Python文件序列化
渴望力量的哈士奇 人气:1前面章节我们学些了文件对象的创建、写入与读取,并且针对 .py 文件 与 .txt 文件进行了有针对性的小练习。 通过前面的学习我们知道,文件对象的读写只能进行 字符串 或 byte 类型的操作,其他类型只能通过格式化存储或者数据类型的转换才能实现。
但无论是哪一种,从文件中读取数据后都需要进行比较复杂的处理才能还原到原始的数据类型。为了简化数据类型的写入和获取,今天我们来学习一个新的知识点 —> 序列化。
通过学习序列化,可以不必过分担心写入文件的数据类型是什么,并且读取文件也可以非常轻松的还原数据类型。[比较讨厌这种每章之前写概述、摘要的短句。]
初识序列化与反序列化
什么是序列化?
通俗一点来说,序列化就是将 对象的信息 或者 数据结构的信息 通过一定的规则进行转换,可以达到 文件存储 或 网络传输 的效果。通过前面章节的学习,我们知道如果要进行存储或网络传输,最终的数据类型都是 字符串,而且这些字符串还需要是有一定规则的字符串。
而我们今天要学习的 内置模块 ---> json 可以用于文件存储或者网络传输,这也是序列化的作用。
而反序列化就是通过序列化规则生成的字符串再反转为原始的数据类型,这就是反序列化。
这里我们可以引入 字符串 与 byte 之间的转换来理解 序列化与反序列化, 字符串与 byte 类型之间互相转换常用的 encode() 函数、与 decode() 函数,分别代表着编码与解码,所以有编码,就一定有解码 。套用在序列化来理解,既然存在序列化,那么就肯定有对应的反序列化哈。
可序列化的数据类型
哪些数据类型是可以序列化,哪些又是不可以序列化的呢?
可序列化:number、str、list、tuple、dict [字典是最常用的序列化数据类型]
不可序列化:class 、def (函数与实例化对象)、set 是无法进行序列化的
Python 中的json
json模块是一个通用的序列化模块,通过它可以完成通用化的序列化与反序列化操作。为什么说是通用的,那是因为几乎所有的编程语言都有json模块,而且他们序列化与反序列化的规则是统一的。
所以我们在 Python 中序列化的内容,在任意其他编程语言中都可以进行反序列化并使用原始的数据,这就是通用的意思。
dumps() 与 loads() 函数
json 中最重要的函数 - 就是 dumps() 与 loads() 函数
| 方法名 | 参数 | 介绍 | 举例 | 返回值 |
|---|---|---|---|---|
| dumps | obj | 对象序列化 | json.dumps([1, 2, 3]) | 字符串 |
| loads | str | 反序列化 | Json.loads(’[1, 2, 3]’) | 原始数据类型 |
可序列化数据类型演示案例
演示案例如下:
import json
int_test = 666 # 定义 整型、字符串、列表、元组、字典 五种数据类型 ,用于序列化测试
str_test = 'test_string'
list_test = [1, 2, 3]
tuple_test = (4, 5, 6)
dict_test = {'Name': '托尼.史塔克', 'Sex': '男'}
int_test_json = json.dumps(int_test) # 将上文中五种数据类型进行序列化操作
str_test_json = json.dumps(str_test)
list_test_json = json.dumps(list_test)
tuple_test_json = json.dumps(tuple_test)
dict_test_json = json.dumps(dict_test)
在 Treminal 终端 执行上述测试脚本,如下图:
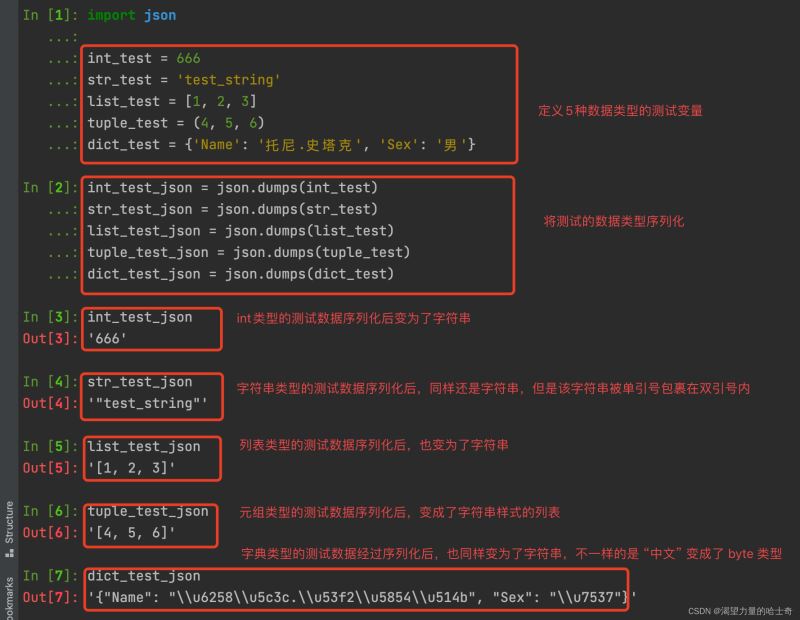
这里我们重点介绍一下 字典类型的序列化结果
In [7]: dict_test_json
Out[7]: '{"Name": "\\u6258\\u5c3c.\\u53f2\\u5854\\u514b", "Sex": "\\u7537"}'
从执行结果我们可以看出字典类型的数据类型,经过序列化后。字典变成了字符串的同时,且字典内的 单引号 变成了 双引号,中文也变成了比特类型,并且进行了 encode 。(这是序列化的一个标准)
为什么我们说 字典类型是非常是和序列化的呢?实际上 json 并不仅仅是一个标准,也是一种文件格式。比如我们编写脚本的 .py 格式的文件,就是 python 文件容器;.txt 格式的文件是普通的文本文件容器;同样的,.json 格式的文件也是文件容器,json 文件存储的样式(格式)就是字典类型的序列化格式。
接下来我们再尝试将上文的五种测试数类型反序列化处理,看看结果会怎样?
_int_test_json = json.loads(int_test_json) _str_test_json = json.loads(str_test_json) _list_test_json = json.loads(list_test_json) _tuple_test_json = json.loads(tuple_test_json) _dict_test_json = json.loads(dict_test_json)
在 Treminal 终端 执行上述测试脚本,如下图:
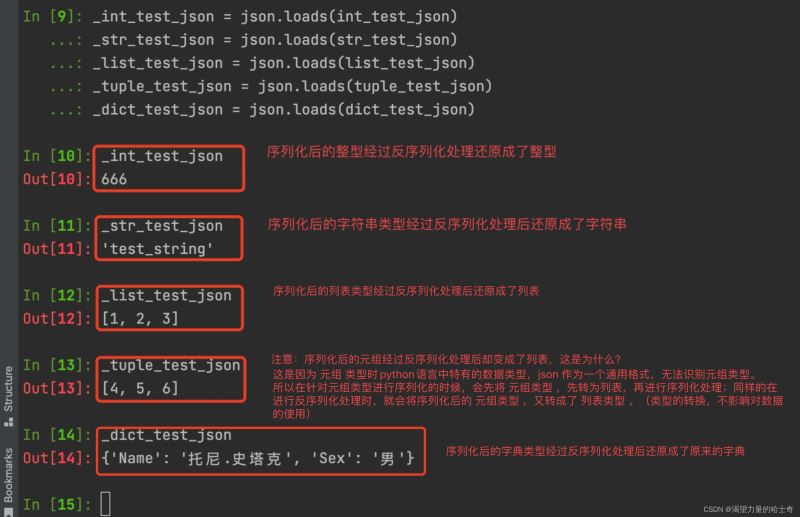
划重点:元组类型经过序列化处理后再通过反序列化还原数据时,会变为列表数据类型。这是因为 元组类型 是 python 语言中特有的数据类型,json 作为一个通用格式,无法识别元组类型。所以在针对元组类型进行序列化的时候,会先将 元组类型 ,先转为 列表,再进行序列化处理;同样的在进行反序列化处理时,就会将序列化后的 元组类型 ,又转成了 列表类型 。(类型的转换,不影响对数据的使用)
bool 、None 类型的序列化与反序列化
示例如下:
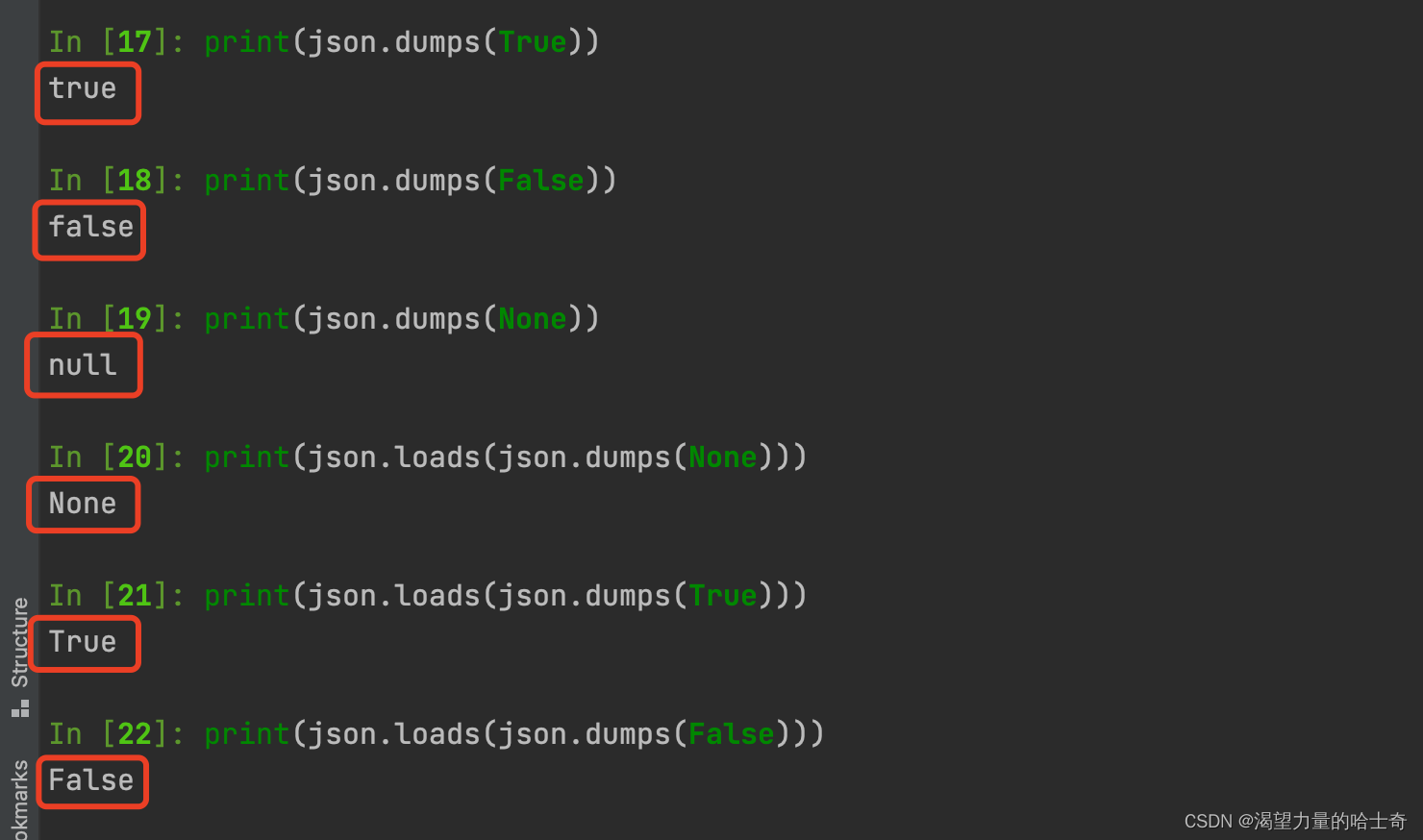
print(json.dumps(True)) # >>> 输出结果:true print(json.dumps(False)) # >>> 输出结果:false print(json.dumps(None)) # >>> 输出结果:null
从上述运行结果来看,bool 类型经过序列化处理后,变成了小写的 true、false;而 None 类型则变成了 小写的 null 。
之所以会这样,是因为在大多数的编程语言中, bool 类型都是小写的 true、false 。json 作为一个通用的序列化模块,也同样遵循着这种规则。(小写的 true、false 依然是字符串类型。 )
接下来我们再将上述的序列化处理后的 bool 、None 类型 进行反序列化处理
print(json.loads(json.dumps(None))) # >>> 输出结果:None print(json.loads(json.dumps(True))) # >>> 输出结果:True print(json.loads(json.dumps(False))) # >>> 输出结果:False
从执行结果我们看到,经过反序列化之后,bool、None 类型又被还原成了 python 可读的状态。
Python 中的pickle
pickle模块与json模块一样可以进行序列化与反序列化,区别在于 pickle 是 Python 内置的序列化模块,而且不像 json 那么通用,它只能用于 python 自身来使用,其他语言可能就无法处理了,但pickle模块的性能是要比 json 更好的。如果是仅仅用于 python 自身来使用,pckle 模块还是一个挺不错的选择哦。
dumps() 与 loads() 函数
| 方法名 | 参数 | 介绍 | 举例 | 返回值 |
|---|---|---|---|---|
| dumps | obj | 对象序列化 | json.dumps([1, 2, 3]) | 比特 |
| loads | str | 反序列化 | Json.loads(’[1, 2, 3]’) | 原始数据类型 |
注意:区别于 json ,pickle 模块的 dumps() 函数 返回的是 byte 类型 ,而 loads() 函数也仅支持 byte 类型的 pickle 序列进行反序列化的操作。
pickle模块的序列化与反序列化练习
pickle模块与json模块的用法是完全一致的,这里我们就不过多的演示,只针对 dict 类型演示一下即可。

json 模块 - 序列化小实战
需求:
创建一个 test.json 的空文件。
定义一个 write 函数写入 dict 数据类型的内容到 test.json 文件
定义一个 read 函数,将写入到 test.json 文件的内容,反序列化读取出来
# coding:utf-8
import json
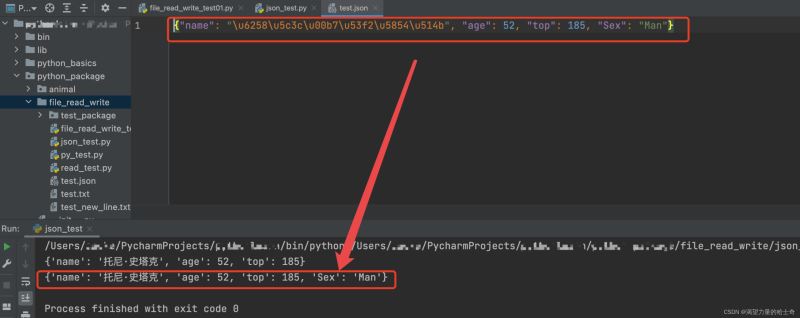
data = {'name': '托尼·史塔克', 'age': 52, 'top': 185}
def read(path): # 定义 read() 函数,读取 test.json 文件(返回对象为 反序列化后的内容)
with open(path, 'r') as f:
data = f.read()
return json.loads(data)
def write(path, data): # 定义 write() 函数,将 data 写入到 test.json 文件
with open(path, 'w') as f:
if isinstance(data, dict): # 判断 data 是否为字典类型。不是的情况下主动抛出异常
_data = json.dumps(data)
f.write(_data)
else:
raise TypeError('\'data\' 不是一个字典类型的数据')
return True
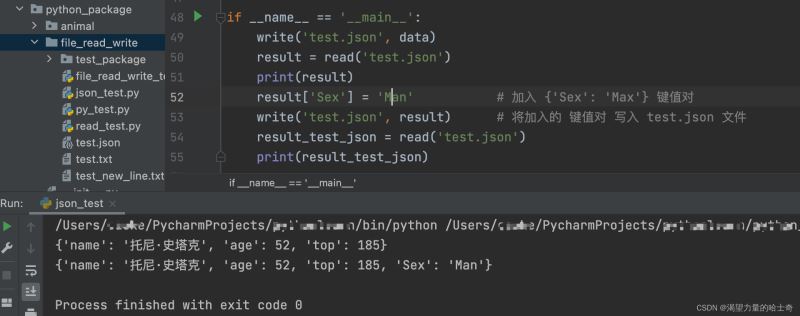
if __name__ == '__main__':
write('test.json', data)
result = read('test.json')
print(result)
result['Sex'] = 'Man' # 加入 {'Sex': 'Max'} 键值对
write('test.json', result) # 将加入的 键值对 写入 test.json 文件
result_test_json = read('test.json')
print(result_test_json)
执行结果如下:
总结:json的使用在我们的未来 工作中是非常高频的,所以大家一定要多多练习,加以掌握。
加载全部内容