Python加密模块
渴望力量的哈士奇 人气:0hashlib 模块
hashlib 模块的介绍
hashlib 模块中拥有很多的加密算法,我们并不需要关心加密算法的实现方法。只需要调用我们需要的加密函数,就可以帮助我们对数据进行加密。
它的加密算法有很多,不仅如此,hashlib 中很多加密算法加密难度很大,所以加密后的数据很难被破解(这里的很难被破解是相对而言的,比如MD5、sha1、mysql、ntlm就可以在 cmd5 通过穷举的方式进行明密文的对应查询。),这就是 hashlib 强大的地方。既然无法破解也就无法解密,所以hashlib 中的加密方法都是不可逆的。
hashlib 模块中的常用加密方法
接下来就让我们看一下 hashlib 中常用的加密算法:
| 函数名 | 参数 | 介绍 | 举例 | 返回值 |
|---|---|---|---|---|
| md5 | byte | md5算法加密 | hashlib.md5(b’hello’) | hash对象 |
| sha1 | byte | sha1算法加密 | hashlib.sha1(b’hello’) | hash对象 |
| sha256 | byte | sha256算法加密 | hashlib.sha256(b’hello’) | hash对象 |
| sha512 | byte | sha512算法加密 | hashlib.512(b’hello’) | hash对象 |
以上的加密函数都有一个 byte 类型的参数,通过调用对应的函数会返回一个 hash对象。所谓 hashlib 就是一种加密方式。
sha1、sha256、sha512 的区别就是 数值越高,被破解的概率就越低。
hashlib 模块生成加密字符串示例:
import hashlib hashobj = hashlib.md5(b'Hello_World') # 将 'Hello_World'以 byte 形式传入,通过 md5 加密 赋值给 hashobj 对象 result = hashobj.hexdigest() # hashobj 通过 hexdigest() 函数的16进制生成加密字符串赋值给 result print(result) # >>> 执行结果如下: # >>> 486b98e454e54f44e811b9c62857f8f7
hashlib模块情景练习
大家可能有一个疑问, hashlib 模块加密后的无法解密获取原始数据,那我们加密后的信息有什么用呢?实际上场景有很多,我们今天就来举例一个场景。
比如我们的用户需要某一个服务的帮助,用户每次请求服务都需要一个凭证。这个凭证信息是通过加密的方式生成的字符串,并且该加密方式是双方达成一致,标准相同的。当用户请求该服务的时候,带上这个加密的字符串,服务会通过响应的加密规范也生成一个字符串。如果用户带过来的凭证的字符串与服务计算出来的凭证的字符串完全一致,则证明用户请求的这个服务是一个合法的请求,反之则不合法。
那么定义这样一个认证签名字符串就需要两个数据和一个模块,模块就是 hashlib ,数据1就是 用户与服务之间达成共识的一个基础签名 ,我们定义它为 bash_sign ;数据2我们可以使用 用户请求服务生成凭证的时间戳,我们定义它为 user_timestamp 。
代码示例如下:
# coding:utf-8
import hashlib
import time
bash_sign = 'signature' # 定义一个基础签名变量
def user_request_client(): # TODO 用户签名
user_time = int(time.time()) # 获取用户请求服务生成凭证的时间戳 ;python 的时间戳是浮点类型,这里转成整型。
_token = '%s%s' % (bash_sign, user_time) # 定义一个加密之前的token,将 bash_sign 与 user_time 传入
hashobj = hashlib.sha1(_token.encode('utf-8')) # 由于参数是 byte 类型,所以我们需要将 _token 进行编码
user_token = hashobj.hexdigest() # 将 bash_sign 与 user_time 通过 sha1 加密的字符串 赋值给 user_token
return user_token, user_time
def service_check_token(token, user_timestamp): # TODO 服务器校验签名
_token = '%s%s' % (bash_sign, user_timestamp) # 服务器接收用户请求传入的 token 与 时间戳
service_token = hashlib.sha1(_token.encode('utf-8')).hexdigest() # 服务器的 token ,加密方式与用户请求加密方式一致
if token == service_token: # 校验加密串的合法性,若校验不通过,拒绝用户的服务请求
# print(token, '---', user_timestamp)
return True
else:
return False
if __name__ == '__main__':
need_help_token, timestamp = user_request_client()
# time.sleep(1) # 取消注释后,时间错不一致则会 签名校验不通过
# result = service_check_token(need_help_token, time.time())
result = service_check_token(need_help_token, timestamp)
if result == True:
print('用户请求服务签名校验通过,服务器提供对应服务')
else:
print('用户请求服务签名校验未通过,服务器拒绝提供对应服务')
# >>> 执行结果如下:
# >>> 用户请求服务签名校验通过,服务器提供对应服务
所以这一种验证需要两个方面,第一个就是我们生成传入的 token 以及 时间戳,第二个就是 token 是否是按照我们定义好的标准生成的;
这两个不管是那一个出错了,服务器校验签名都是不通过。这也是 hashlib 模块 常用的场景之一,大家也可以尝试拓展一下思维,还有哪些场景适用于这种不可逆的算法。
base64 模块
base64 模块的介绍
base64 加密模块也是一种通用型的加密算法,与之前我们讲的 json 模块一样,在很多编程语言中都有 base64模块且功能基本相同。 所以在任何编程语言中,都可以将base64加密的字符串进行解密。
既然都可以进行解密,那么带来的问题就是没有安全可言了。其实不然,我们自然有办法去解决。稍后我们通过一个小练习来解决这个问题。
base64 模块 模块中的常用方法
| 函数名 | 参数 | 介绍 | 举例 | 返回值 |
|---|---|---|---|---|
| encodestring | byte | 进行base64加密 | base64.encodestring(b’string’) | byte |
| decodestring | byte | 进行base64解密 | base64.decodestring(b’c3RyaW5n\n’) | byte |
| encodebytes | byte | 进行base64加密 | base64.encodebytes(b’string’) | byte |
| decodebytes | byte | 进行base64解密 | base64.decodebytes(b’c3RyaW5n\n’) | byte |
注意:encodestring()函数 与 decodestring() 函数 虽然从名字上来看是对 字符串 进行 加密解密,但是在用法上需要对字符串进行 byte 类型的转换,然后再执行对应的加密解密操作。
encodebytes()函数 与 decodebytes() 函数 功能、参数、返回值 与字符串加解密一致,实际上在 python3.x 中,官方更推荐使用着一组函数进行加密和解密。
base64 模块的情景练习
接下来我们看一下 base64 模块的 加解密演示那里:
注意:由于无论如何我们都需要通过 byte 类型进行数据的加密与解密,所以我们可以对加密、解密进行一个封装。
# coding:utf-8
import base64
def encode(data): # 编码函数
if isinstance(data, str): # 判断传入的 data 的数据类型
data = data.encode('utf-8')
elif isinstance(data, bytes):
data = data
else:
raise TypeError('传输的 \'data\' 参数需为 bytes 或 str 类型')
# print(base64.encodebytes(data))
# print(base64.encodebytes(data).decode('utf-8'))
return base64.encodebytes(data).decode('utf-8') # 加密后的 data 格式为byte类型,需要进行解码为字符串,参考上两行代码
def decone(data):
if not isinstance(data, bytes):
raise TypeError('传输的 \'data\' 参数需为 bytes 类型')
return base64.decodebytes(data).decode('utf-8')
if __name__ == '__main__':
result = encode('signature')
print('base64 编码后的结果为:', result)
new_result = decone(result.encode('utf-8'))
print('base64 解码后的结果为:', new_result)
# >>> 执行结果如下:
# >>> base64 编码后的结果为: c2lnbmF0dXJl
# >>> base64 解码后的结果为: signature
但是就像上文我们提及的一样,既然所有人都知道 base64 的加密方式与解密方式,那我们该如何是好呢?其实也很简单,那就是对我们的 base64 加密的密文进行字符串替换的二次输出。(所谓的二次输出,其实就是二次转换的过程。)
比如我们定义三个字符串专门用作加密后的某个字符的替换,代码示例如下:
# coding:utf-8
import base64
replace_one = '$'
replace_two = '%'
replace_three = '='
def encode(data): # 编码函数
if isinstance(data, str): # 判断传入的 data 的数据类型
data = data.encode('utf-8')
elif isinstance(data, bytes):
data = data
else:
raise TypeError('传输的 \'data\' 参数需为 bytes 或 str 类型')
# print(base64.encodebytes(data))
# print(base64.encodebytes(data).decode('utf-8'))
_data = base64.encodebytes(data).decode('utf-8') # 加密后的 data 格式为byte类型,需要进行解码为字符串,参考上两行代码
_data = _data.replace('c', replace_one).replace('2', replace_two).replace('l', replace_three) # 替换 'c'、'2'、'l'
return _data
def decone(data):
if not isinstance(data, bytes):
raise TypeError('传输的 \'data\' 参数需为 bytes 类型')
return base64.decodebytes(data).decode('utf-8')
if __name__ == '__main__':
result = encode('signature')
print('base64 编码后的结果为:', result)
new_result = decone(result.encode('utf-8'))
print('base64 解码后的结果为:', new_result)
执行结果如下:
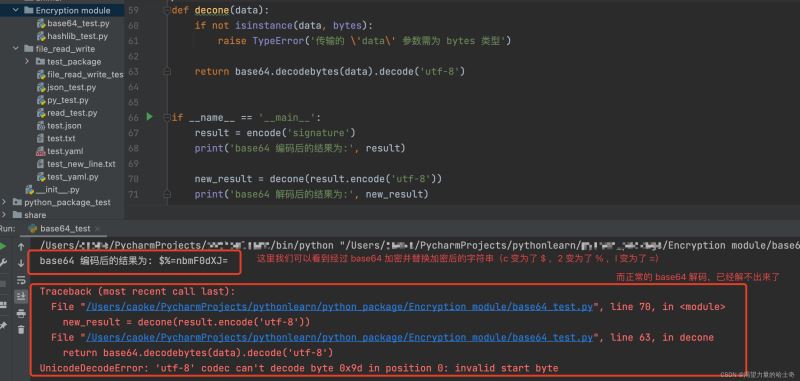
既然加密进行了二次转换,那么解密的时候同样需要进行二次转换才行,所以我们需要重构一下 decone() 函数。
def decone(data):
if not isinstance(data, bytes):
raise TypeError('传输的 \'data\' 参数需为 bytes 类型')
replace_one_decone = replace_one.encode('utf-8') # 需要将二次转换的变量已 byte 的形式进行解码
replace_two_decone = replace_two.encode('utf-8')
replace_three_decone = replace_three.encode('utf-8')
data = data.replace(replace_one_decone, b'c').replace(replace_two_decone, b'2').replace(replace_three_decone, b'l')
return base64.decodebytes(data).decode('utf-8')
运行结果如下:
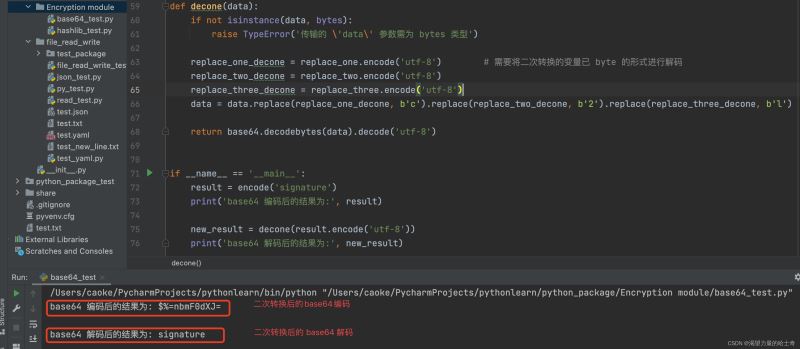
小节:通过这种方法,只有具体的开发人员与使用的业务人员才知道这种二次替换的方式,需要通过那些字符进行加密或者解密。从而提高了数据传输的安全性。
加载全部内容