章中进行讲解,另一种是接下来讲解的参数不是wrapper的方法
2 mapper层的CRUD方法
mapper层接口继承BaseMapper接口并传入需要操作的实体类泛型
// spring框架创建mapper接口相对应的接口实现类
@Mapper
public interface UserMapper extends BaseMapper<User> {
}
2.1 增(insert)
@Test
public void insertTest() {
User user = new User();
user.setName("张三");
user.setAge(20);
// sql语句:INSERT INTO user ( id, name, age ) VALUES ( ?, ?, ? )
int result = mapper.insert(user);
System.out.println("受影响的行数 " + result);
}
主键id不设置的话默认使用雪花算法生成
2.2 删(delete)
根据主键删除单条记录(deleteById)
@Test
public void deleteByIdTest() {
// DELETE FROM user WHERE id=?
int result = mapper.deleteById(1502966571370401793L);
System.out.println("受影响的行数: " + result);
}
根据主键删除多条记录(deleteBatchIds)
@Test
public void deleteBatchIdsTest() {
List<Long> list = Arrays.asList(1L, 2L, 3L);
// DELETE FROM user WHERE id IN ( ? , ? , ? )
int result = mapper.deleteBatchIds(list);
System.out.println("受影响的行数: " + result);
}
多条件删除(deleteByMap)
@Test
public void deleteByMapTest() {
HashMap<String, Object> map = new HashMap<>();
map.put("name", "张三");
map.put("age", 23);
// DELETE FROM user WHERE name = ? AND age = ?
int result = mapper.deleteByMap(map);
System.out.println("受影响的行数: " + result);
}
2.3 改(update)
根据主键id修改(updateById)
@Test
public void updateByIdTest() {
User user = new User();
user.setId(4L);
user.setName("张三");
user.setAge(20);
// UPDATE user SET name=?, age=? WHERE id=?
int result = mapper.updateById(user);
System.out.println("受影响的行数: " + result);
}
2.4 查(select)
根据主键id查找一条记录(selectById)
@Test public void selectTest() {
// SELECT id,name,age,email FROM user WHERE id=?
User user = mapper.selectById(4L);
System.out.println("查询结果为:" + user);
}
根据主键id查找多条记录(selectBatchIds)
@Test
public void selectByBatchIdsTest() {
List<Long> list = Arrays.asList(4L, 5L);
// SELECT id,name,age,email FROM user WHERE id IN ( ? , ? )
List<User> users = mapper.selectBatchIds(list);
System.out.print("查询结果为:");
users.forEach(System.out::println);
}
多条件查询(selectByMap)
@Test
public void selectByMapTest() {
HashMap<String, Object> map = new HashMap<>();
map.put("name", "张三");
map.put("age", 20);
// SELECT id,name,age,email FROM user WHERE name = ? AND age = ?
List<User> users = mapper.selectByMap(map);
System.out.print("查询结果为:");
users.forEach(System.out::println);
}
查询表中所有的记录(selectList)
@Test
public void selectListTest() {
// SELECT id,name,age,email FROM user
List<User> users = mapper.selectList(null);
users.forEach(System.out::println);
}
mapper层增删改查方法中的小知识点
⚠ 所有的增删改方法返回值都是受影响的行(记录)数
⚠ 以上都是单表的简单增删改查操作,如果这些功能无法满足你的需求,可以自定义SQL。可以在默认的路径(resources文件夹下的mapper文件夹)下创建mapper映射文件,或者在别的地方创建映射文件使用配置文件指定(mybatis-plus.mapper-locations),其他的操作和mybatis一样(接口方法、映射文件、调用方法)
3 service层的CRUD方法
service层接口继承IService接口并传入需要操作的实体类泛型
public interface UserService extends IService<User> {
}
service接口的实现类除了实现接口之外,还要继承ServiceImpl类并传入传泛型(mapper层接口,实体类),这样做的好处是还可以在实现类里实现自定义业务方法
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}
3.1 批量添加或者更新
批量添加saveBatch
@Test
public void saveBatchTest() {
// INSERT INTO user ( id, name, age ) VALUES ( ?, ?, ? )
List<User> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
User user = new User();
user.setName("tom" + i);
user.setAge(20 + i);
list.add(user);
}
boolean b = userService.saveBatch(list);
System.out.println(b);
}
批量添加或者更新saveOrUpdateBatch
第二个方法既可以用于批量添加还可以皮力量更新,判断是批量添加还是更新的依据是:看传入的列表中实体类对象是否设置了id属性或者说这个id值在表中是否存在,如果设置了id且id在表中存在的话就是批量更新,如果不设置id属性或者表中没有这个字段值的话就是批量添加。简而言之,有则改无则添
// 批量修改(因为user对象设置的id属性在表中存在)
@Test
public void saveOrUpdateBatchTest() {
// UPDATE user SET name=?, age=? WHERE id=?
List<User> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
User user = new User();
user.setId(10L + i);
user.setName("jack" + i);
user.setAge(20 + i);
list.add(user);
}
boolean b = userService.saveOrUpdateBatch(list);
System.out.println(b);
}
3.2 查询表中总记录数
@Test
public void getCountTest() {
// SELECT COUNT( * ) FROM user
long count = userService.count();
System.out.println(count);
}
加载全部内容