pandas删除没列名的列
肖永威 人气:8前言
实际工作中,偶尔遇到如下情况,例如使用Pandas计算如下相关系数,并把结果写入Excel文件中。
correlations = df.corr(method='pearson',min_periods=1) #计算特征之间的相关系数矩阵
correlations.to_excel('dcorr202002.xlsx')
当再次读取Excel文件时,出现了没有列名的列。
import pandas as pd
correlations= pd.read_excel('dcorr202002.xlsx')
correlations
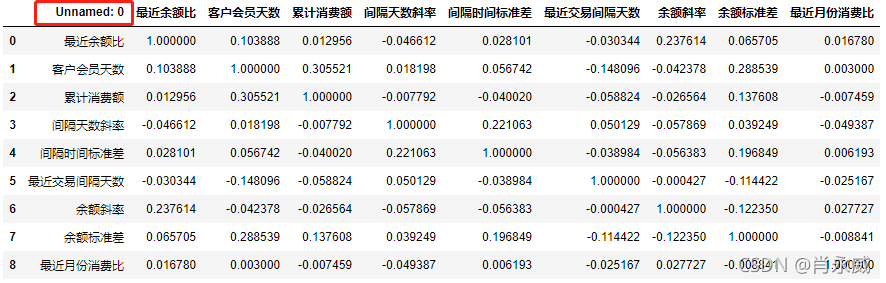
没有列名一般是说原表中没有列名,但在pandas读出来的时候是有列名的,一般的命名规则为:
Unnamed:x
x-表示未命名或重名的第x个列。
如何删除这个没有列名的列呢?
方法一:通过筛选列的方式,留存正常的列。
print(correlations.columns)
col = correlations.columns.tolist()
col.remove('Unnamed: 0')
print(col)
correlations1 = correlations[col]
correlations1
Index(['Unnamed: 0', '最近余额比', '客户会员天数', '累计消费额', '间隔天数斜率', '间隔时间标准差',
'最近交易间隔天数', '余额斜率', '余额标准差', '最近月份消费比'],
dtype='object')
['最近余额比', '客户会员天数', '累计消费额', '间隔天数斜率', '间隔时间标准差', '最近交易间隔天数',
'余额斜率', '余额标准差', '最近月份消费比']

方法二:直接删除列。
correlations2 = correlations.drop(columns='Unnamed: 0') correlations2
结果同上,略。
pandas删除列名中包含某些字符的列
>>> df = df[df.columns.drop(list(df.filter(regex='Test')))]
总结
加载全部内容