mysql索引
一定会去到彩虹海的麦当 人气:0如果你想深入了解为什么mysql可以快速的进行检索数据,那么你一定要来了解一下mysql的索引原理
思维导图
简单理解
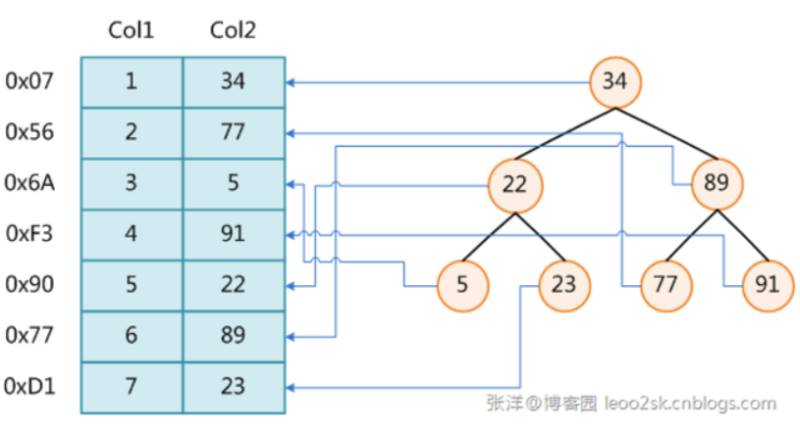
你可以把索引理解为一本书的目录,我们可以通过索引快速的找到我们需要的数据,大概就像下面这个图,索引就像是右边的二叉树,每个节点指向具体的数据的物理地址,先通过二叉树找到数据的位置,然后再去物理磁盘中获取数据。
但是不同的二叉树的特性不同,我们还要选择合适的树来作为索引,所以接下来就来学习一下各个树的特性
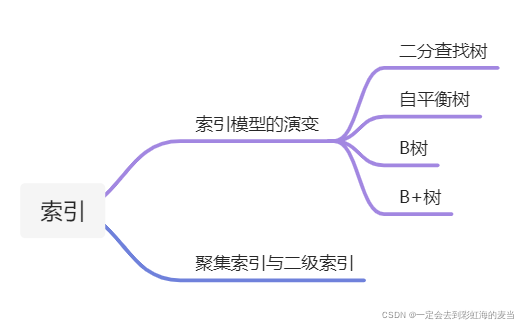
索引模型的演变
二叉查找树
二分查找树就是在数组的基础上,利用二分查找技巧,将用到的中间节点,作为指针。这样他的每个节点的左子树的值都小于该节点的值,每个节点右子树的值都大于该节点的值。在查找元素时,我们于根节点进行对比后,就能每次近乎一半的去除掉查找范围,可以极大的加快查找速度。

优点:
插入方便,不必连续排列
利用树的特新,查找很方便
缺点:
如果每次都是插入都是最大值,会导致其变成链表,查找复杂度增加
插入的元素越多,树的高度就会高,导致查询性能下降
自平衡二叉树
相比于二叉树来说,自平衡二叉树会通过左旋或者右旋来保证左子树跟右子树的高度差不超过一。这就很好解决了二分查找树变成链表的问题

但如果元素越多,树的高度还是很容易变的很高,这会导致查询效率变慢。为了解决这个问题,于是就出现了B树。
B树
B树的最大不同就是不再限制一个节点只有一个节点,而是允许有多个节点,这就是多叉树。并且B树所有的叶子节点必须在同一层次,也就是它们具有相同的深度
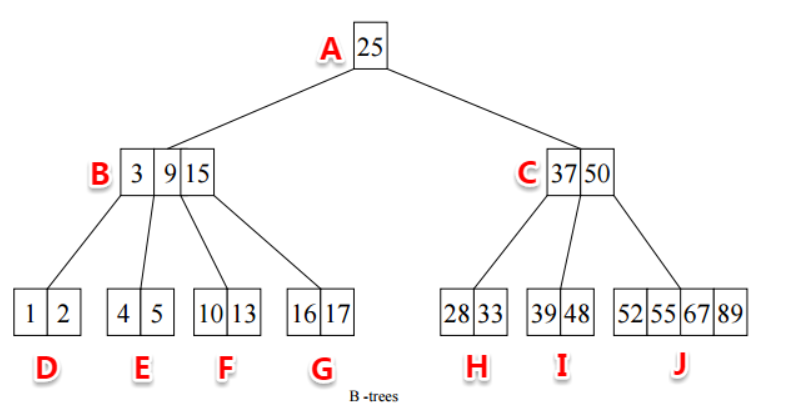
例如一个度为 d 的 B-Tree,设其索引 N 个 key,则其树高 h 的上限为 logn(N/2),检索一个 key,其查找节点个数的渐进复杂度为 O(logn((N+1)/2))。从这点可以看出,B-Tree 是一个非常有效率的索引数据结构。
局部性原理
而这种多个节点的结构,还可以很好的借助磁盘预读的特性。
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘 I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。程序运行期间所需要的数据通常比较集中。由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高 I/O 效率。
在B树中,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B树还需要使用如下技巧:<br />每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个节点只需一次I/O。
但是 B 树的每个节点都包含数据(索引+记录),而用户的记录数据的大小很有可能远远超过了索引数据,这就需要花费更多的磁盘 I/O 操作次数来读到「有用的索引数据。而且,在我们查询位于底层的某个节点(比如 A 记录)过程中,「非 A 记录节点」里的记录数据会从磁盘加载到内存,但是这些记录数据是没用的,我们只是想读取这些节点的索引数据来做比较查询,而「非 A 记录节点」里的记录数据对我们是没用的,这样不仅增多磁盘 I/O 操作次数,也占用内存资源。
B+树
Mysql普遍使用B+树来实现其索引结构,跟B树相比,B+树有以下几个不同点
叶子节点(最底部的节点)才会存放实际数据(索引+记录),非叶子节点只会存放索引;
所有索引都会在叶子节点出现,叶子节点之间构成一个有序链表;
非叶子节点的索引也会同时存在在子节点中,并且是在子节点中所有索引的最大(或最小)。
非叶子节点中有多少个子节点,就有多少个索引;
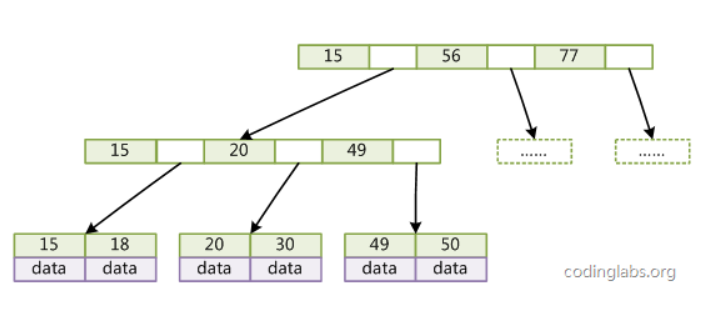
B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储即存索引又存记录的 B 树,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B 树更「矮胖」,查询底层节点的磁盘 I/O次数会更少。
B+作为多叉树,在有大量的冗余节点,在进行删除或者插入操作时都不会发生复杂的树的变形。
在数据库中,还在B+树的基础上进行优化,增加了顺序访问指针。做这个优化的目的是为了提高区间访问的性能,例如如果要查询 key 为从 18 到 49 的所有数据记录,当找到 18 后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。<br />而 B 树没有将所有叶子节点用链表串联起来的结构,因此只能通过树的遍历来完成范围查询,这会涉及多个节点的磁盘 I/O 操作,范围查询效率不如 B+ 树。因此,存在大量范围检索的场景,适合使用 B+树,比如数据库。而对于大量的单个索引查询的场景,可以考虑 B 树,比如 nosql 的MongoDB。
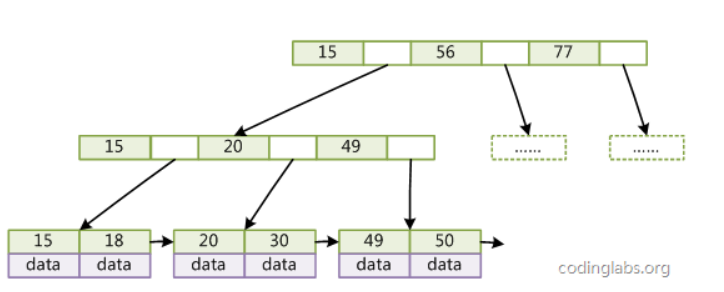
而在mysql中,B+ 树的叶子节点之间是用「双向链表」进行连接,这样的好处是既能向右遍历,也能向左遍历<br />
聚集索引与二级索引
聚集索引(主键索引):将数据与索引放到了一块,索引结构的叶子节点存储了行数据,找到索引也就找到了数据
二级索引(非主键索引):将数据与索引分开存储,索引结构的叶子节点存储的是主键的值
InnoDB 在创建聚簇索引时,会根据不同的场景选择不同的列作为索引:
如果有主键,默认会使用主键作为聚簇索引的索引键;
如果没有主键,就选择第一个不包含 NULL 值的唯一列作为聚簇索引的索引键;
在上面两个都没有的情况下,InnoDB 将自动生成一个隐式自增 id 列作为聚簇索引的索引键;
因为表的数据都是存放在聚集索引的叶子节点里,所以 InnoDB 存储引擎一定会为表创建一个聚集索引,且由于数据在物理上只会保存一份,所以聚簇索引只能有一个,而二级索引可以创建多个。
例如图中(ID,k)值分别为(100,1)、(200,2)、(300,3)、(500,5)和(600,6)
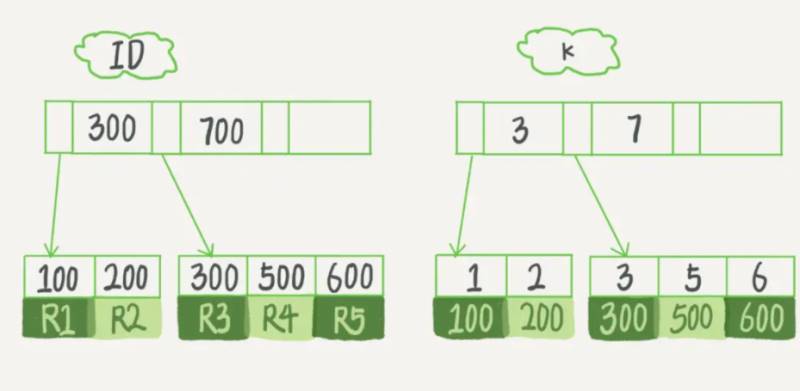
查询时的区别:
如果语句是select * from T where ID=500,即主键查询方式,则只需要搜索ID这棵B+树;
如果语句是select * from T where k=5,即普通索引查询方式,则需要先搜索k索引树,得到ID的值为500,再到ID索引树搜索一次。这个过程称为回表。
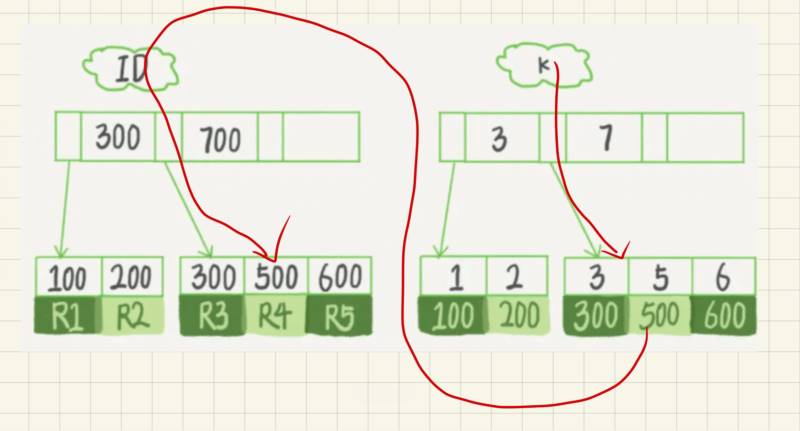
也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
总结
加载全部内容