Python字符数据操作
Mr数据杨 人气:0字符串操作

字符串 + 运算符
+运算符用于连接字符串,返回一个由连接在一起的操作数组成的字符串。
>>> s = 'a'
>>> t = 'b'
>>> u = 'c'
>>> s + t
'ab'
>>> s + t + u
'abc'
>>> print('Go' + '!!!')
Go!!!
字符串 * 运算符
* 运算符创建字符串的多个副本。如果s是字符串并且n是整数,则以下任一表达式都会返回由的n连接副本组成的字符串s。
>>> s = 'f.' >>> s * 4 'f.f.f.f.' >>> 4 * s 'f.f.f.f.'
乘数操作数n必须是正整数。
>>> 'f' * -8 ''
字符串 in 运算符
Python 还提供了一个可以与字符串一起使用的成员运算符。如果第一个操作数包含在第二个操作数中,则in运算符返回 True 否则返回 False 。
>>> s = 'foo' >>> s in 'That\'s food for thought.' True >>> s in 'That\'s good for now.' False
用于相反的处理操作 not in 运算符。
>>> 'z' not in 'abc' True >>> 'z' not in 'xyz' False
内置字符串函数
Python 提供了许多内置于解释器并且始终可用的函数。
| 功能 | 描述 |
|---|---|
| chr() | 将整数转换为字符 |
| ord() | 将字符转换为整数 |
| len() | 返回字符串的长度 |
| str() | 返回对象的字符串表示形式 |
# ord(c)
# 计算机将所有信息存储为数字,使用了一种将每个字符映射到其代表数字的转换方案
# 常用方案称为ASCII。它涵盖了您可能最习惯使用的常见拉丁字符
# ord(c)返回 character 的 ASCII 值
>>> ord('a')
97
>>> ord('#')
35
# chr(n)
# chr()做的是ord()相反的事情,给定一个数值n,chr(n)返回一个字符串
# 处理Unicode 字符
>>> chr(97)
'a'
>>> chr(35)
'#'
>>> chr(8364)
'€'
>>> chr(8721)
'∑'
# len(s)
# 返回字符串的长度。
>>> s = 'I am a string.'
>>> len(s)
14
# str(obj)
# 返回对象的字符串表示形式
# Python 中的任何对象都可以呈现为字符串
>>> str(49.2)
'49.2'
>>> str(3+4j)
'(3+4j)'
>>> str(3 + 29)
'32'
>>> str('foo')
'foo'
字符串索引
在 Python 中,字符串是字符数据的有序序列,因此可以通过这种方式进行索引。可以通过指定字符串名称后跟方括号 ( []) 中的数字来访问字符串中的各个字符。
Python 中的字符串索引是从零开始的:字符串中的第一个字符具有 index 0,下一个字符具有 index 1,依此类推。最后一个字符的索引将是字符串的长度减1。
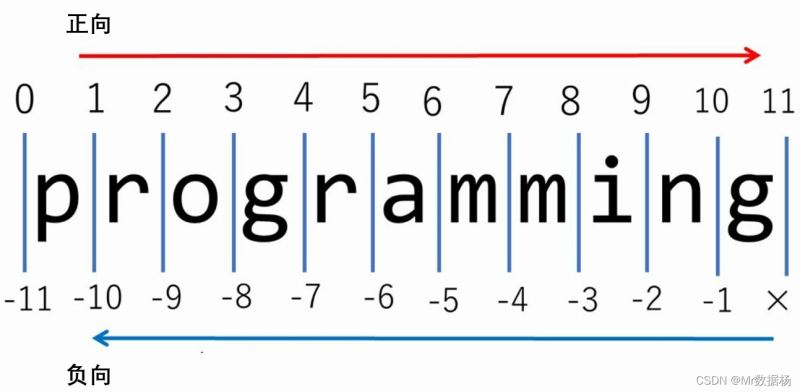
>>> s = 'foobar' # 正索引 >>> s[0] 'f' >>> s[1] 'o' >>> s[3] 'b' >>> len(s) 6 >>> s[len(s)-1] 'r' # 负索引 >>> s[-1] 'r' >>> s[-2] 'a' >>> len(s) 6 >>> s[-len(s)] 'f'
尝试超出字符串末尾的索引会导致错误。
# 正索引 >>> s[6] Traceback (most recent call last): File "<pyshell#17>", line 1, in <module> s[6] IndexError: string index out of range # 负索引 >>> s[-7] Traceback (most recent call last): File "<pyshell#26>", line 1, in <module> s[-7] IndexError: string index out of range
字符串切片
Python 还允许一种从字符串中提取子字符串的索引语法形式,称为字符串切片。如果s是字符串,则形式的表达式返回以 position 开头 s[m:n] 的部分。
>>> s = 'foobar' >>> s[2:5] 'oba'
省略第一个索引,则切片从字符串的开头开始。因此s[:m]和s[0:m]是等价的。
>>> s = 'foobar' >>> s[:4] 'foob' >>> s[0:4] 'foob'
省略第二个索引s[n:],则切片从第一个索引延伸到字符串的末尾。
>>> s = 'foobar' >>> s[2:] 'obar' >>> s[2:len(s)] 'obar'
对于任何字符串s和任何整数n( 0 ≤ n ≤ len(s)),s[:n] + s[n:]将等于s。
>>> s = 'foobar' >>> s[:4] + s[4:] 'foobar' >>> s[:4] + s[4:] == s True
省略两个索引会返回完整的原始字符串。
>>> s = 'foobar' >>> t = s[:] >>> id(s) 59598496 >>> id(t) 59598496 >>> s is t True
字符串切片中的步幅
对于 string ‘foobar’,切片0:6:2从第一个字符开始,到最后一个字符(整个字符串)结束,并且每隔一个字符被跳过。
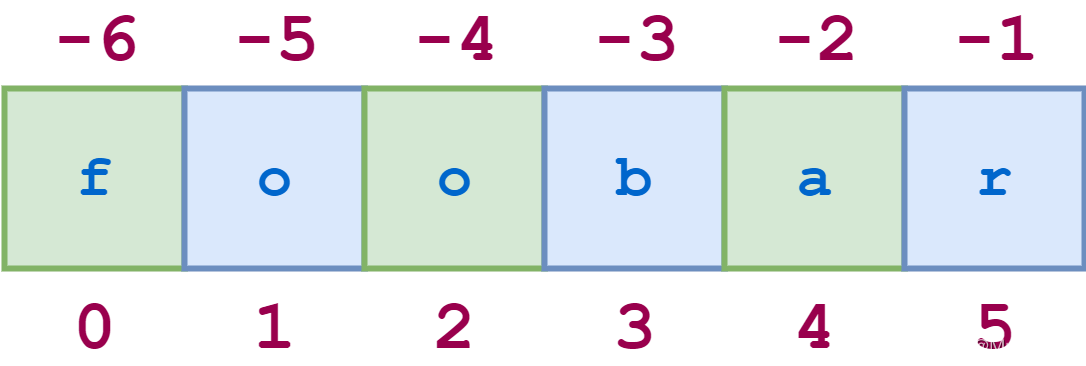
1:6:2指定从第二个字符(索引1)开始并以最后一个字符结束的切片,并且步幅值再次2导致每隔一个字符被跳过。
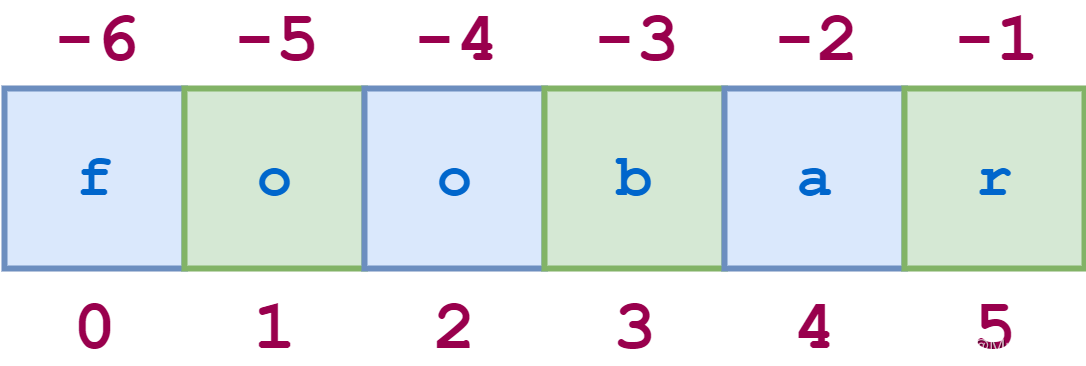
>>> s = 'foobar' >>> s[0:6:2] 'foa' >>> s[1:6:2] 'obr'
第一个和第二个索引可以省略,并分别默认为第一个和最后一个字符。
>>> s = '12345' * 5 >>> s '1234512345123451234512345' >>> s[::5] '11111' >>> s[4::5] '55555'
也可以指定一个负的步幅值,Python 会向后遍历字符串,开始/第一个索引应该大于结束/第二个索引。
>>> s = 'foobar' >>> s[5:0:-2] 'rbo'
第一个索引默认为字符串的末尾,第二个索引默认为开头。
>>> s = '12345' * 5 >>> s '1234512345123451234512345' >>> s[::-5] '55555'
将变量插入字符串
f-strings 提供的格式化功能非常广泛,后面还有一个关于格式化输出的教程。
显示算术计算的结果。可以用一个简单的 print() 语句来做到这一点,用逗号分隔数值和字符串文字。
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print('The product of', n, 'and', m, 'is', prod)
The product of 20 and 25 is 500
使用 f-string 重铸,上面的示例看起来更清晰。
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print(f'The product of {n} and {m} is {prod}')
The product of 20 and 25 is 500
Python 的三种引用机制中的任何一种都可用于定义 f 字符串。
>>> var = 'Bark'
>>> print(f'A dog says {var}!')
A dog says Bark!
>>> print(f"A dog says {var}!")
A dog says Bark!
>>> print(f'''A dog says {var}!''')
A dog says Bark!修改字符串
字符串是 Python 认为不可变的数据类型之一,修改会导致错误。
>>> s = 'foobar'
>>> s[3] = 'x'
Traceback (most recent call last):
File "<pyshell#40>", line 1, in <module>
s[3] = 'x'
TypeError: 'str' object does not support item assignment
可以通过生成具有所需更改的原始字符串的副本来轻松完成所需的操作。
>>> s = s[:3] + 'x' + s[4:] >>> s 'fooxar'
可以使用内置的字符串方法完成修改操作。
>>> s = 'foobar'
>>> s = s.replace('b', 'x')
>>> s
'fooxar'
内置字符串方法
Python 程序中的每一项数据都是一个对象。
dir会返回一个内置方法与属性列表。
>>> dir('a,b,cdefg')
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
方法类似于函数。方法是与对象紧密关联的一种特殊类型的可调用过程。像函数一样,调用方法来执行不同的任务,但它是在特定对象上调用的,并且在执行期间知道其目标对象。
目标字符串执行大小写转换应用举例
s.capitalize() 将目标字符串大写
# 返回第一个字符转换为大写,所有其他字符转换为小写的副本 >>> s = 'foO BaR BAZ quX' >>> s.capitalize() 'Foo bar baz qux' # 非字母字符不变 >>> s = 'foo123#BAR#.' >>> s.capitalize() 'Foo123#bar#.'
s.lower() 将字母字符转换为小写
# 返回所有字母字符都转换为小写的副本 >>> 'FOO Bar 123 baz qUX'.lower() 'foo bar 123 baz qux'
s.swapcase() 交换字母字符的大小写
# 返回将大写字母字符转换为小写字母的副本,s反之亦然 >>> 'FOO Bar 123 baz qUX'.swapcase() 'foo bAR 123 BAZ Qux'
**s.title() 将目标字符串转换为 标题大小写 **
# 返回一个副本,s其中每个单词的第一个字母转换为大写,其余字母为小写 >>> 'the sun also rises'.title() 'The Sun Also Rises'
s.upper() 将字母字符转换为大写
# 返回所有字母字符都转换为大写的副本 >>> 'FOO Bar 123 baz qUX'.upper() 'FOO BAR 123 BAZ QUX'
查找和替换方法应用举例
s.count(<sub>,[<start>,<end>]) 计算目标字符串中子字符串的出现次数
# 返回字符串中非重叠出现的<sub>次数
>>> 'foo goo moo'.count('oo')
3
# 指定切片位置
>>> 'foo goo moo'.count('oo', 0, 8)
2
s.endswith(<suffix>,[<start>,<end>]) 确定目标字符串是否以给定的子字符串结尾
# s.endswith(<suffix>)如果s以指定的结尾则返回True,否则返回False
>>> 'foobar'.endswith('bar')
True
>>> 'foobar'.endswith('baz')
False
# 指定切片位置
>>> 'foobar'.endswith('oob', 0, 4)
True
>>> 'foobar'.endswith('oob', 2, 4)
False
s.find(<sub>,[<start>,<end>]) 在目标字符串中搜索给定的子字符串
# 返回找到子字符串s.find(<sub>)的索引
>>> 'foo bar foo baz foo qux'.find('foo')
0
# 如果未找到指定的子字符串,则此方法返回-1
>>> 'foo bar foo baz foo qux'.find('grault')
-1
# 指定切片位置
>>> 'foo bar foo baz foo qux'.find('foo', 4)
8
>>> 'foo bar foo baz foo qux'.find('foo', 4, 7)
-1
s.index(<sub>,[<start>,<end>]) 在目标字符串中搜索给定的子字符串
# 和find相同,但是未找到会引发异常
>>> 'foo bar foo baz foo qux'.index('grault')
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
'foo bar foo baz foo qux'.index('grault')
ValueError: substring not founds.rfind(<sub>,[<start>,<end>]) 从末尾开始搜索给定子字符串的目标字符串
# 返回找到子字符串的最高索引
>>> 'foo bar foo baz foo qux'.rfind('foo')
16
# 未找到子字符串则返回-1
>>> 'foo bar foo baz foo qux'.rfind('grault')
-1
# 指定切片位置
>>> 'foo bar foo baz foo qux'.rfind('foo', 0, 14)
8
>>> 'foo bar foo baz foo qux'.rfind('foo', 10, 14)
-1
s.rindex(<sub>,[<start>,<end>]) 从末尾开始搜索给定子字符串的目标字符串
# 和rfind相同,但是未找到会引发异常
>>> 'foo bar foo baz foo qux'.rindex('grault')
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
'foo bar foo baz foo qux'.rindex('grault')
ValueError: substring not found
s.startswith(<prefix>,[<start>,<end>]) 确定目标字符串是否以给定的子字符串开头
# 返回判断是否以字符串<suffix>开头的结果
>>> 'foobar'.startswith('foo')
True
>>> 'foobar'.startswith('bar')
False
# 指定切片位置
>>> 'foobar'.startswith('bar', 3)
True
>>> 'foobar'.startswith('bar', 3, 2)
False
字符分类方法应用举例
s.isalnum() 确定目标字符串是否由字母数字字符组成
# 如果s为非空且其所有字符都是字母数字(字母或数字)返回True >>> 'abc123'.isalnum() True >>> 'abc$123'.isalnum() False >>> ''.isalnum() False
s.isalpha() 确定目标字符串是否由字母字符组成
# s为非空且其所有字符都是字母则返回True >>> 'ABCabc'.isalpha() True >>> 'abc123'.isalpha() False
s.isdigit() 确定目标字符串是否由数字字符组成
# 如果为非空且其所有字符都是数字则返回True >>> '123'.isdigit() True >>> '123abc'.isdigit() False
s.isidentifier() 确定目标字符串是否是有效的 Python 标识符
# 有效的 Python 标识符返回True >>> 'foo32'.isidentifier() True >>> '32foo'.isidentifier() False >>> 'foo$32'.isidentifier() False
s.islower() 确定目标字符串的字母字符是否为小写
# 非空并且它包含的所有字母字符都是小写则返回True >>> 'abc'.islower() True >>> 'abc1$d'.islower() True >>> 'Abc1$D'.islower() False
s.isprintable() 确定目标字符串是否完全由可打印字符组成
# 为空或包含的所有字母字符都是可打印的则返回True >>> 'a\tb'.isprintable() False >>> 'a b'.isprintable() True >>> ''.isprintable() True >>> 'a\nb'.isprintable() False
s.isspace() 确定目标字符串是否由空白字符组成
# 为非空且所有字符都是空白字符则返回True >>> ' \t \n '.isspace() True >>> ' a '.isspace() False # ASCII 字符可以作为空格 >>> '\f\u2005\r'.isspace() True
s.istitle() 确定目标字符串是否为标题大小写
# 则返回每个单词的第一个字母字符为大写,并且每个单词中的所有其他字母字符均为小写为True >>> 'This Is A Title'.istitle() True >>> 'This is a title'.istitle() False >>> 'Give Me The #$#@ Ball!'.istitle() True
s.isupper() 确定目标字符串的字母字符是否为大写
# 为非空并且它包含的所有字母字符都是大写则返回True >>> 'ABC'.isupper() True >>> 'ABC1$D'.isupper() True >>> 'Abc1$D'.isupper() False
字符串格式方法应用举例
s.center(<width>,[<fill>]) 使字段中的字符串居中
# 返回一个由以宽度为中心的字段组成的字符串<width> >>> 'foo'.center(10) ' foo ' # 指定填充字符 >>> 'bar'.center(10, '-') '---bar----' # 字符长度小于指定返回原字符 >>> 'foo'.center(2) 'foo'
s.expandtabs(tabsize=8) 展开字符串中的制表符
# 将每个制表符 ( '\t') 替换为空格 >>> 'a\tb\tc'.expandtabs() 'a b c' >>> 'aaa\tbbb\tc'.expandtabs() 'aaa bbb c' # tabsize指定备用制表位列 >>> 'a\tb\tc'.expandtabs(4) 'a b c' >>> 'aaa\tbbb\tc'.expandtabs(tabsize=4) 'aaa bbb c'
s.ljust(,[<fill>]) 左对齐字段中的字符串
# 返回一个由宽度为左对齐的字段组成的字符串<width> >>> 'foo'.ljust(10) 'foo ' # 指定填充字符 >>> 'foo'.ljust(10, '-') 'foo-------' # 字符长度小于指定返回原字符 >>> 'foo'.ljust(2) 'foo'
s.lstrip([<chars>]) 修剪字符串中的前导字符
# 返回从左端删除任何空白字符的副本 >>> ' foo bar baz '.lstrip() 'foo bar baz ' >>> '\t\nfoo\t\nbar\t\nbaz'.lstrip() 'foo\t\nbar\t\nbaz'
s.replace(<old>, <new>[, <count>]) 替换字符串中出现的子字符串
# 返回所有出现的子字符串替换为s.replace(<old>, <new>)的副本
>>> 'foo bar foo baz foo qux'.replace('foo', 'grault')
'grault bar grault baz grault qux'
# <count>参数指定替换数
>>> 'foo bar foo baz foo qux'.replace('foo', 'grault', 2)
'grault bar grault baz foo qux'
s.rjust(<width>, [<fill>]) 右对齐字段中的字符串
# 返回一个由宽度字段右对齐组成的字符串<width> >>> 'foo'.rjust(10) ' foo' # 指定填充字符 >>> 'foo'.rjust(10, '-') '-------foo' # 字符长度小于指定返回原字符 >>> 'foo'.rjust(2) 'foo'
s.rstrip([<chars>]) 修剪字符串中的尾随字符
# 返回从右端删除任何空白字符的副本
>>> ' foo bar baz '.rstrip()
' foo bar baz'
>>> 'foo\t\nbar\t\nbaz\t\n'.rstrip()
'foo\t\nbar\t\nbaz'
# 指定删除字符集
>>> 'foo.$$$;'.rstrip(';$.')
'foo'
s.strip([<chars>]) 从字符串的左右两端去除字符
# 同时调用s.lstrip()和s.rstrip()
>>> s = ' foo bar baz\t\t\t'
>>> s = s.lstrip()
>>> s = s.rstrip()
>>> s
'foo bar baz'
# 指定删除字符集
>>> 'www.realpython.com'.strip('w.moc')
'realpython'
s.zfill(<width>) 用零填充左侧的字符串
# 将左填充'0'字符的副本返回到指定的<width> >>> '42'.zfill(5) '00042' # 如果包含符号仍保留 >>> '+42'.zfill(8) '+0000042' >>> '-42'.zfill(8) '-0000042' # 字符长度小于指定返回原字符 >>> '-42'.zfill(3) '-42'
顺序集合 iterables 字符串和列表之间的转换方法应用举例
s.join(<iterable>) 连接来自可迭代对象的字符串
# 返回由分隔的对象连接得到的字符串
>>> ', '.join(['foo', 'bar', 'baz', 'qux'])
'foo, bar, baz, qux'
# 字符串的操作
>>> list('corge')
['c', 'o', 'r', 'g', 'e']
>>> ':'.join('corge')
'c:o:r:g:e'
# list中的数据必须是字符串
>>> '---'.join(['foo', 23, 'bar'])
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
'---'.join(['foo', 23, 'bar'])
TypeError: sequence item 1: expected str instance, int found
>>> '---'.join(['foo', str(23), 'bar'])
'foo---23---bar'
s.partition(<sep>) 根据分隔符划分字符串
# 返回值是一个由三部分组成的元组:<sep>前、<sep>本身、<sep>后
>>> 'foo.bar'.partition('.')
('foo', '.', 'bar')
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
# 如果未找到则返回2个空字符
>>> 'foo.bar'.partition('@@')
('foo.bar', '', '')
s.rpartition(<sep>) 根据分隔符划分字符串
# 与s.partition(<sep>)相同,用于指定最后一次拆分符
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
>>> 'foo@@bar@@baz'.rpartition('@@')
('foo@@bar', '@@', 'baz')
s.rsplit(sep=None, maxsplit=-1) 将字符串拆分为子字符串列表
# 返回拆分为由任何空格序列分隔的子字符串,并将子字符串作为列表 >>> 'foo bar baz qux'.rsplit() ['foo', 'bar', 'baz', 'qux'] >>> 'foo\n\tbar baz\r\fqux'.rsplit() ['foo', 'bar', 'baz', 'qux'] # 指定拆分符 >>> 'foo.bar.baz.qux'.rsplit(sep='.') ['foo', 'bar', 'baz', 'qux'] # 指定最多拆分次数 >>> 'www.realpython.com'.rsplit(sep='.', maxsplit=1) ['www.realpython', 'com'] >>> 'www.realpython.com'.rsplit(sep='.', maxsplit=-1) ['www', 'realpython', 'com'] >>> 'www.realpython.com'.rsplit(sep='.') ['www', 'realpython', 'com']
s.split(sep=None, maxsplit=-1) 将字符串拆分为子字符串列表
# 与s.rsplit()一样,指定<maxsplit>则从左端而不是右端计算拆分
>>> 'www.realpython.com'.split('.', maxsplit=1)
['www', 'realpython.com']
>>> 'www.realpython.com'.rsplit('.', maxsplit=1)
['www.realpython', 'com']
s.splitlines([<keepends>]) 在行边界处断开字符串
# 返回换行符切分的列表,其中包含\n、\r、\r\n、\v or \x0b、\f or \x0c、\x1c、\x1d、\x1e、\x85、\u2028、\u2029 >>> 'foo\nbar\r\nbaz\fqux\u2028quux'.splitlines() ['foo', 'bar', 'baz', 'qux', 'quux'] # 同时存在多个空白行 >>> 'foo\f\f\fbar'.splitlines() ['foo', '', '', 'bar'] # 也可以保留行边界符号 >>> 'foo\nbar\nbaz\nqux'.splitlines(True) ['foo\n', 'bar\n', 'baz\n', 'qux'] >>> 'foo\nbar\nbaz\nqux'.splitlines(1) ['foo\n', 'bar\n', 'baz\n', 'qux']
bytes对象
对象是操作二进制数据的bytes核心内置类型之一。bytes对象是不可变的单字节值序列。

定义文字bytes对象
文字的bytes定义方式与添加’b’前缀的字符串文字相同。
>>> b = b'foo bar baz' >>> b b'foo bar baz' >>> type(b) <class 'bytes'>
可以使用任何单引号、双引号或三引号机制。
>>> b'Contains embedded "double" quotes' b'Contains embedded "double" quotes' >>> b"Contains embedded 'single' quotes" b"Contains embedded 'single' quotes" >>> b'''Contains embedded "double" and 'single' quotes''' b'Contains embedded "double" and \'single\' quotes' >>> b"""Contains embedded "double" and 'single' quotes""" b'Contains embedded "double" and \'single\' quotes'
'r’前缀可以用在文字上以禁用转义序列的bytes处理。
>>> b = rb'foo\xddbar' >>> b b'foo\\xddbar' >>> b[3] 92 >>> chr(92) '\\'
bytes使用内置bytes()函数定义对象
bytes()函数还创建一个bytes对象。返回什么样的bytes对象取决于传递给函数的参数。
bytes(<s>, <encoding>) bytes从字符串创建对象
# 根据指定的使用将字符串转换<s>为bytes对象
>>> b = bytes('foo.bar', 'utf8')
>>> b
b'foo.bar'
>>> type(b)
<class 'bytes'>
bytes(<size>) 创建一个bytes由 null ( 0x00) 字节组成的对象
# 定义bytes指定的对象<size>必须是一个正整数。 >>> b = bytes(8) >>> b b'\x00\x00\x00\x00\x00\x00\x00\x00' >>> type(b) <class 'bytes'>
bytes() bytes从可迭代对象创建对象
# 生成的整数序列中定义一个对象<iterable> n0 ≤ n ≤ 255 >>> b = bytes([100, 102, 104, 106, 108]) >>> b b'dfhjl' >>> type(b) <class 'bytes'> >>> b[2] 104
bytes对象操作,操作参考字符串。
运算符 in 和 not in
>>> b = b'abcde' >>> b'cd' in b True >>> b'foo' not in b True
*连接 ( +) 和复制 ( ) 运算符
>>> b = b'abcde' >>> b + b'fghi' b'abcdefghi' >>> b * 3 b'abcdeabcdeabcde'
索引和切片
>>> b = b'abcde' >>> b[2] 99 >>> b[1:3] b'bc'
内置功能
>>> b = b'foo,bar,foo,baz,foo,qux' >>> len(b) 23 >>> min(b) 44 >>> max(b) 122 >>> b = b'foo,bar,foo,baz,foo,qux' >>> b.count(b'foo') 3 >>> b.endswith(b'qux') True >>> b.find(b'baz') 12 >>> b.split(sep=b',') [b'foo', b'bar', b'foo', b'baz', b'foo', b'qux'] >>> b.center(30, b'-') b'---foo,bar,foo,baz,foo,qux----' >>> b[2:3] b'o' >>> list(b) [102, 111, 111, 44, 98, 97, 114, 44, 102, 111, 111, 44, 98, 97, 122, 44, 102, 111, 111, 44, 113, 117, 120]
bytes.fromhex(<s>) 返回bytes从一串十六进制值构造的对象
# 返回bytes将每对十六进制数字转换<s>为相应字节值的对象
>>> b = bytes.fromhex(' aa 68 4682cc ')
>>> b
b'\xaahF\x82\xcc'
>>> list(b)
[170, 104, 70, 130, 204]
b.hex() bytes从对象返回一串十六进制值
# 将bytes对象b转换为十六进制数字对字符串的结果,与.fromhex()相反
>>> b = bytes.fromhex(' aa 68 4682cc ')
>>> b
b'\xaahF\x82\xcc'
>>> b.hex()
'aa684682cc'
>>> type(b.hex())
<class 'str'>bytearray对象,Python 支持的另一种二进制序列类型
bytearray始终使用内置函数创建对象bytearray()
>>> ba = bytearray('foo.bar.baz', 'UTF-8')
>>> ba
bytearray(b'foo.bar.baz')
>>> bytearray(6)
bytearray(b'\x00\x00\x00\x00\x00\x00')
>>> bytearray([100, 102, 104, 106, 108])
bytearray(b'dfhjl')
bytearray对象是可变的,可以使用索引和切片修改对象的内容
>>> ba = bytearray('foo.bar.baz', 'UTF-8')
>>> ba
bytearray(b'foo.bar.baz')
>>> ba[5] = 0xee
>>> ba
bytearray(b'foo.b\xeer.baz')
>>> ba[8:11] = b'qux'
>>> ba
bytearray(b'foo.b\xeer.qux')
bytearray对象也可以直接从对象构造bytes
>>> ba = bytearray(b'foo') >>> ba bytearray(b'foo')
加载全部内容