Redis 批量设置过期时间
王中阳Go 人气:0合理的使用缓存策略对开发同学来讲,就好像孙悟空习得自在极意功一般~
Redis如何批量设置过期时间呢?
不要说在foreach中通过set()函数批量设置过期时间
我们引入redis的PIPLINE,来解决批量设置过期时间的问题。
PIPLINE的原理是什么?
未使用pipline执行N条命令

使用pipline执行N条命令
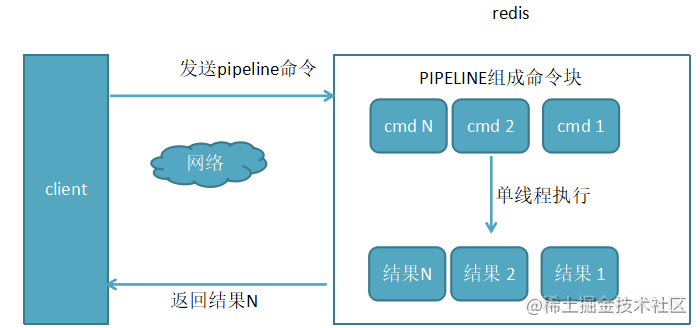
通过图例可以很明显的看出来PIPLINE的原理:
客户端通过PIPLINE拼接子命令,只需要发送一次请求,在redis收到PIPLINE命令后,处理PIPLINE组成的命令块,减少了网络请求响应次数。
网络延迟越大PIPLINE的优势越能体现出来
拼接的子命令条数越多使用PIPLINE的优势越能体现出来
注意:并不是拼接的子命令越多越好,N值也有是上限的,当拼接命令过长时会导致客户端等待很长时间,造成网络堵塞;我们可以根据实际情况,把大批量命令拆分成几个PIPLINE执行。
代码封装
//批量设置过期时间
public static function myPut(array $data, $ttl = 0)
{
if (empty($data)) {
return false;
}
$pipeline = Redis::connection('cache')
->multi(\Redis::PIPELINE);
foreach ($data as $key => $value) {
if (empty($value)) {
continue;
}
if ($ttl == 0) {
$pipeline->set(trim($key), $value);
} else {
$pipeline->set(trim($key), $value, $ttl);
}
}
$pipeline->exec();
}
项目实战
需求描述
- 打开APP,给喜欢我的人发送我的上线通知(为了避免打扰,8小时内重复登录不触发通知)
- 每个人每半小时只会收到一次这类上线通知(即半小时内就算我喜欢的1万人都上线了,我也只收到一次喜欢的人上线通知)
要点分析
- 合理使用缓存,减少DB读写次数
- 不仅要减少DB读写次数,也要减少Redis的读写次数,使用PIPLINE
代码实现解析
- canRecall() 写的比较优雅,先判断是否已发送的标记,再判断HouseOpen::getCurrentOpen(),因为HouseOpen::getCurrentOpen()是要查询DB计算的,这种代码要尽可能少的被执行到,减少DB查询。
- array_diff() 取差集的思路,获得需要推送的人
封装工具类
<?php
namespace App\Model\House;
.
.
.
class HouseLikeRecallUser
{
protected $_userid = '';
protected $_availableUser = [];
protected $_recallFlagKey = '';
const TYPE_TTL_HOUSE_LIKE_RECALL = 60 * 30; //半小时后可以再次接收到喜欢的xxx进入通知
const TYPE_TTL_HOUSE_LIKE_RECALL_FLAG = 60 * 60 * 8; //8小时重复登录不触发
//初始化 传入setRecalled 的过期时间
public function __construct($userid)
{
$this->_userid = $userid;
//登录后给喜欢我的人推送校验:同一场次重复登录不重复发送
$this->_recallFlagKey = CacheKey::getCacheKey(CacheKey::TYPE_HOUSE_LIKE_RECALL_FLAG, $this->_userid);
}
//设置当前用户推送标示
public function setRecalled()
{
Cache::put($this->_recallFlagKey, 1, self::TYPE_TTL_HOUSE_LIKE_RECALL_FLAG);
}
//获取当前用户是否触发推送
public function canRecall()
{
$res = false;
if (empty(Cache::get($this->_recallFlagKey))) {
$houseOpen = HouseOpen::getCurrentOpen();
if ($houseOpen['status'] == HouseOpen::HOUSE_STATUS_OPEN) {
$res = true;
}
}
return $res;
}
//获取需要推送用户
public function getAvailableUser()
{
//获得最近喜欢我的用户
$recentLikeMeUser = UserRelationSingle::getLikeMeUserIds($this->_userid, 100, Utility::getBeforeNDayTimestamp(7));
//获得最近喜欢我的用户的 RECALL缓存标记
foreach ($recentLikeMeUser as $userid) {
$batchKey[] = CacheKey::getCacheKey(CacheKey::TYPE_HOUSE_LIKE_RECALL, $userid);
}
//获得最近喜欢我的且已经推送过的用户
$cacheData = [];
if (!empty($batchKey)) {
$cacheData = Redis::connection('cache')->mget($batchKey);
}
//计算最近喜欢我的用户 和 已经推送过的用户 的差集:就是需要推送的用户
$this->_availableUser = array_diff($recentLikeMeUser, $cacheData);
return $this->_availableUser;
}
//更新已经推送的用户
public function updateRecalledUser()
{
//批量更新差集用户
$recalledUser = [];
foreach ($this->_availableUser as $userid) {
$cacheKey = CacheKey::getCacheKey(CacheKey::TYPE_HOUSE_LIKE_RECALL, $userid);
$recalledUser[$cacheKey] = $userid;
}
//批量更新 设置过期时间
self::myPut($recalledUser, self::TYPE_TTL_HOUSE_LIKE_RECALL);
}
//批量设置过期时间
public static function myPut(array $data, $ttl = 0)
{
if (empty($data)) {
return false;
}
$pipeline = Redis::connection('cache')
->multi(\Redis::PIPELINE);
foreach ($data as $key => $value) {
if (empty($value)) {
continue;
}
if ($ttl == 0) {
$pipeline->set(trim($key), $value);
} else {
$pipeline->set(trim($key), $value, $ttl);
}
}
$pipeline->exec();
}
}
调用工具类
public function handle()
{
$userid = $this->_userid;
$houseLikeRecallUser = new HouseLikeRecallUser($userid);
if ($houseLikeRecallUser->canRecall()) {
$recallUserIds = $houseLikeRecallUser->getAvailableUser();
$houseLikeRecallUser->setRecalled();
$houseLikeRecallUser->updateRecalledUser();
//群发推送消息
.
.
.
}
}
总结
不同量级的数据需要不同的处理办法,减少网络请求次数,合理使用缓存,是性能优化的必经之路。
进一步思考
如果我喜欢的1万人同时上线(秒级并发),我只收到一个消息推送,要避免被通知轰炸,怎么解决这类并发问题呢?
加载全部内容