PostgreSQL数据库事务插入删除更新操作
_jym 人气:0INSERT
使用INSERT语句可以向表中插入数据。
创建一个表:
CREATE TABLE ProductIns (product_id CHAR(4) NOT NULL, product_name VARCHAR(100) NOT NULL, product_type VARCHAR(32) NOT NULL, sale_price INTEGER DEFAULT 0, purchase_price INTEGER , regist_date DATE , PRIMARY KEY (product_id));
向表中插入数据:
INSERT语句格式:
里面的(列1,列2,…)称为列清单;(值1,值2,…)称为值清单。列清单和值清单个数要保持一致。
INSERT INTO <表名> (列1,列2,...) VALUES (值1,值2,...);
INSERT INTO ProductIns (product_id, product_name, product_type, sale_price, purchase_price, regist_date) VALUES ('0001', 'T恤' ,'衣服', 1000, 500, '2222-09-20');对表的所有列进行INSERT时,可省略列清单。从左到右将值清单里面数据赋给每一列。
INSERT INTO ProductIns VALUES ('0005', '铁锅', '厨房用具', 6800, 5000, '2222-01-15');插入NULL,直接在值清单里面写NULL就行,前提是插入NULL的列不能设置NOT NULL约束。
INSERT INTO ProductIns VALUES ('0006', '勺子', '厨房用具', 500, NULL, '2222-09-20');插入默认值:
前面创建ProductIns表设置sale_price默认值为0。在创建表的时候,设定了默认值,使用INSERT语句插入默认值的方法如下。
--显式方法设置默认值
INSERT INTO ProductIns VALUES ('0007', '筷子', '厨房用具', DEFAULT, 790, '2222-04-28');
隐式方法设置默认值,在列清单和值清单里面,省略设置为默认值的列。
如果省略未设置为默认值的列,该列的值将被置为NULL。这一列如果是NOT NULL约束,将报错。
--隐式方法设置默认值
INSERT INTO ProductIns (product_id, product_name, product_type, purchase_price, regist_date) VALUES ('0007', '筷子', '厨房用具', 790, '2222-04-28');
从其他表中复制数据:
创建一张和Product结构相同的表。
CREATE TABLE ProductCopy (product_id CHAR(4) NOT NULL, product_name VARCHAR(100) NOT NULL, product_type VARCHAR(32) NOT NULL, sale_price INTEGER , purchase_price INTEGER , regist_date DATE , PRIMARY KEY (product_id));
可以像下面把Product表中数据插入到ProductCopy表里。INSERT语句里面的SELECT语句,可以使用WHERE子句、GROUP BY子句等等。
INSERT INTO ProductCopy (product_id, product_name, product_type, sale_price, purchase_price, regist_date) SELECT product_id, product_name, product_type, sale_price, purchase_price, regist_date FROM Product;
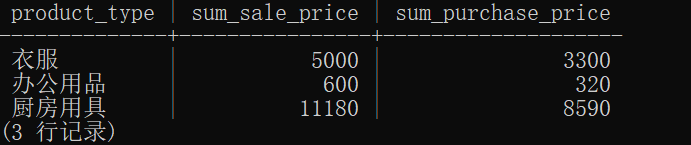
使用包含GROUP BY子句的SELECT语句进行插入:
创建一个以商品种类汇总的表。
CREATE TABLE ProductType (product_type VARCHAR(32) NOT NULL, sum_sale_price INTEGER , sum_purchase_price INTEGER , PRIMARY KEY (product_type));
通过下面,得到一个根据商品种类分组的表,并且计算出每个种类的价格的和。
INSERT INTO ProductType (product_type, sum_sale_price, sum_purchase_price) SELECT product_type, SUM(sale_price), SUM(purchase_price) FROM Product GROUP BY product_type;
DELETE
DROP TABLE语句,将表删除。
DELETE语句,删除表里面的数据。
DELETE语句的对象是行,不是列,无法只删除部分列的数据。
删除全部数据行:
格式 DELETE FROM <表名>; 例子 DELETE FROM Product;
删除部分数据行:
格式 DELETE FROM <表名> WHERE <条件>; 例子 DELETE FROM Product WHERE sale_price >= 2000;
UPDATE
UPDATE语句用于改变表中数据。
格式:
UPDATE <表名> SET <列名> = <表达式>;
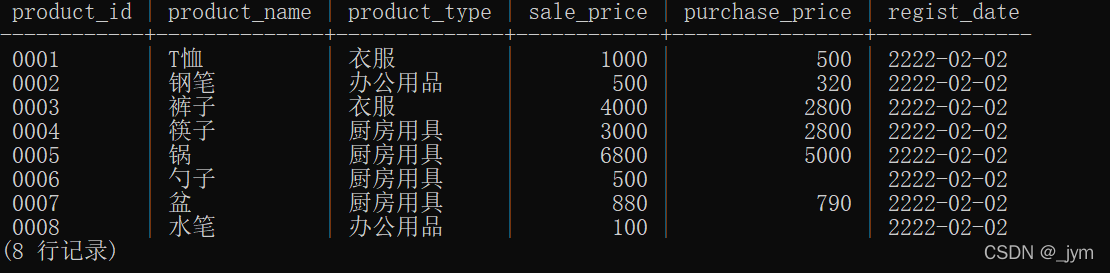
改变regist_date列的所有数据。
UPDATE Product SET regist_date = '2222-02-02';
修改后效果如下。
更新部分数据行:
UPDATE <表名> SET <列名> = <表达式> WHERE <条件>;
UPDATE Product SET sale_price = sale_price * 10 WHERE product_type = '厨房用具';
将列更新为NULL:
前提是这个列没有设置NOT NULL约束和主键约束。
UPDATE Product SET regist_date = NULL WHERE product_id = '0008';
同时更新多个列:
-- 使用逗号,所有DBMS中均可使用
UPDATE Product
SET sale_price = sale_price * 10,
purchase_price = purchase_price / 2
WHERE product_type = '厨房用具';
-- 列表形式,在某些DBMS中无法使用 UPDATE Product SET (sale_price, purchase_price) = (sale_price * 10, purchase_price / 2) WHERE product_type = '厨房用具';
事务
事务transaction,需要在同一处理单元中执行的一系列更新处理的集合。
有时候要对一个表进行多个处理。比如为了某件事,需要把a的价格增加,把b的价格减少,此时,多个处理是作为同一个处理单元执行的。这个时候就可以用事务来处理。
格式:
事务开始语句; DML语句1; DML语句2; ... 事务结束语句;
例子:
其中,用户需要明确指出事务的结束。结束事务的指令有COMMIT、ROLLBACK。
COMMIT,提交事务包含的更新处理。一旦提交,无法恢复事务开始前的状态。
ROLLBACK,取消事务包含的更新处理,相当于放弃保存,恢复事务开始前的状态。
事务在数据库连接建立时,已经悄悄开始。
不使用开始语句情况下,SQL Server、PostgreSQL、MySQL里面默认使用自动提交模式,每条SQL语句就是一个事务。
Oracle里面,是直到用户执行COMMIT或者ROLLBACK,算一个事务。
--PostgreSQL
BEGIN TRANSACTION;
UPDATE Product
SET sale_price = sale_price + 1000
WHERE product_name = 'T恤';
UPDATE Product
SET sale_price = sale_price - 1000
WHERE product_name = '裤子';
COMMIT;
DBMS的事务遵循ACID特性。
原子性Atomicity,事务结束时,其中的更新处理要么都执行(COMMIT),要么都不执行(ROLLBACK)。
一致性Consistency,事务中的处理,要满足数据库设置的约束,如主键约束、NOT NULL约束。
隔离性Isolation,不同事务之间互不干扰。一个事务向表中添加数据,没提交前,别的事务看不到新添加的数据。
持久性Durability,事务结束后,该时间点的数据状态会被保存。如果由于系统故障数据丢失,也能用一些方法恢复。
加载全部内容