opencv 行人检测
y1054765649 人气:0基于方向梯度直方图(HOG)/线性支持向量机(SVM)算法的行人检测方法中存在检测速度慢的问题,如下图所示,对一张400*490像素的图片进行检测要接近800毫秒,所以hog+svm的方法放在视频中进行行人检测时,每秒只能检测1帧图片,1帧/s根本不能达到视频播放的流畅性。
本文采用先从视频每帧的图像中提取出物体的轮廓(也可以对前后两针图片做差,只对有变化的部分进行检测,其目的一样,都是减少运算的面积),再对每个轮廓进行HOG+SVM检测,判断是否为行人。可以大大的缩减HOG+SVM的面积,经实测,检测速度可以达到10帧/S,可以勉强达到视频流畅的要求。
轮廓的提取用的是cv::findContours的API,感兴趣的可以自己去查看相关资料
首先介绍下方向梯度直方图。
在图像或者视频帧中,边缘方向密度分布可以很好地描述局部目标的形状和表象,也就是说通过 HOG特征,可以有效地将人体和复杂背景区分出来。对于行人检测中 HOG 特征提取的具体实现方法是: 将视频中的每一帧通过滑动窗口切割成很小的区域( Cell) ,通过计算每个区域面的方向梯度特征,得到每个区域的方向特征直方图,小区域再组成更大的区域,通过将区域的方向梯度特征组合起来并在块单元中进行归一化处理,就形成了一个 Block 内 HOG 描述子,遍历搜索所有的方向特征从而最终构成一个帧的 HOG 描述特征向量。算法的过程[3]分为:
①将一个视频的每一帧进行灰度化处理。把视频的每一帧彩色空间变成灰度空间,因为 HOG 中不需要彩色信息的帮助。
②对输入的视频的每一帧进行颜色空间的归一化。由于视频中人信息的复杂性,背影的灰暗程度以及光照的影响都对检测器的鲁棒性有一定的影响,归一化可以很大程度上降低这些的影响。这 里 使 用gamma 校正: 对像素值求其平方根( 降低数值大小) 。
③计算像素梯度。这是 HOG 特征检测中最重要的一个环节,通过像素的梯度方向直方图来描述像素的特征。特别注意的是我们不需要做平滑处理,因为平滑处理的本质就是迷糊图像,降低了像素边缘信息,因而就不能很好地提取边缘信息来表达特征。
④将图像划分成小 cell。这一步我们需要为计算梯度,建立梯度方向直方图定义一个载体,因此这里把图像分割成很小的区域,这里称为细胞单元,实验表明6 × 6 像素的细胞单元效果最佳。接着采用 9 个直方图来统计一个细胞单元里面的特征信息。360°不考虑
正负方向,把方向分成 9 份,如图 1 所示,称为 bin,也就是每一个 bin 对应 20°,这样就把梯度方向映射到直方图里面,9 个方向特征向量代表 9 个 bin,增幅就代表每一个 bin 的权值。
⑤统计每个 cell 的梯度直方图即可形成每个 cell的 descriptor。
⑥将每几个 cell 组成一个 block,一个 block 内所有 cell 的特征串联起来,便得到该 block 的 HOG 特征descriptor。
⑦将图像内所有 block 的 HOG 特征收集起来就可得到该图像特征向量。
支持向量机
支持向量机( Support Vector Machine) 就是风险降低到最小程度上,寻找最优的解决方案。视频检测特征分类中,就是针对低维空间的线性不可分问题,通过核函数映射到高维空间达到线性可分,再进行线性分割实现特征分类。
SVM 具有以下几个特点:
( 1) 小样本。
( 2) 非 线 性 问 题。即针对线性的不可分问题,SVM 通过松弛变量以及核函数进行解决。
( 3) 高维模式识别。在某些样本,例如密集型特征,可以达到几万甚至十几万的维数,如果不对样本进行降维,SVM 也能够找出支持向量样本,对这些特征训练出优秀的分类器。
视频检测代码:
void video_test() {
void display(Mat, vector<Rect>&);
//void Crop_picture();
//void train();
//void save_hard_example();
//Crop_picture(); //裁切负样本图片,每张负样本图片随机裁成10张
//train(); //训练正负样本
//save_hardexample() //根据正负样本得到的检测子,对INRIAPerson/Train/neg/中的图片进行测试,并将错检的样本保存
//train(); //训练正负样本及难例样本
//加载svm分类器的系数
HOGDescriptor hog; string str;
vector<float> detector;
/*ifstream fin("HOGDetectorForOpenCV.txt");
while (getline(fin, str))
{
detector.push_back(stringToNum<float>(str));
}
*/
vector<Rect> people;
VideoCapture capture(VideotestPath);
/*if (!capture.isOpened())
return -1;*/
Mat frame, foreground;
int num = 0;
Ptr<BackgroundSubtractorMOG2> mod = createBackgroundSubtractorMOG2();
while (true)
{
vector<Rect> rect6;
if (!capture.read(frame))
break;
mod->apply(frame, foreground, 0.01);
hog.setSVMDetector(HOGDescriptor::getDefaultPeopleDetector());
//hog.setSVMDetector(detector);
vector<Rect> rect5;
display(foreground, rect5);
vector<Rect> ret = rect5;
for (auto i = 0; i != ret.size(); i++)
{
Mat a = frame;
if (ret[i].x > 50 && ret[i].y > 50 && ret[i].x + ret[i].width <670 && ret[i].y + ret[i].height < 520)
{
ret[i].x = ret[i].x - 50;
ret[i].y = ret[i].y - 50; ret[i].width = ret[i].width + 100; ret[i].height = ret[i].height + 100;
}
Mat src(a(ret[i]));
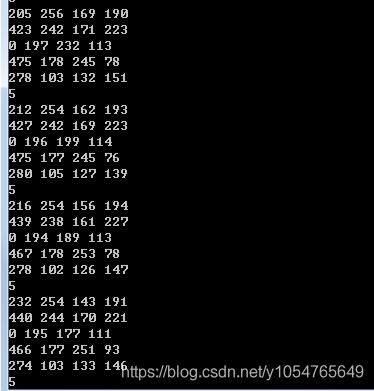
cout << ret[i].x << " " << ret[i].y << " " << ret[i].width << " " << ret[i].height << endl;
// imshow("aa", src); waitKey(0);
// cv::namedWindow("src", CV_WINDOW_NORMAL);
if (ret[i].width >= 64 && ret[i].height >= 128)
hog.detectMultiScale(src, people, 0, Size(4, 4), Size(0, 0), 1.07, 2);
//cout << people.size()<<endl;
for (size_t j = 0; j < people.size(); j++)
{
people[j].x += ret[i].x; people[j].y += ret[i].y;
rect6.push_back(people[j]);
//rectangle(frame, people[j], cv::Scalar(0, 0, 255), 2);
}
//imshow(" ", frame); waitKey(0);
}
//因为多尺度检测得到的结果矩形框较大,按比例缩减矩形框
for (auto h = 0; h != rect6.size(); h++)
{
rect6[h].x += cvRound(rect6[h].width*0.1);
rect6[h].width = cvRound(rect6[h].width*0.8);
rect6[h].y += cvRound(rect6[h].height*0.07);
rect6[h].height = cvRound(rect6[h].height*0.8);
rectangle(frame, rect6[h], cv::Scalar(0, 0, 255), 1);
//rect2[h] = boundingRect(frame);
}
imshow(" ", frame); waitKey(1);
}
waitKey();
}
提取轮廓的代码:
void display(Mat gray_diff, vector<Rect>& rect)
{
//Mat res = src.clone();
vector<vector<Point>> cts; //定义轮廓数组
findContours(gray_diff, cts, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_NONE); //查找轮廓,,模式为只检测外轮廓,并存储所有的轮廓点
//vector<Rect> rect; //定义矩形边框
for (int i = 0; i < cts.size(); i++)
{
if (contourArea(cts[i])>th_area) //计算轮廓的面积,排除小的干扰轮廓
//查找外部矩形边界
rect.push_back(boundingRect(cts[i])); //计算轮廓的垂直边界最小矩形
}
cout << rect.size() << endl; //输出轮廓个数
}
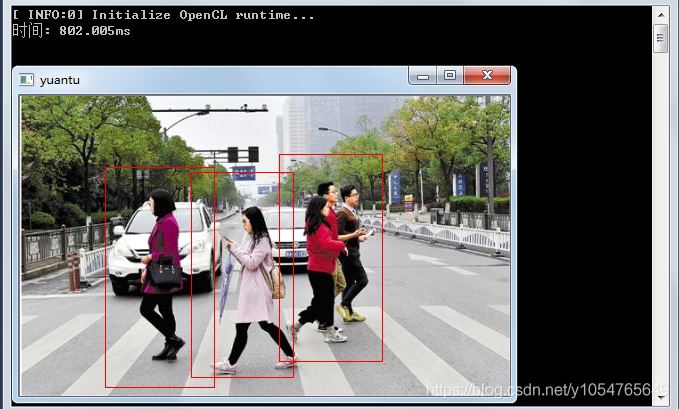
检测效果:

进行HOG+SVM的四个顶点像素坐标。可以看到每次运算的面积小了很多。
当然 ,是可以优化,比如每两帧图片检测一次,下一帧图片保持上一帧的检测结果。比如轮廓区域的面积怎么去合适的框起来,如何设定合适的阈值去滤掉小框,两个框重叠时,怎么去优化,减小进行运算的面积。本文只是给个思路,具体读者可以自己去实现。
贴下github 有兴趣的可以去读下 ,样本集用的INRIA行人检测数据集,训练过程就不详述了。
加载全部内容