yolov5参数workers与batch-size
flamebox 人气:13yolov5训练命令
python .\train.py --data my.yaml --workers 8 --batch-size 32 --epochs 100
yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。
workers和batch-size参数的理解
一般训练主要需要调整的参数是这两个:
workers
指数据装载时cpu所使用的线程数,默认为8。代码解释如下
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')一般默使用8的话,会报错~~。原因是爆系统内存,除了物理内存外,需要调整系统的虚拟内存。训练时主要看已提交哪里的实际值是否会超过最大值,超过了不是强退程序就是报错。
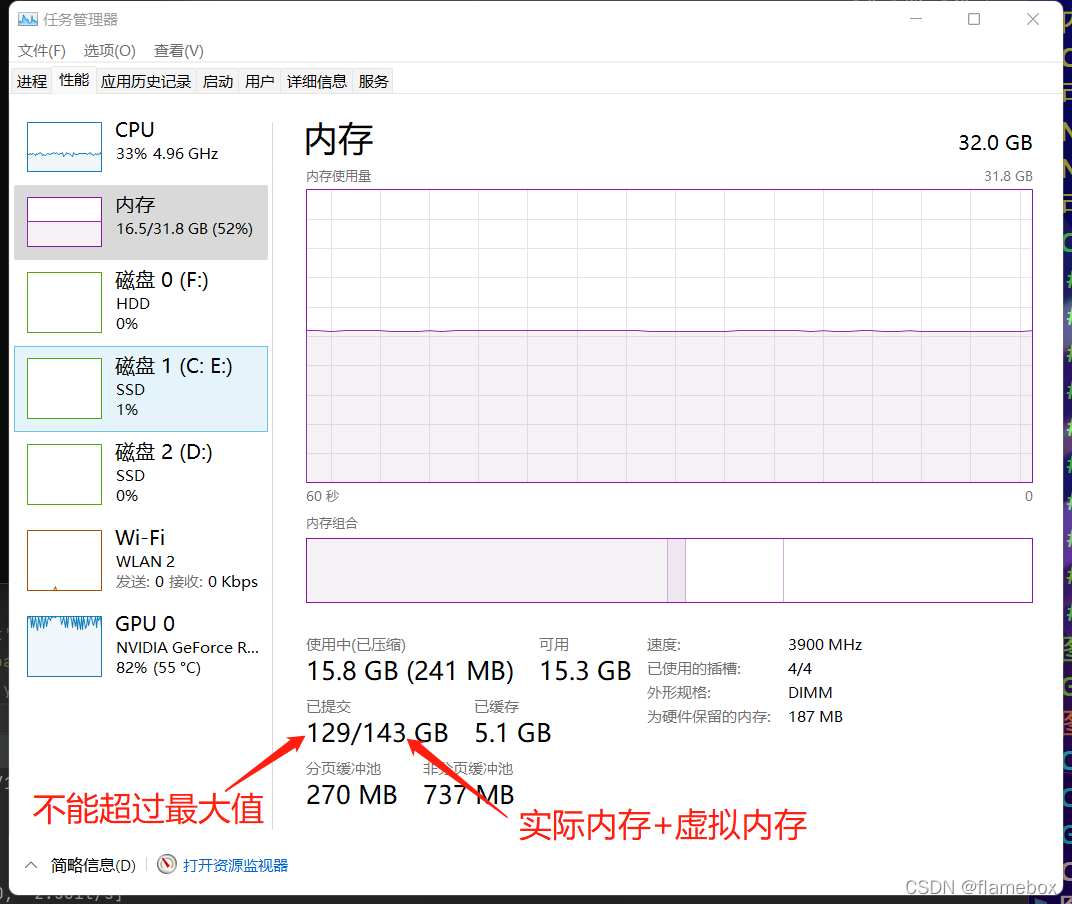
所以需要根据实际情况分配系统虚拟内存(python执行程序所在的盘)的最大值
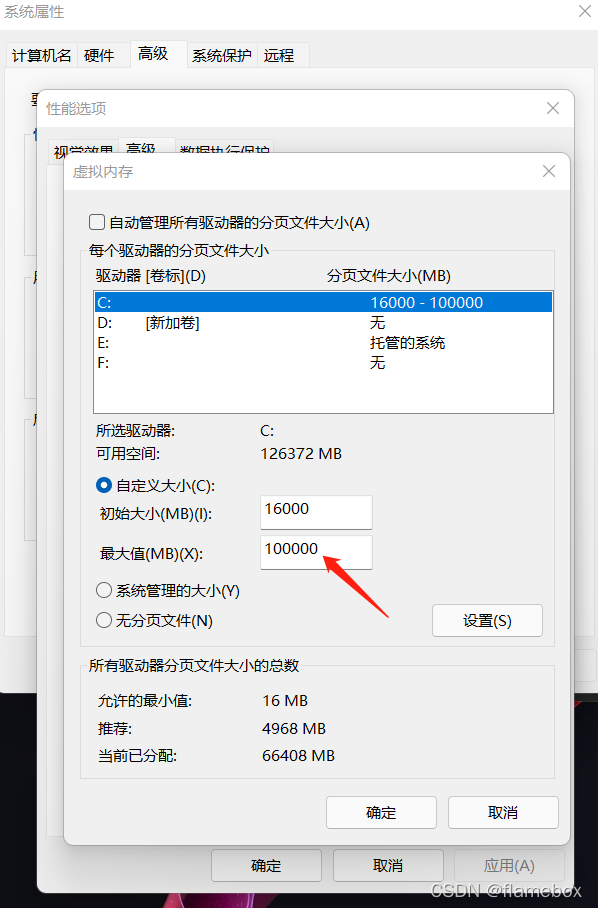
batch-size
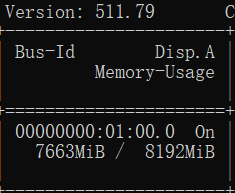
就是一次往GPU哪里塞多少张图片了。决定了显存占用大小,默认是16。
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')训练时显存占用越大当然效果越好,但如果爆显存,也是会无法训练的。我使用–batch-size 32时,显存差不多能利用完。
两个参数的调优
对于workers,并不是越大越好,太大时gpu其实处理不过来,训练速度一样,但虚拟内存(磁盘空间)会成倍占用。
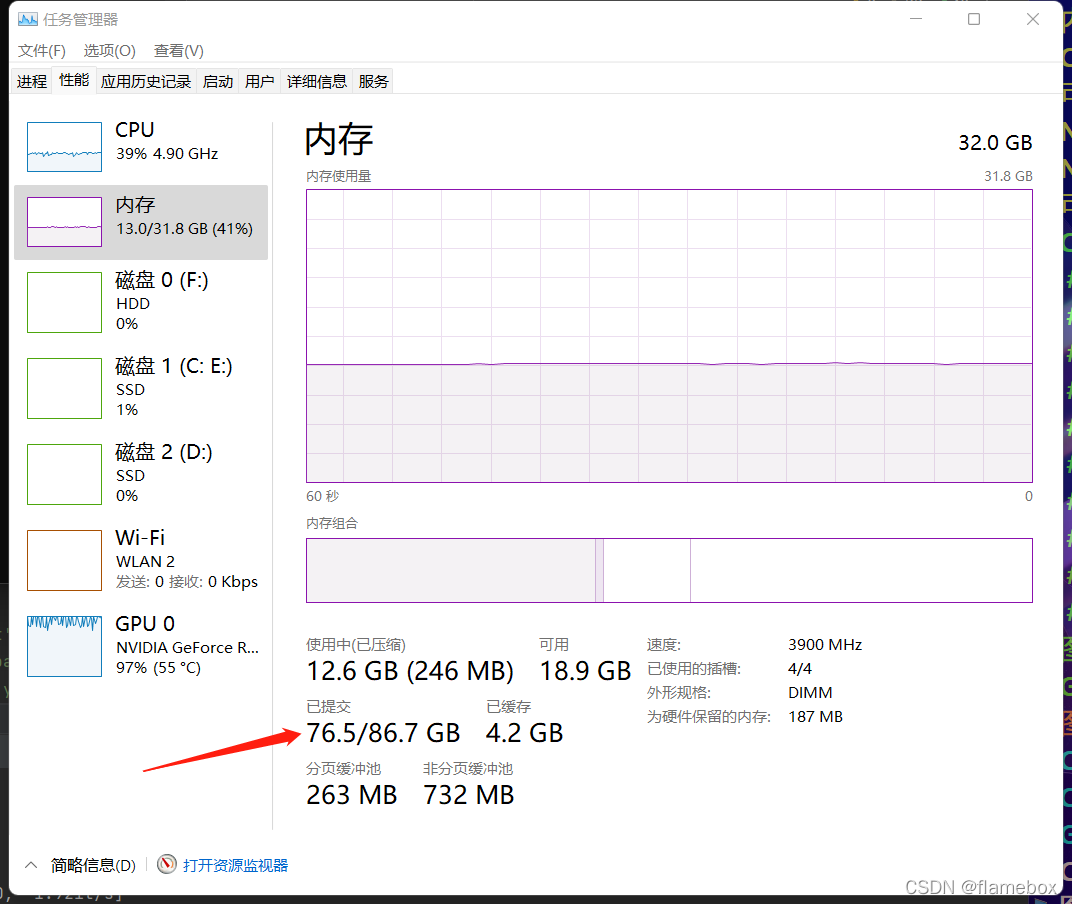
workers为4时的内存占用
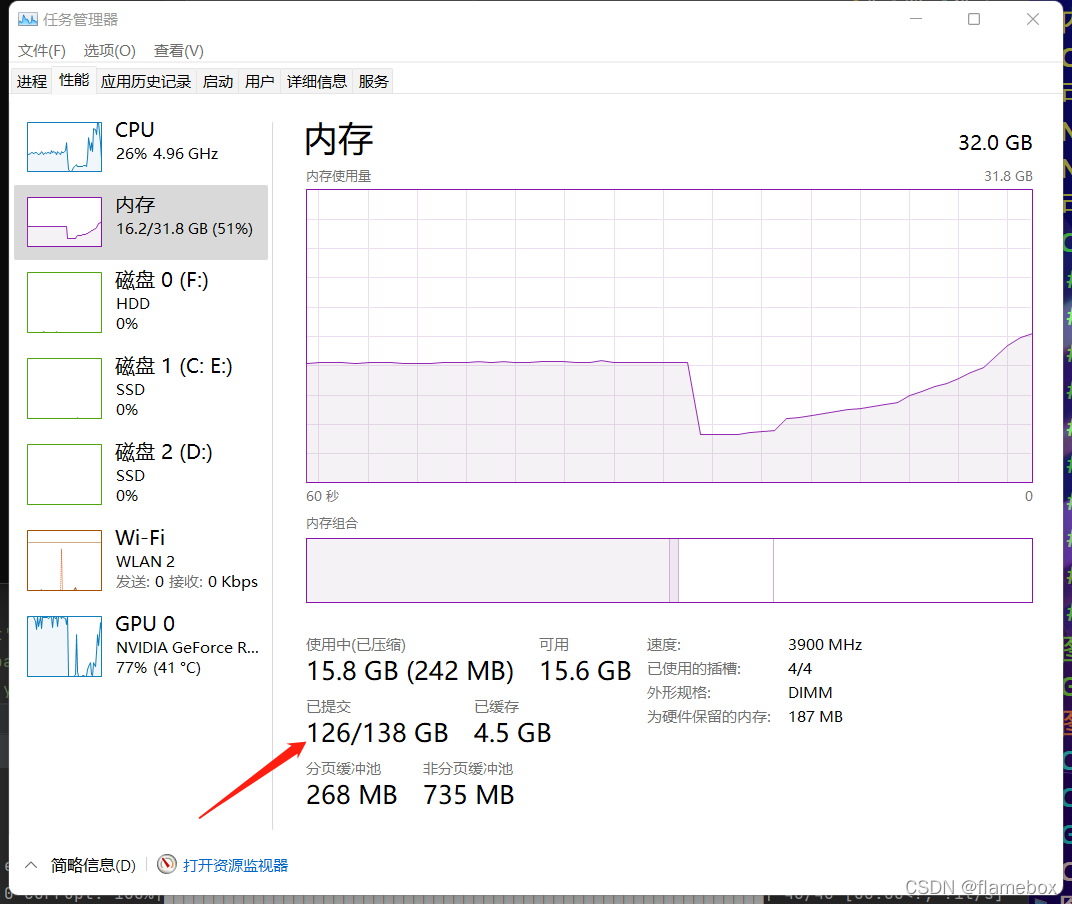
workers为8时的内存占用
我的显卡是rtx3050,实际使用中上到4以上就差别不大了,gpu完全吃满了。但是如果设置得太小,gpu会跑不满。比如当workers=1时,显卡功耗只得72W,速度慢了一半;workers=4时,显卡功耗能上到120+w,完全榨干了显卡的算力。所以需要根据你实际的算力调整这个参数。
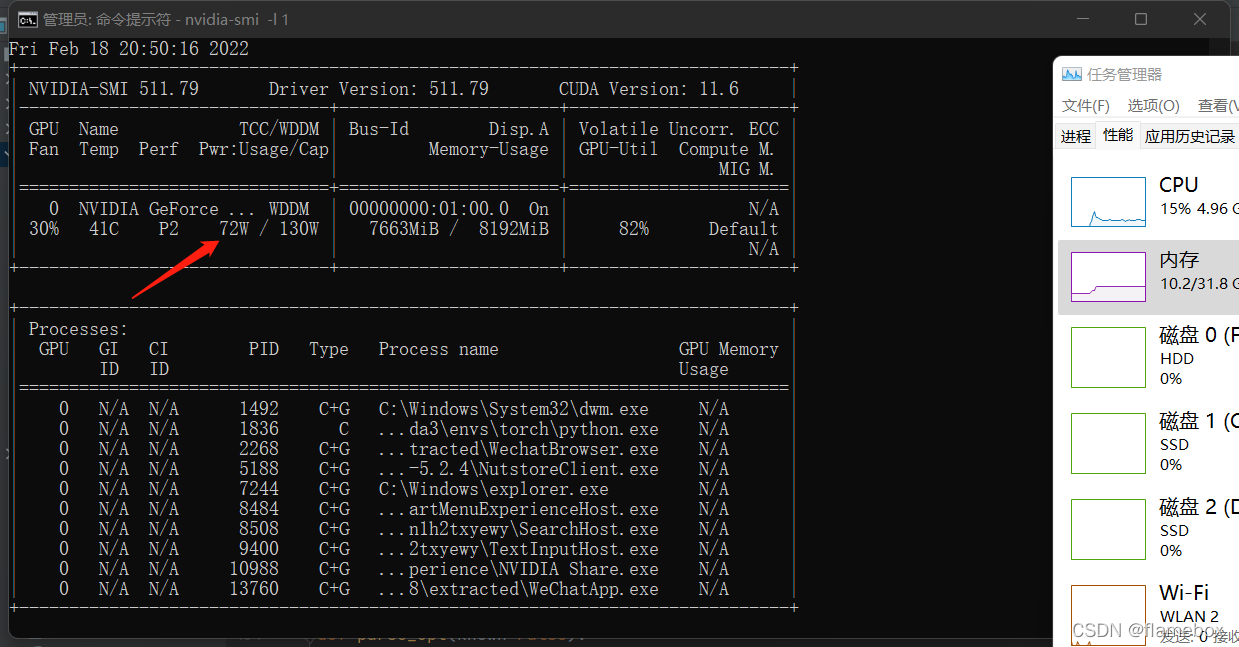
2. 对于batch-size,有点玄学。理论是能尽量跑满显存为佳,但实际测试下来,发现当为8的倍数时效率更高一点。就是32时的训练效率会比34的高一点,这里就不太清楚原理是什么了,实际操作下来是这样。
总结
以上参数的调整能最大化显卡的使用效率,其中的具体数值和电脑的实际配置还有模型大小、数据集大小有关,需要根据实际情况反复调整。当然,要实质提升训练速度,还是得有好显卡(钞能力)~~~~
加载全部内容