kafka消息分区分配算法
温故知新之java 人气:0背景
kafka有分区机制,一个主题topic在创建的时候,会设置分区。如果只有一个分区,那所有的消费者都订阅的是这一个分区消息;如果有多个分区的话,那消费者之间又是如何分配的呢?
分配算法
RangeAssignor
定义
Kafka默认采⽤RangeAssignor的分配算法。
RangeAssignor策略的原理是按照消费者总数和分区总数进⾏整除运算来获得⼀个跨度,然 后将分区按照跨度进⾏平均分配,以保证分区尽可能均匀地分配给所有的消费者。对于每⼀个 Topic,RangeAssignor策略会将消费组内所有订阅这个Topic的消费者按照名称的字典序排序,然 后为每个消费者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配 ⼀个分区。
这种分配⽅式明显的⼀个问题是随着消费者订阅的Topic的数量的增加,不均衡的问题会越来 越严重,⽐如上图中4个分区3个消费者的场景,C0会多分配⼀个分区。如果此时再订阅⼀个分区 数为4的Topic,那么C0⼜会⽐C1、C2多分配⼀个分区,这样C0总共就⽐C1、C2多分配两个分区 了,⽽且随着Topic的增加,这个情况会越来越严重。
源码分析
public class RangeAssignor extends AbstractPartitionAssignor {
....
@Override
public Map> assign(Map partitionsPerTopic, Map subscriptions) {
// 1. 获取每个topic被多少个consumer订阅了
Map<String,List<String>> consumersPerTopic = consumersPerTopic(subscriptions);
// 2. 存储最终的分配⽅案
Map<String,List<String>> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet())
assignment.put(memberId, new ArrayList());
for (Map.Entry> topicEntry : consumersPerTopic.entrySet()) {
String topic = topicEntry.getKey();
List consumersForTopic = topicEntry.getValue();
// 3. 每个topic的partition数量
Integer numPartitionsForTopic = partitionsPerTopic.get(topic);
if (numPartitionsForTopic == null)
continue;
Collections.sort(consumersForTopic);
// 4. 表示平均每个consumer会分配到多少个partition
int numPartitionsPerConsumer = numPartitionsForTopic / consumersForTopic.size();
// 5. 平均分配后还剩下多少个partition未被分配
int consumersWithExtraPartition = numPartitionsForTopic % consumersForTopic.size();
List partitions = AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic);
// 6. 这⾥是关键点,分配原则是将未能被平均分配的partition分配到前 consumersWithExtraPartition个consumer
for (int i = 0, n = consumersForTopic.size(); i < n; i++) {
int start = numPartitionsPerConsumer * i + Math.min(i, consumersWithExtraPartition);
int length = numPartitionsPerConsumer + (i + 1 > consumersWithExtraPartition ? 0 : 1); assignment.get(consumersForTopic.get(i)).addAll(partitions.subList(start, start + length));
}
}
return assignment;
}
}场景
可以完全平均分配
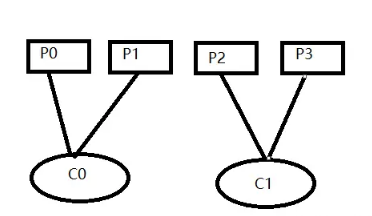
无法完全平均分配,排序靠前分的更多
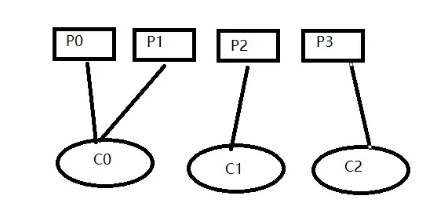
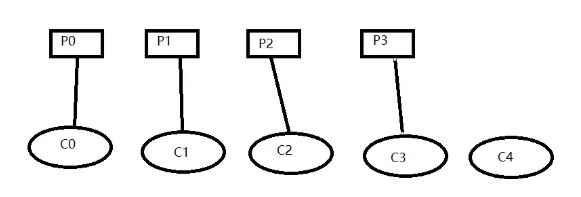
消费者数量大于分区数量,排名靠前先分得,排名靠后未分得分区
RoundRobinAssignor
定义
RoundRobinAssignor的分配策略是将消费组内订阅的所有Topic的分区及所有消费者进⾏排序后尽 量均衡的分配(RangeAssignor是针对单个Topic的分区进⾏排序分配的)。如果消费组内,消费者订阅 的Topic列表是相同的(每个消费者都订阅了相同的Topic),那么分配结果是尽量均衡的(消费者之间 分配到的分区数的差值不会超过1)。
源码分析
package org.apache.kafka.clients.consumer;
public class RoundRobinAssignor extends AbstractPartitionAssignor {
@Override
public Map> assign(Map partitionsPerTopic, Map subscriptions) {
<Map> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet()) assignment.put(memberId, new ArrayList()); // 1. 环状链表,存储所有的consumer,⼀次迭代完之后⼜会回到原点
CircularIterator assigner = new CircularIterator<> (Utils.sorted(subscriptions.keySet())); // 2. 获取所有订阅的topic的partition总数 for (TopicPartition partition : allPartitionsSorted(partitionsPerTopic, subscriptions)) {
final String topic = partition.topic();
while (!subscriptions.get(assigner.peek()).topics().contains(topic))
assigner.next();
assignment.get(assigner.next()).add(partition);
}
return assignment;
}
.... }场景
无法完全平均分配,排序靠前分的更多

StickyAssignor
定义
尽管RoundRobinAssignor已经在RangeAssignor上做了⼀些优化来更均衡的分配分区,但是在⼀些情况下依旧会产⽣严重的分配偏差,从字⾯意义上看,Sticky是“粘性的”,可以理解为分配结果是带“粘性的”——每⼀次分配变更相对 上⼀次分配做最少的变动(上⼀次的结果是有粘性的) 其⽬标有两点:
- 分区的分配尽量的均衡
- 每⼀次重分配的结果尽量与上⼀次分配结果保持⼀致
场景
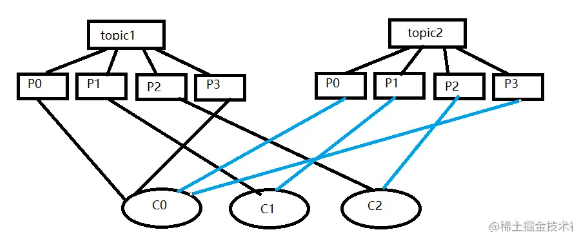
加载全部内容