数据优化-多层索引
小旺不正经 人气:0一、多层索引
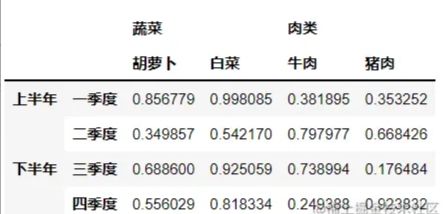
1.创建
环境:Jupyter
import numpy as np
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['上半年','上半年','下半年','下半年'],
['一季度','二季度','三季度','四季度']],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','白菜','牛肉','猪肉']])
display(a)
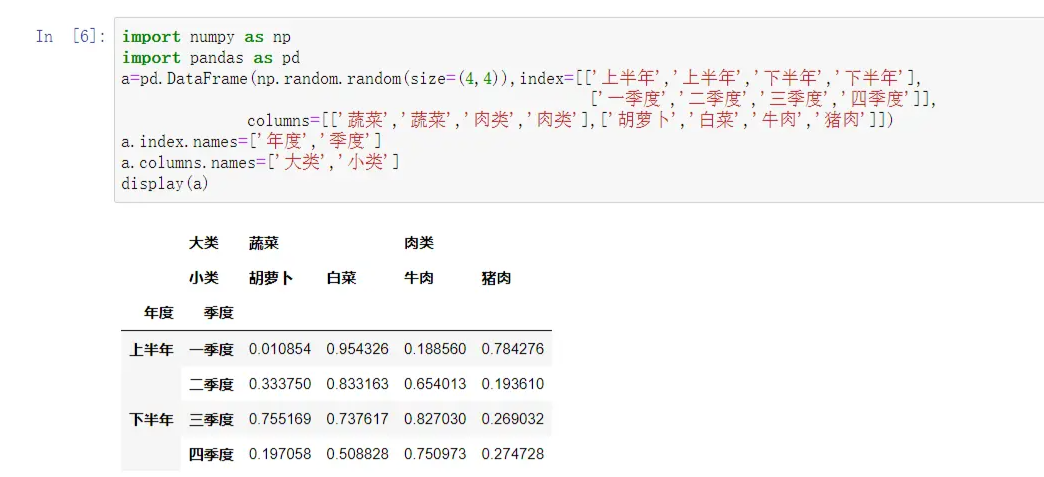
2.设置索引的名称
import numpy as np
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['上半年','上半年','下半年','下半年'],
['一季度','二季度','三季度','四季度']],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','白菜','牛肉','猪肉']])
a.index.names=['年度','季度']
a.columns.names=['大类','小类']
display(a)
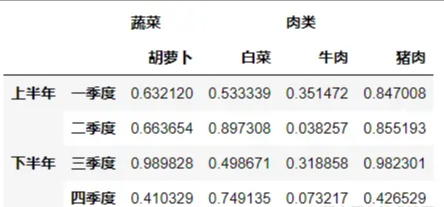
3.from_arrays( )-from_tuples()
import numpy as np
import pandas as pd
index=pd.MultiIndex.from_arrays([['上半年','上半年','下半年','下半年'],['一季度','二季度','三季度','四季度']])
columns=pd.MultiIndex.from_tuples([('蔬菜','胡萝卜'),('蔬菜','白菜'),('肉类','牛肉'),('肉类','猪肉')])
a=pd.DataFrame(np.random.random(size=(4,4)),index=index,columns=columns)
display(a)
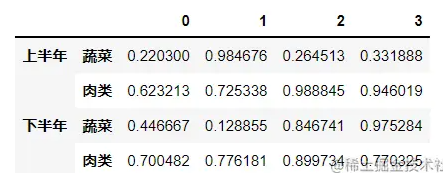
4.笛卡儿积方式
from_product() 局限性较大
import pandas as pd index = pd.MultiIndex.from_product([['上半年','下半年'],['蔬菜','肉类']]) a=pd.DataFrame(np.random.random(size=(4,4)),index=index) display(a)
二、多层索引操作
1.Series
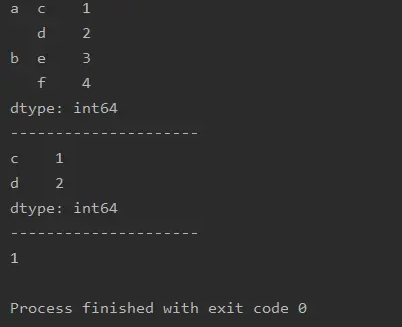
import pandas as pd
a=pd.Series([1,2,3,4],index=[['a','a','b','b'],['c','d','e','f']])
print(a)
print('---------------------')
print(a.loc['a'])
print('---------------------')
print(a.loc['a','c'])
import pandas as pd
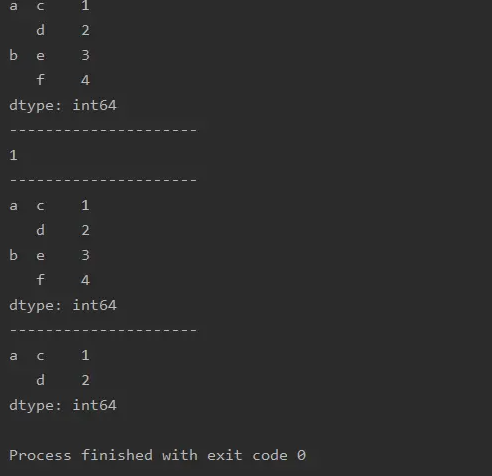
a=pd.Series([1,2,3,4],index=[['a','a','b','b'],['c','d','e','f']])
print(a)
print('---------------------')
print(a.iloc[0])
print('---------------------')
print(a.loc['a':'b'])
print('---------------------')
print(a.iloc[0:2])
2.DataFrame
import numpy as np
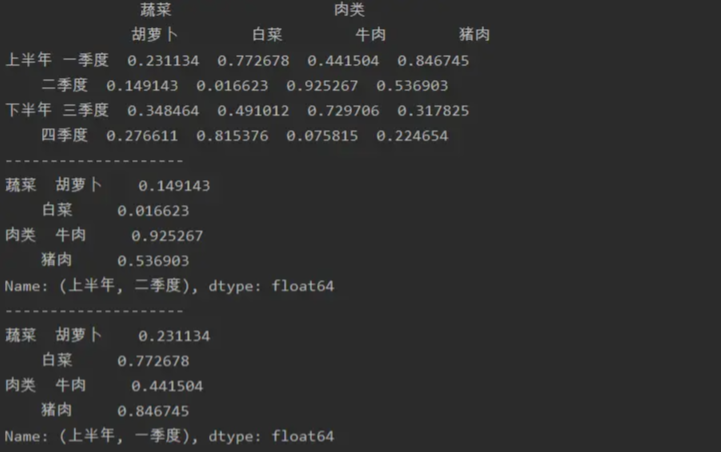
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['上半年','上半年','下半年','下半年'],
['一季度','二季度','三季度','四季度']],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','白菜','牛肉','猪肉']])
print(a)
print('--------------------')
print(a.loc['上半年','二季度'])
print('--------------------')
print(a.iloc[0])
3.交换索引
swaplevel( )
import numpy as np
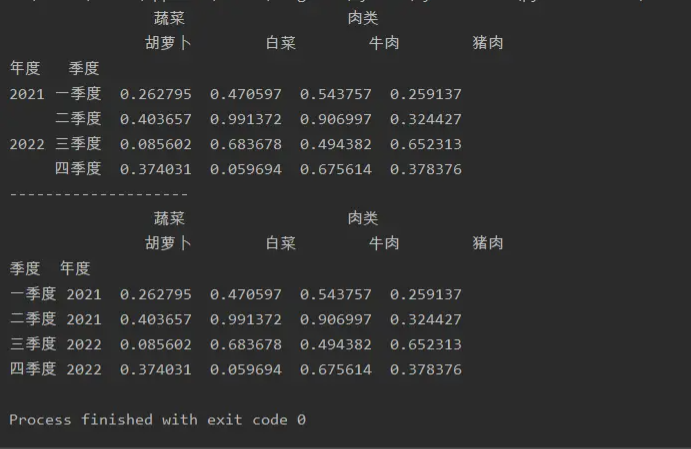
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['2021','2021','2022','2022'],
['一季度','二季度','三季度','四季度']],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','白菜','牛肉','猪肉']])
a.index.names=['年度','季度']
print(a)
print('--------------------')
print(a.swaplevel('年度','季度'))
4.索引排序
sort_index( )
level:指定根据哪一层进行排序,默认为最层inplace:是否修改原数据。默认为False
import numpy as np
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['2021','2021','2022','2022'],
[1,3,2,4]],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','白菜','牛肉','猪肉']])
a.index.names=['年度','季度']
print(a)
print('--------------------')
print(a.sort_index())
print('--------------------')
print(a.sort_index(level=1))
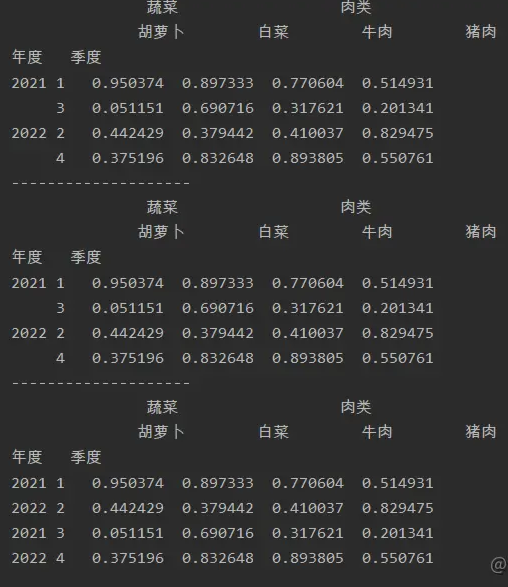
5.索引堆叠
stack( )
将指定层级的列转换成行
import numpy as np
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['2021','2021','2022','2022'],
[1,3,2,4]],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','胡萝卜','牛肉','牛肉']])
print(a)
print('--------------------')
print(a.stack(0))
print('--------------------')
print(a.stack(-1))
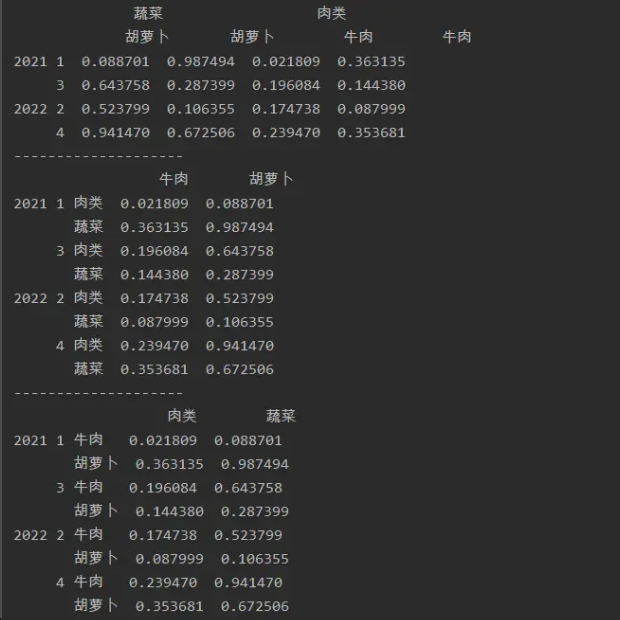
6.取消堆叠
unstack( )
将指定层级的行转换成列
fill_value:指定填充值。
import numpy as np
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['2021','2021','2022','2022'],
[1,3,2,4]],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','胡萝卜','牛肉','牛肉']])
print(a)
print('--------------------')
a=a.stack(0)
print(a)
print('--------------------')
print(a.unstack(-1))
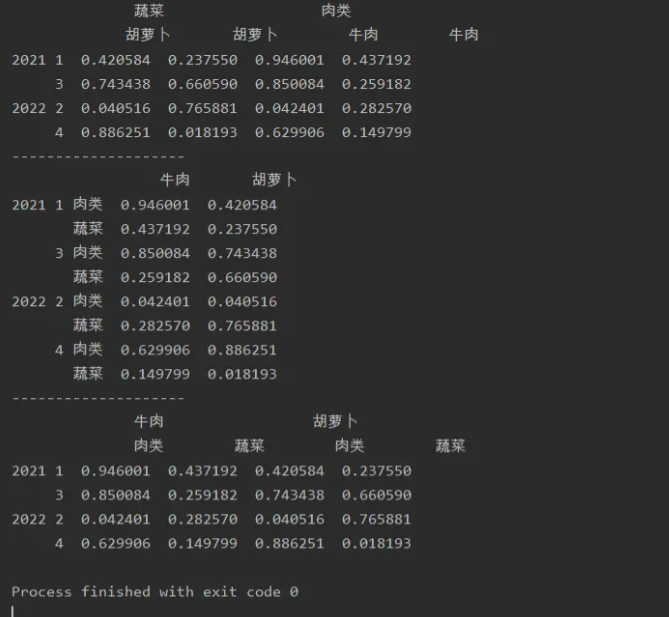
import numpy as np
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['2021','2021','2022','2022'],
[1,3,2,4]],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','胡萝卜','牛肉','牛肉']])
print(a)
print('--------------------')
a=a.stack(0)
print(a)
print('--------------------')
print(a.unstack(0,fill_value='0'))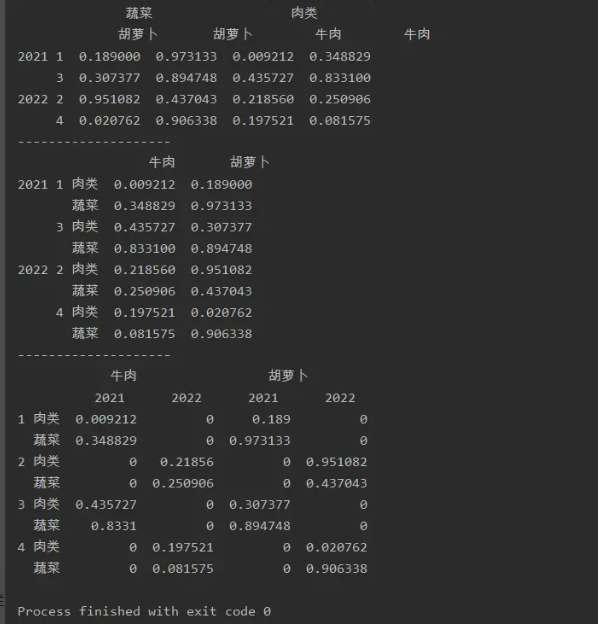
加载全部内容