Docker cgroup
神技圈子 人气:0前言
进程在系统中使用CPU、内存、磁盘等计算资源或者存储资源还是比较随心所欲的,我们希望对进程资源利用进行限制,对进程资源的使用进行追踪。这就让cgroup的出现成为了可能,它用来统一将进程进行分组,并在分组的基础上对进程进行监控和资源控制管理。
什么是cgroup
Linux CGroup(Linux Contral Group),它其实是Linux内核的一个功能,它是Linux下的一种将进程按组进行管理的机制。最开始是由Google工程师Paul Menage和Rohit Seth于2006年发起的,最早起名叫进程容器。在2007之后随着容器得提出,为了避免混乱重命名为cgroup,并且被合并到了内核2.6.24版本中去了。
在用户层看来,cgroup技术就是把系统中的所有进程组织成一颗一颗独立的树,每棵树都包含系统的所有进程,树的每个节点是一个进程组,而每颗树又和一个或者多个subsystem关联。树主要用来将进程进行分组,而subsystem用来对这些组进行操作。
cgroup的组成
cgroup主要包含以下两个部分
- subsystem: 一个subsystem就是一个内核模块,它被关联到一颗cgroup树之后,就会在树节点进行具体的操作。subsystem经常被称作"resource controller",因为它主要被用来调度或者限制每个进程组的资源,但是这个说法不完全准确,因为有时我们将进程分组只是为了做一些监控,观察一下他们的状态,比如perf_event subsystem。
- hierarchy:一个hierarchy可以理解为一棵cgroup树,树的每个节点就是一个进程组,每棵树都会与多个subsystem关联。在一颗树里面,会包含Linux系统中的所有进程,但每个进程只能属于一个节点(进程组)。系统中可以有很多颗cgroup树,每棵树都和不同的subsystem关联,一个进程可以属于多颗树,即一个进程可以属于多个进程组,这些进程组和不同的subsystem关联。
可以通过查看/proc/cgroup目录查看当前系统支持哪些subsystem关联
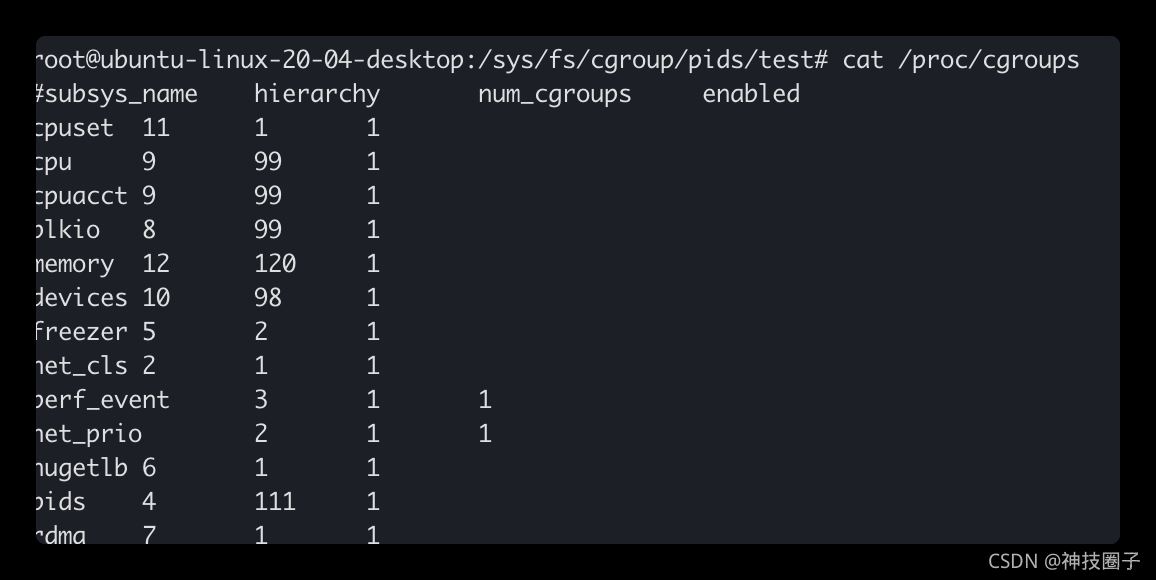
第一列:表示subsystem名
第二列:表示关联到的cgroup树的ID,如果多个subsystem关联到同一颗cgroup树,那么它们的这个字段将一样。比如图中的cpuset、cpu和cpuacct。
第三列:表示subsystem所关联的cgroup树中进程组的个数,即树上节点的个数。
cgroup提供的功能
它提供了如下功能
- Resource limitation:资源使用限制
- Prioritization:优先级控制
- Accounting:一些审计或者统计
- Control:挂起进程,恢复执行进程
一般我们可以用cgroup做以下事情
- 隔离一个进程集合(比如MySQL的所有进程),限定他们所占用的资源,比如绑定的核限制
- 为这组进程分配内存
- 为这组进程的分配足够的带宽及进行存储限制
- 限制访问某些设备
cgroup在Linux中表现为一个文件系统,运行如下命令
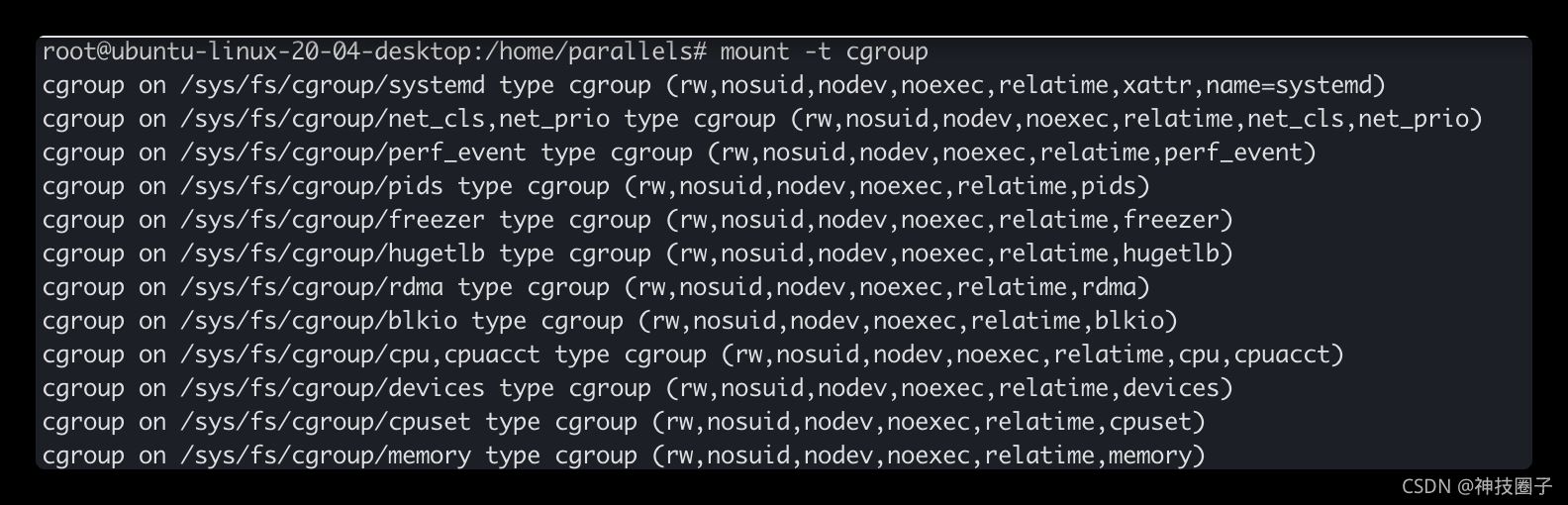
mount成功后,可以看到,在/sys/fs下有个cgroup目录,这个目录下有很多子系统。比如cpu、cpuset、blkio等。
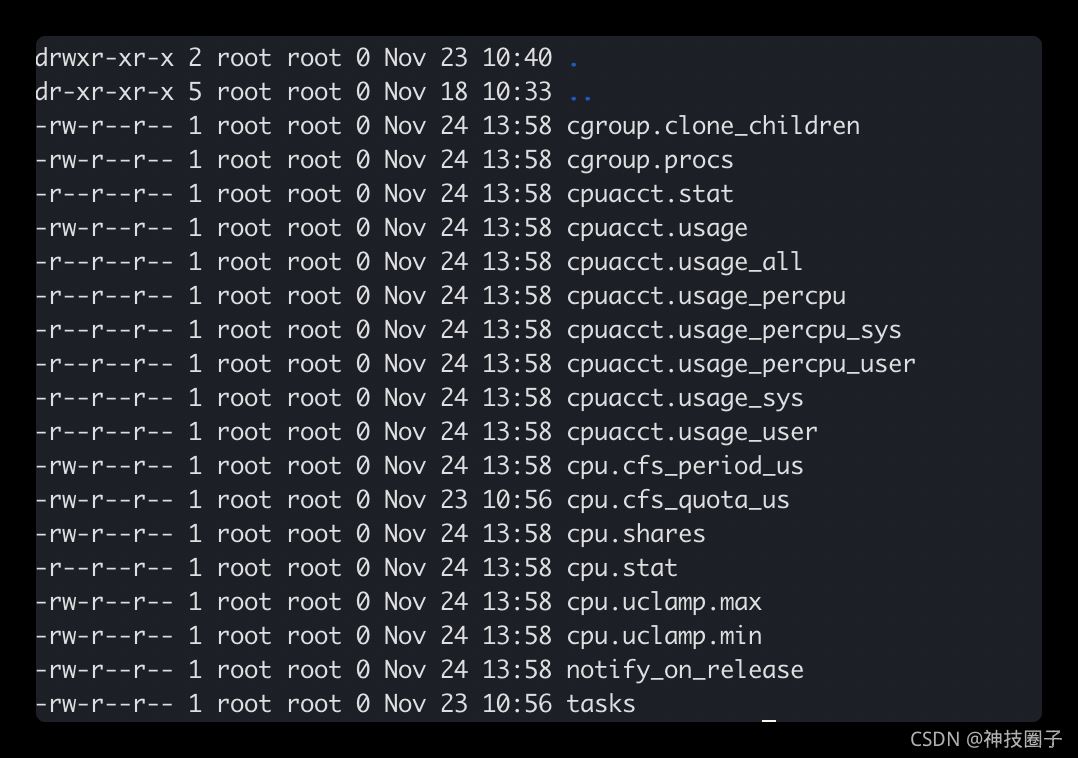
然后在/sys/fs/cgroup/cpu目录下建个子目录test,这个时候会发现在该目录下多了很多文件
限制cgroup中的CPU
在cgroup里面,跟CPU相关的子系统有cpusets、cpuacct和cpu。
其中cpuset主要用于设置CPU的亲和性,可以限制cgroup中的进程只能在指定的CPU上运行,或者不能在指定的CPU上运行,同时cpuset还能设置内存的亲和性。cpuacct包含当前cgroup所使用的CPU的统计信息。这里我们只说以下cpu。
然后我们在/sys/fs/cgroup/cpu下创建一个子group, 该目录下文件列表
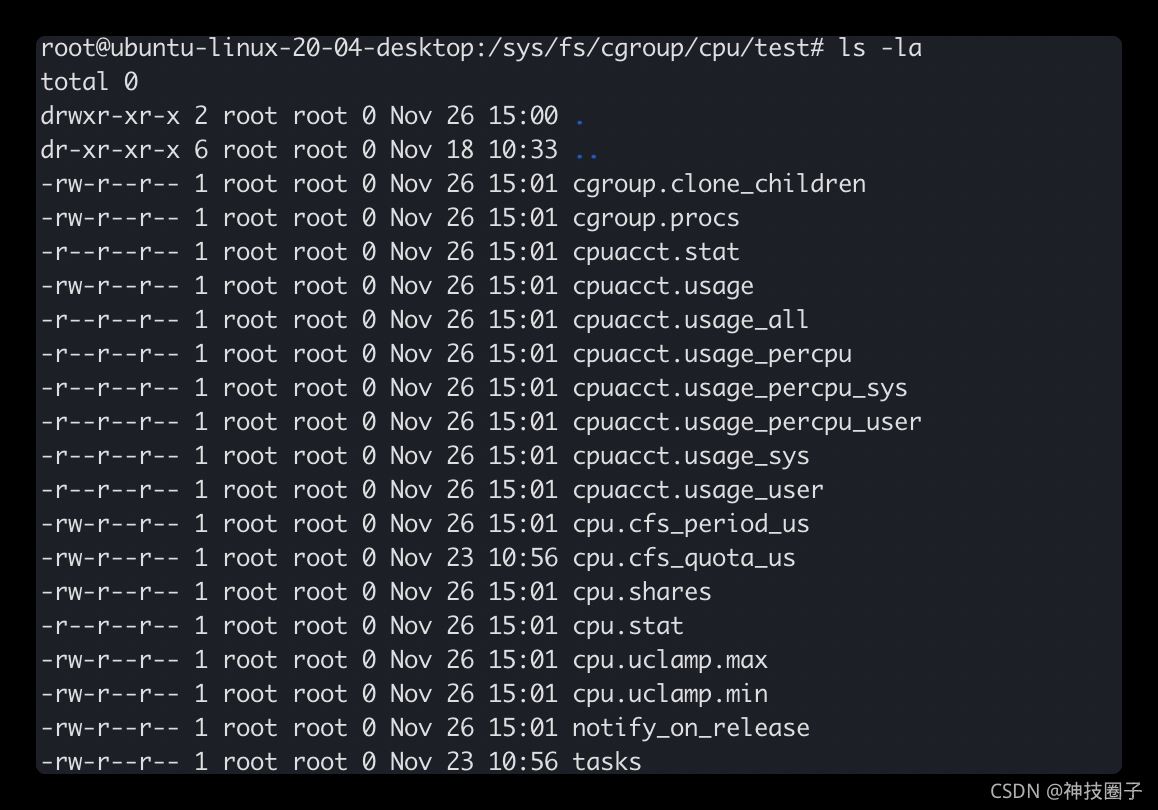
cpu.cfs_period_us用来配置时间周期长度,cpu.cfs_quota_us用来配置当前cgroup在设置的周期长度内所能使用的CPU时间数,两个文件配合起来设置CPU的使用上限。两个文件的单位都是微秒(us),cpu.cfs_period_us的取值范围为1毫秒(ms)到1秒(s),cpu.cfs_quota_us的取值大于1ms即可。
下面来举个例子讲解如何使用cpu限制
假如我们写了一个死循环
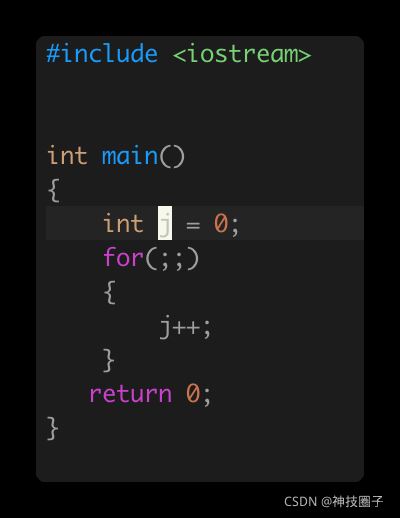
运行起来用top查看下占用率达到了100%

我们执行如下命令对cfs_quota_us进行设置
echo 20000 > /sys/fs/cgroup/cpu/test/cpu.cfs_quota_us
这条命令表示把进程的CPU利用率下降20%,然后把进程PID加入到cgroup中

再执行top可以看到cpu利用率下降了

限制cgroup中的内存
代码如果有bug,比如内存泄露等会榨干系统内存,让其它程序由于分配不了足够的内存而出现异常,如果系统配置了交换分区,会导致系统大量使用交换分区,从而系统运行很慢。
而cgroup对进程内存控制主要控制如下:
- 限制cgroup中所有进程使用的内存总量
- 限制cgroup中所有进程使用的物理内容+swap交换总量
- 限制cgroup中所有进程所能使用的内核内存总量及其它一些内核资源(CONFIG_MEMCG_KMEM)。
这里限制内核内存就是限制cgroup当前所使用的内核资源,包括当前进程的内核占空间,socket所占用的内存空间等。当内存吃紧时,可以阻止当前cgroup继续创建进程以及向内核申请分配更多的内核资源。
下面通过一个例子带大家理解cgroup做内存控制的
#include <iostream>
#include <sys/types.h>
#include <cstdlib>
#include <cstdio>
#include <string.h>
#include <unistd.h>
#define CHUNK_SIZE 512
int main()
{
int size = 0;
char *p = nullptr;
while(1)
{
if((p = (char*)malloc(CHUNK_SIZE))==nullptr)
{
break;
}
memset(p, 0, CHUNK_SIZE);
printf("[%u]-- [%d]MB is allocated ", getpid(), ++size);
sleep(1);
}
return 0;
}
首先,在/sys/fs/cgroup/memory下创建一个子目录即创建了一个子cgroup,比如这里我们创建了一个test目录
$mkdir /sys/fs/cgroup/memory/test
test目录包含以下文件
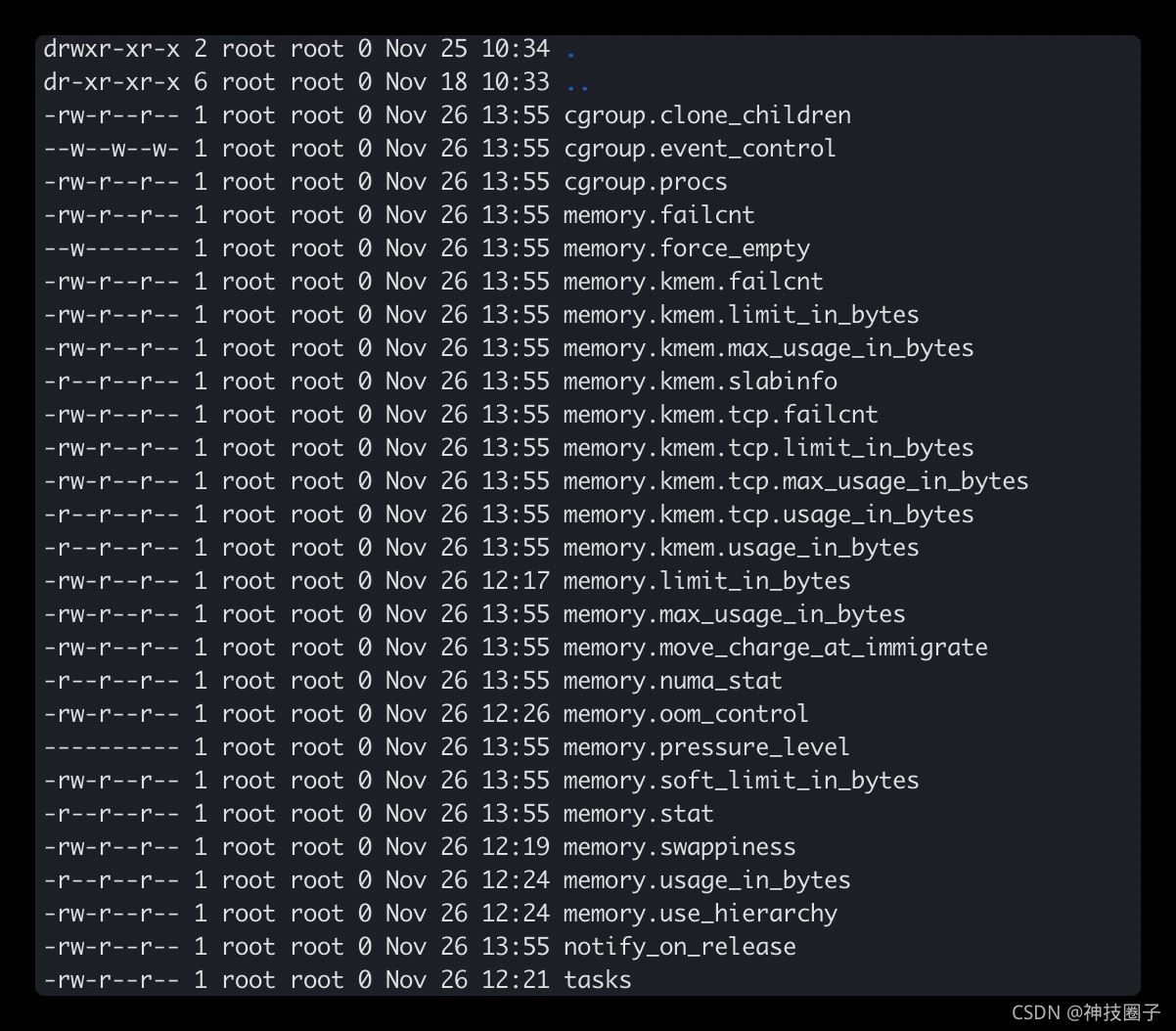
每个文件的作用大概介绍下:
| 文件 | 说明 |
|---|---|
| cgroup.event_control | 用于eventfd的接口 |
| memory.usage_in_bytes | 显示当前已用的内存 |
| memory.limit_in_bytes | 设置/显示当前限制的内存额度 |
| memory.failcnt | 显示内存使用量达到限制值的次数 |
| memory.max_usage_in_bytes | 历史内存最大使用量 |
| memory.soft_limit_in_bytes | 设置/显示当前限制的内存软额度 |
| memory.stat | 显示当前cgroup的内存使用情况 |
| memory.use_hierarchy | 设置/显示是否将子cgroup的内存使用情况统计到当前cgroup里面 |
| memory.force_empty | 触发系统立即尽可能的回收当前cgroup中可以回收的内存 |
| memory.pressure_level | 设置内存压力的通知事件,配合cgroup.event_control一起使用 |
| memory.swappiness | 设置和显示当前的swappiness |
| memory.move_charge_at_immigrate | 设置当进程移动到其他cgroup中时,它所占用的内存是否也随着移动过去 |
| memory.oom_control | 设置/显示oom controls相关的配置 |
| memory.numa_stat | 显示numa相关的内存 |
然后通过写文件memory.limit_in_bytes来设置限额。这里设置5M的限制,如下图所示

把上面示例进程加入这个cgroup,如下图所示

为了避免受swap空间的影响,设置swappiness为0来禁止当前cgroup使用swap,如下图所示

当物理内存达到上限后,系统的默认行为是kill掉cgroup中继续申请内存的进程。那么怎么控制这个行为呢?那就是配置memory.oom_control。这个文件里面包含了一个控制是否为当前cgroup启动OOM-killer的标识。如果写0到这个文件,将启动OOM-killer,当内核无法给进程分配足够的内存时,将会直接kill掉该进程;如果写1到这个文件,表示不启动OOM-killer,当内核无法给进程分配足够的内存时,将会暂停该进程直到有空余的内存之后再继续运行;同时,memory.oom_control还包含一个只读的under_oom字段,用来表示当前是否已经进入oom状态,也即是否有进程被暂停了。还有一个只读的killed_oom字段,用来表示当前是否有进程被kill掉了。
限制cgoup的进程数
cgroup中有一个subsystem叫pids,功能是限制cgroup及其所有子孙cgroup里面能创建的总的task数量。这里的task指通过fork和clone函数创建的进程,由于clone函数也能创建线程,所以这里的task也包含线程。
之前cgroup树是已经挂载好的,这里就直接创建子cgroup,取名为test。命令如下图所示

再来看看test目录下的文件
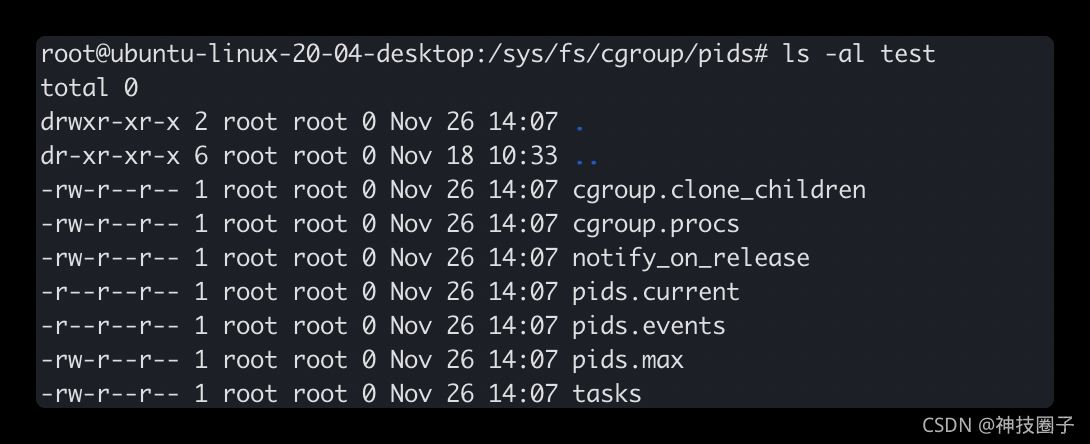
其中pids.current表示当前cgroup和其所有孙子cgroup现有的总的进程数量。

pids.max 当前cgroup和其所有孙子cgroup所允许创建的最大进程数量。

下面我们做个实验,将pids.max设置为1

然后将当前bash进程加入到该cgroup中

随便运行一个命令,由于在当前窗口pids.current已经等于pids.max了,所以创建进程失败

当前cgroup中的pids.current和pids.max代表了当前cgroup及所有子孙cgroup的所有进程,所以子孙cgroup中的pids.max大小不能超过父cgroup中的大小,如果超过了会怎么样?我们把pids.max设置为3

当前进程数为2

重新打开一个shell窗口,创建个孙子cgroup,将其中的pids.max设置为5

讲当前shell的bash进程写入croup.procs

回到原来的shell窗口随便执行一条命令可以看到执行失败
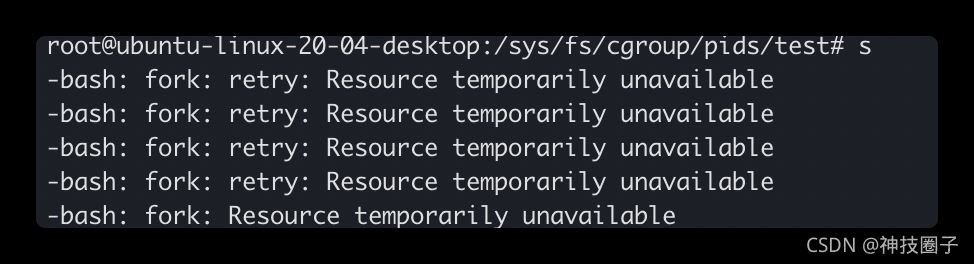
可以看到,子cgroup中的进程数不仅受制与自己的pids.max,还受制于祖先cgroup的pids.max
到此这篇关于一文带你彻底搞懂Docker中的cgroup的具体使用的文章就介绍到这了,更多相关Docker cgroup内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
加载全部内容