Pytorch F.interpolate数组采样
视觉萌新、 人气:0什么是上采样
上采样,在深度学习框架中,可以简单的理解为任何可以让你的图像变成更高分辨率的技术。 最简单的方式是重采样和插值:将输入图片input image进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值bilinear等插值方法对其余点进行插值。
Unpooling是在CNN中常用的来表示max pooling的逆操作。这是从2013年纽约大学Matthew D. Zeiler和Rob Fergus发表的《Visualizing and Understanding Convolutional Networks》中引用的:因为max pooling不可逆,因此使用近似的方式来反转得到max pooling操作之前的原始情况;
F.interpolate——数组采样操作
torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None, recompute_scale_factor=None)
功能:利用插值方法,对输入的张量数组进行上\下采样操作,换句话说就是科学合理地改变数组的尺寸大小,尽量保持数据完整。
输入:
- input(Tensor):需要进行采样处理的数组。
- size(int或序列):输出空间的大小
- scale_factor(float或序列):空间大小的乘数
- mode(str):用于采样的算法。'nearest'| 'linear'| 'bilinear'| 'bicubic'| 'trilinear'| 'area'。默认:'nearest'
- align_corners(bool):在几何上,我们将输入和输出的像素视为正方形而不是点。如果设置为True,则输入和输出张量按其角像素的中心点对齐,保留角像素处的值。如果设置为False,则输入和输出张量通过其角像素的角点对齐,并且插值使用边缘值填充用于边界外值,使此操作在保持不变时独立于输入大小scale_factor。
- recompute_scale_facto(bool):重新计算用于插值计算的 scale_factor。当scale_factor作为参数传递时,它用于计算output_size。如果recompute_scale_factor的False或没有指定,传入的scale_factor将在插值计算中使用。否则,将根据用于插值计算的输出和输入大小计算新的scale_factor(即,如果计算的output_size显式传入,则计算将相同 )。注意当scale_factor 是浮点数,由于舍入和精度问题,重新计算的 scale_factor 可能与传入的不同。
注意:
- 输入的张量数组里面的数据类型必须是float。
- 输入的数组维数只能是3、4或5,分别对应于时间、空间、体积采样。
- 不对输入数组的前两个维度(批次和通道)采样,从第三个维度往后开始采样处理。
- 输入的维度形式为:批量(batch_size)×通道(channel)×[可选深度]×[可选高度]×宽度(前两个维度具有特殊的含义,不进行采样处理)
- size与scale_factor两个参数只能定义一个,即两种采样模式只能用一个。要么让数组放大成特定大小、要么给定特定系数,来等比放大数组。
- 如果size或者scale_factor输入序列,则必须匹配输入的大小。如果输入四维,则它们的序列长度必须是2,如果输入是五维,则它们的序列长度必须是3。
- 如果size输入整数x,则相当于把3、4维度放大成(x,x)大小(输入以四维为例,下面同理)。
- 如果scale_factor输入整数x,则相当于把3、4维度都等比放大x倍。
- mode是’linear’时输入必须是3维的;是’bicubic’时输入必须是4维的;是’trilinear’时输入必须是5维的
- 如果align_corners被赋值,则mode必须是'linear','bilinear','bicubic'或'trilinear'中的一个。
- 插值方法不同,结果就不一样,需要结合具体任务,选择合适的插值方法。
补充:
一图看懂align_corners=True与False的区别,从4×4上采样成8×8。一个是按四角的像素点中心对齐,另一个是按四角的像素角点对齐。
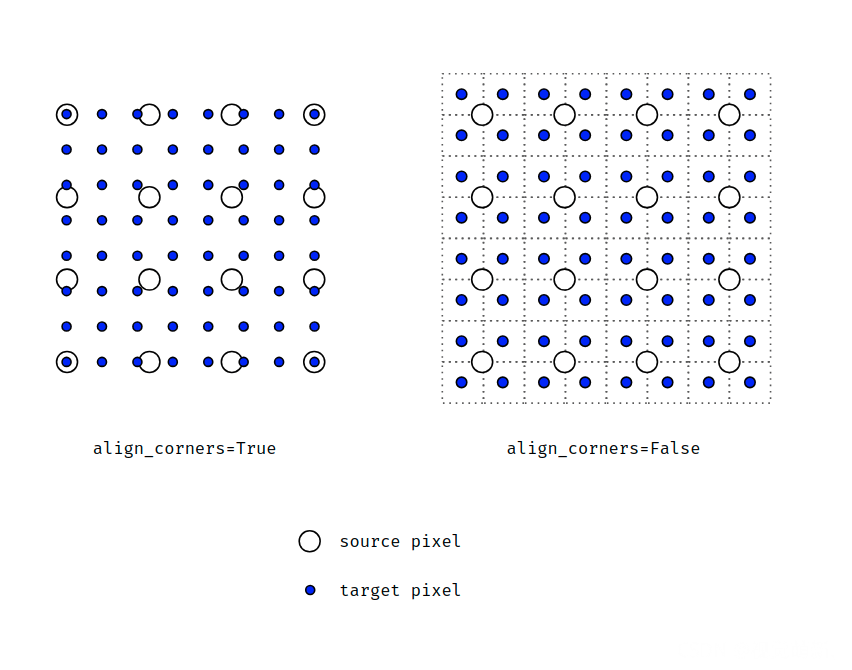
图片转自:https://discuss.pytorch.org/t/what-we-should-use-align-corners-false/22663/9
代码案例
一般用法
import torch.nn.functional as F
import torch
a=torch.arange(12,dtype=torch.float32).reshape(1,2,2,3)
b=F.interpolate(a,size=(4,4),mode='bilinear')
# 这里的(4,4)指的是将后两个维度放缩成4*4的大小
print(a)
print(b)
print('原数组尺寸:',a.shape)
print('size采样尺寸:',b.shape)
输出结果,一二维度大小不会发生变化
# 原数组
tensor([[[[ 0., 1., 2.],
[ 3., 4., 5.]],[[ 6., 7., 8.],
[ 9., 10., 11.]]]])
# 采样后的数组
tensor([[[[ 0.0000, 0.6250, 1.3750, 2.0000],
[ 0.7500, 1.3750, 2.1250, 2.7500],
[ 2.2500, 2.8750, 3.6250, 4.2500],
[ 3.0000, 3.6250, 4.3750, 5.0000]],[[ 6.0000, 6.6250, 7.3750, 8.0000],
[ 6.7500, 7.3750, 8.1250, 8.7500],
[ 8.2500, 8.8750, 9.6250, 10.2500],
[ 9.0000, 9.6250, 10.3750, 11.0000]]]])
原数组尺寸: torch.Size([1, 2, 2, 3])
size采样尺寸: torch.Size([1, 2, 4, 4])
# 规定三四维度放缩成4*4大小
size与scale_factor的区别:输入序列时
import torch.nn.functional as F
import torch
a=torch.arange(4*512*14*14,dtype=torch.float32).reshape(4,512,14,14)
b=F.interpolate(a,size=(28,56),mode='bilinear')
c=F.interpolate(a,scale_factor=(4,8),mode='bilinear')
print('原数组尺寸:',a.shape)
print('size采样尺寸:',b.shape)
print('scale_factor采样尺寸:',c.shape)
输出结果
原数组尺寸: torch.Size([4, 512, 14, 14])
size采样尺寸: torch.Size([4, 512, 28, 56])
# 第三维度放大成28,第四维度放大成56
scale_factor采样尺寸: torch.Size([4, 512, 56, 112])
# 第三维度放大4倍,第四维度放8倍
size与scale_factor的区别:输入整数时
import torch.nn.functional as F
import torch
a=torch.arange(4*512*14*14,dtype=torch.float32).reshape(4,512,14,14)
b=F.interpolate(a,size=28,mode='bilinear')
c=F.interpolate(a,scale_factor=4,mode='bilinear')
print('原数组尺寸:',a.shape)
print('size采样尺寸:',b.shape)
print('scale_factor采样尺寸:',c.shape)
输出结果
原数组尺寸: torch.Size([4, 512, 14, 14])
size采样尺寸: torch.Size([4, 512, 28, 28])
# 三四维度数组被放大成28*28
scale_factor采样尺寸: torch.Size([4, 512, 56, 56])
# 三四维度数组被放大了4倍
align_corners=True与False的区别
import torch.nn.functional as F import torch a=torch.arange(18,dtype=torch.float32).reshape(1,2,3,3) b=F.interpolate(a,size=(4,4),mode='bicubic',align_corners=True) c=F.interpolate(a,size=(4,4),mode='bicubic',align_corners=False) print(a) print(b) print(c)
输出结果,具体效果会因mode插值方法而异
tensor([[[[ 0., 1., 2.],
[ 3., 4., 5.],
[ 6., 7., 8.]],[[ 9., 10., 11.],
[12., 13., 14.],
[15., 16., 17.]]]])
# align_corners=True
tensor([[[[ 0.0000, 0.5741, 1.4259, 2.0000],
[ 1.7222, 2.2963, 3.1481, 3.7222],
[ 4.2778, 4.8519, 5.7037, 6.2778],
[ 6.0000, 6.5741, 7.4259, 8.0000]],[[ 9.0000, 9.5741, 10.4259, 11.0000],
[10.7222, 11.2963, 12.1481, 12.7222],
[13.2778, 13.8519, 14.7037, 15.2778],
[15.0000, 15.5741, 16.4259, 17.0000]]]])
# align_corners=False
tensor([[[[-0.2871, 0.3145, 1.2549, 1.8564],
[ 1.5176, 2.1191, 3.0596, 3.6611],
[ 4.3389, 4.9404, 5.8809, 6.4824],
[ 6.1436, 6.7451, 7.6855, 8.2871]],[[ 8.7129, 9.3145, 10.2549, 10.8564],
[10.5176, 11.1191, 12.0596, 12.6611],
[13.3389, 13.9404, 14.8809, 15.4824],
[15.1436, 15.7451, 16.6855, 17.2871]]]])
扩展:
在计算机视觉中,interpolate函数常用于图像的放大(即上采样操作)。比如在细粒度识别领域中,注意力图有时候会对特征图进行裁剪操作,将有用的部分裁剪出来,裁剪后的图像往往尺寸小于原始特征图,这时候如果强制转换成原始图像大小,往往是无效的,会丢掉部分有用的信息。所以这时候就需要用到interpolate函数对其进行上采样操作,在保证图像信息不丢失的情况下,放大图像,从而放大图像的细节,有利于进一步的特征提取工作。
官方文档
torch.nn.functional.interpolate:http://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.html?highlight=interpolate#torch.nn.functional.interpolate
总结
加载全部内容