Python正则表达式
渴望力量的哈士奇 人气:0要想成功的进行字符串的匹配需要使用到正则表达式模块,正则表达式匹配规则以及需要被匹配的字符串。在这三个条件中,模块与字符串都是准备好的,只有匹配规则异常的灵活,而今天这个章节就是认识一下正则表达式中的特殊字符,通过这些字符就可以针对我们想要的数据进行匹配。
正则表达式中的特殊字符
| 特殊字符 | 描述 |
|---|---|
| \d | 匹配任何十进制的数字,与[0-9]一致 |
| \D | 匹配任意非数字 |
| \w | 匹配任何字母数字下划线及unicode字符集 |
| \W | 匹配非字母数字的数据以及下划线 |
| \s | 匹配任何空格字符,与 [\n \t \r \v \f] 相同 |
| \S | 匹配任意非空字符 |
| \A | 匹配字符串的起始 |
| \Z | 匹配字符串的结束 |
| . | 匹配任何字符(除了 \n 之外);也叫做通配符 |
正则表达式的使用
接下来看一个小案例,帮助我们了解这些 特殊字符的使用方法 。
import re
test_data = "My name is Neo, I'm 30 years old." # 将一串字符串赋值给变量 test_data
result_int = re.findall('\d', test_data) # 使用 findall 函数并传入 '\d' 的匹配规则匹配 test_data(只匹配数字)
result_Space = re.findall('\s', test_data) # 使用 findall 函数并传入 '\d' 的匹配规则匹配 test_data(只匹配空格)
result_str = re.findall('\w', test_data) # 使用 findall 函数并传入 '\d' 的匹配规则匹配 test_data(匹配字符串)
result_str_start = re.findall('\AMy', test_data) # 匹配开头为 My 的字符串
result_str_start_null = re.findall('\AMya', test_data) # 匹配开头为 Mya 的字符串(不存在 mya ,返回空列表)
result_str_end = re.findall('old.\Z', test_data) # 匹配结尾为 old. 的字符串
result_str_end_null = re.findall('zold.\Z', test_data) # 匹配结尾为 zold. 的字符串(不存在 zold ,返回空列表)
result_all = re.findall('.', test_data) # 匹配除了 \n 之外的所有字符(包含空格)
print(result_int)
print(result_Space)
print(result_str) # 从结果上来看 \w 要比 \d 更高级一些,不仅匹配了 str,也匹配了 int(实际上这里的int依然是字符串)
print(result_str_start)
print(result_str_start_null)
print(result_str_end)
print(result_str_end_null)
# >>> 执行结果如下
# >>> ['3', '0']
# >>> [' ', ' ', ' ', ' ', ' ', ' ', ' ']
# >>> ['M', 'y', 'n', 'a', 'm', 'e', 'i', 's', 'N', 'e', 'o', 'I', 'm', '3', '0', 'y', 'e', 'a', 'r', 's', 'o', 'l', 'd']
# >>> ['My']
# >>> []
# >>> ['old.']
# >>> []
# >>> ['M', 'y', ' ', 'n', 'a', 'm', 'e', ' ', 'i', 's', ' ', 'N', 'e', 'o', ',', ' ', 'I', "'", 'm', ' ', '3', '0', ' ', 'y', 'e', 'a', 'r', 's', ' ', 'o', 'l', 'd', '.']
正则小案例 - 1
1、定义一个函数,判断传入参数是否包含有数字。
2、定义一个函数,判断传入参数是否含有数字,如果有则移除。
import re
def have_number(data): # 定义一个判断是否存在数字的函数
result = re.findall('\d', data) # 利用 re 模块的 findall 函数的 \d 规则判断传入的 data 是否存在数字
print(result)
for i in result: # 利用 for 循环 判断 result 的结果,如果存在返回 True ;反之返回 False
return True
return False
def remove_number(data):
result = re.findall('\D', data)
print(result)
return ' '.join(result)
if __name__ == '__main__':
test_data_1 = "My name is Neo, I'm 30 year's old."
test_data_2 = "it's a beautiful day to be with you"
result = have_number(test_data_1)
print(result)
result = remove_number(test_data_1)
print(result)
result = re.findall('\W', test_data_2) # 匹配非字母数字的数据以及下划线
print(result)
运行结果如下图:

正则小案例 - 2
1、定义一个 startwith 函数 判断传入数据是否是字符串的开头
2、定义一个 endwith 函数 判断传入数据是否是字符串的结尾
import re
def startswith(sub, data):
_sub = '\A{}'.format(sub)
result = re.findall(_sub, data)
for i in result:
return True
return False
def endswith(sub, data):
_sub = '{}\Z'.format(sub)
result = re.findall(_sub, data)
if len(result) == 0:
return False
else:
return True
if __name__ == '__main__':
result = startswith('My', test_data_1)
print(result)
result = endswith('old.', test_data_2)
print(result)
执行结果如下:

正则小案例 - 3
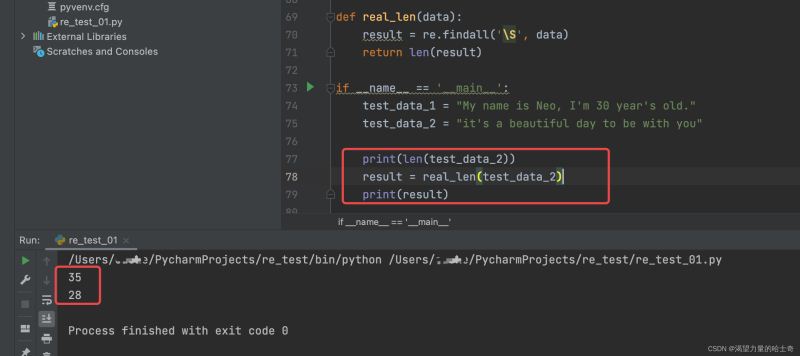
1、python 内置函数 len() 是可以获取到字符串的长度的,但是当字符串中存在着空格符号的时候也会计算在长度内。
2、利用正则的知识,定义一个计算字符串真实长度的函数
import re
def real_len(data):
result = re.findall('\S', data)
return len(result)
if __name__ == '__main__':
test_data_1 = "My name is Neo, I'm 30 year's old."
test_data_2 = "it's a beautiful day to be with you"
print(len(test_data_2))
result = real_len(test_data_2)
print(result)
运行结果如下:
加载全部内容