c语言Hello World执行过程
不吃辣。 人气:0计算机的世界,就从hello,world开始吧!
#include <stdio.h>
int main()
{
printf("Hello World\n");
return 0;
}
“Hello World”,对于好兄弟们来说,都很熟悉吧,大学第一课、编程语言书本的第一个dmeo,基本都是用这个作为引子,这次我们也从hello,world开始进入计算机的世界遨游吧!
刚开始学这些东西的时候,比如用VC++, 都是鼠标点点,直接出来黑窗口,可以看到我们的执行结果,却不知,这一系列的背后,隐匿了很多我们不知道的细节,而这些东西都让VC++这类的集成开发环境帮我们做了(当很多东西被封装成简单的API给我们使用的时候,也同时证明了我们的可替代性变得越来越高,那怎么办?好好读这篇文章:)),有的工作了好几年的,也不见得知道Hello,World的执行过程,这次我们把它搞懂。
先来看一下整个C程序从写完代码,到执行所经历的步骤:

当我们在linux上输入如下指令的时候,VC++或者别的C的开发环境,就会在背后帮我们进行上面的动作。
$gcc hello.c $./a.out
预编译
通过预编译器,生成".i"文件
这个过程主要是处理源代码文件中以“#”开始的预编译指令,比如:"#include",“define”
对于我们的hello程序来说,会处理#include指令,将被包含的stdio.h文件插入到第一行我们的#include指令的位置上,但是我们的stdio.h可能还包含的别的#include,所以这个过程是递归进行的
如果我们有宏定义,比如#define,会展开所有的宏定义,比如:#define PI 3.14, 在预编译步骤中,会将#define删除,然后将所有PI替换成3.14
如果我们在代码中存在注释的时候,还会将注释进行删除,可见注释并不会对我们的代码产生什么影响
如何查看预编译后的文件呢?
$gcc -E hello.c -o hello.i
- -E:表示只进行预编译
- -o:指定要生成的结果文件,后面就是结果文件的名字
经过预编译之后的.i文件中不会包含任何宏定义,也就是#define,因为已经被替换,所以当无法判断宏定义是否正确或者头文件是否包含正确时,可以查看预编译后的文件来确定问题
#define PI 3.14
int main()
{
double d = PI;
return 0;
}
--------预编译之后---------
int main()
{
double d = 3.14;
return 0;
}
编译
编译的过程是把预处理文件进行:词法分析->语法分析->语义分析->源代码生成->目标代码的生成和优化
整个过程如下:
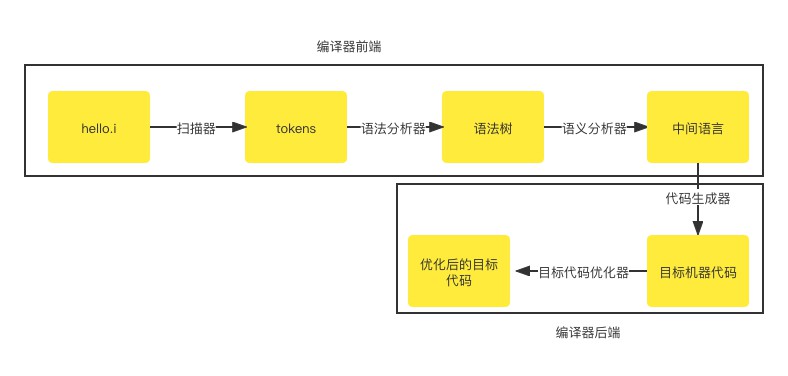
其结果是产生.s的汇编文件
上面的过程相当于执行了:
$gcc -S hello.i -o hello.s
也可以用命令ccl来完成,路径是/usr/lib/gcc/x86_64-linux-gnu/7/cc1,这个命令是将预编译和编译封装了起来
$/usr/lib/gcc/x86_64-linux-gnu/7/cc1 hello.c
其实gcc 的-S命令就是调用的cc1这个命令,所以gcc这个命令就是这些程序的包装,这些成比如:cc1,ld,as这些其实都是程序,gcc会根据不同的参数去调用不同的程序,相当于在外面加了一层
来看下编译的详细过程:
词法分析
这个过程会产生token,听着token感觉好高大上,其实也就那么回事,通俗点来说,给程序中的所有的符号进行分类,而这个分类都有什么呢?比如:标识符、左括号、右括号、加号、乘号、数字、赋值、左右方括号
arr[i] = (i + 1) * (2 + 3)
对上面语句进行分类就是:arr、i是标识符,1、2、3都属于数字,有加号、还有乘号、还有左右括号、左右方括号和赋值,就是这么简单的分类,这里面的每个符号,都表示一个token。
语法分析
语法分析的结果是生成语法树,一听很懵逼是吧,听我给你慢慢道来,先来一句总结的话,语法树怎么生成的?可以这么理解:就是以运算符为根节点,操作数为孩子节点,将语句根据运算符的优先级从右到左,将树从下到上构造成的。没听懂吗? 上图
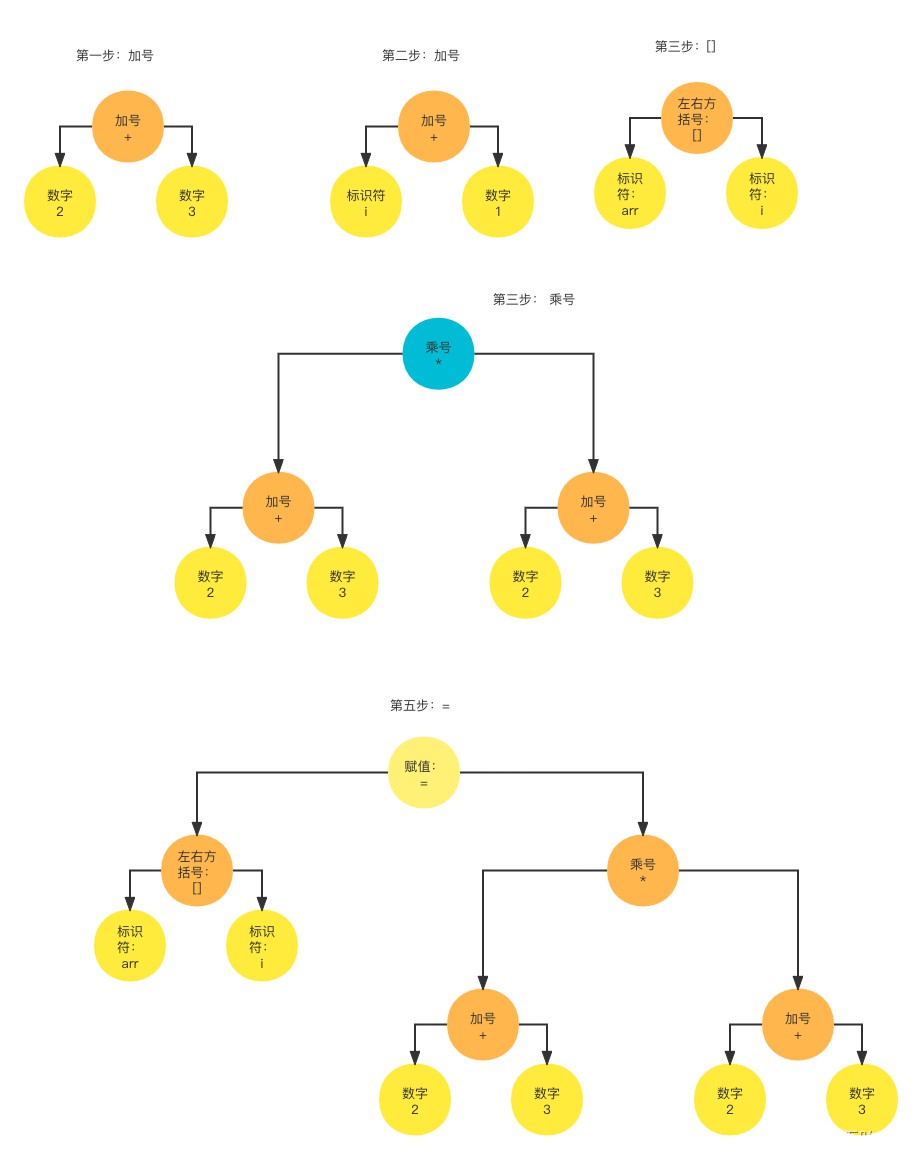
- 按照运算符的优先级,应该先计算()和[]中内容,按照我们的运算符为根节点的说法,所以以i和1为孩子节点,以+为根节点,以2和3为孩子节点,以+为根节点,[]为根节点,arr和i为孩子节点
- 然后以*为根节点,上述生成的两个节点看成一个整体作为*的根节点,赋值左边的[]也是以相同的逻辑形成生成一个子树
- 最后以=作为根节点,将上面步骤生成的两个根节点看成一个整体,形成一个语法树
总结:
- 语法树是以表达式为节点的树,C中一个语句就是一个表达式,而一个复杂的语句又是很多表达式的组合,比如我们的语句中有:赋值表达式、加法表达式、乘法表达式、数组表达式。
- 在上述的图中,叶子节点都以黄色标识出来,可以看到符号和数字是最小的表达式
- 同时在语法分析的同时,运算符的优先级也被确定了下来,()和[]一样高,()比*优先级高,*比+号优先级高
- 在语法分析过程中,如果出现了表达式不合法,比如括号不匹配等,编译器会报错误
语义分析
那么语义分析阶段主要做什么事情呢?
语法分析,只是完成了表达式语法层面的分析,并不知道这个语句的真正意义,比如说两个指针做乘法运算,语法分析是分析不出来的。
语义分析包括:静态语义和动态语义,静态语义就是在编译期间可以确定的语义,比如将浮点数赋值给整型的类型转换,动态语义就是运行时才能确定的语义,比如0作为除数。
来个case:如果将一个浮点数赋值给一个指针,语义分析阶段就会出错。
语义分析的结果就是:整个 语法树的表达式,都被标识了类型

中间语言生成
编译器在源代码级别会有一个优化的过程,比如我们上述的表达式2 + 3就可以被优化成5:

直接在语法树上做优化比较困难,所以源码优化器将整个语法树转化成中间代码,它是语法树的顺序表示,此时的中间代码和目标机器和运行时环境还是无关的,中间代码使编译器可以分为前端和后端
目标代码生成和优化
代码生成器将中间代码转换成目标机器码:这个过程依赖于目标机器,不同的机器有不同的字长、寄存器等,此时生成的就是汇编代码了
movl i, $ecx addl $4, %ecx ....
目标代码优化器对目标代码进行优化,比如选择一个合适的寻址方式等
汇编
汇编是将汇编代码转换成机器可以执行的指令,每一个汇编语句几乎都对应一条机器指令,所以这个过程,根据汇编指令和机器指令的对照表,一一分析就可以了。
上面的过程相当于执行了
$gcc -c hello.c -o hello.o
或者
$gcc -c hello.s -o hello.o
或者
$as hello.s -o hello.o
又一次验证了上面的结论,gcc命令对as程序的封装
汇编的结果生成的.o文件叫做目标文件
链接
到目前位置,完成了编译的整个过程,到现在位置,还没有为程序中的变量分配地址,那么什么时候分配地址呢?假设已经分配了地址,那么我们有可能在引用了别的文件中的变量或者函数,那么此时怎么为他们分配地址呢?所以肯定不是在之前分配地址的。
这个过程在链接阶段才能确定,定义在其他文件的全局变量和函数在最终运行时的绝对地址都要在最终链接时才能确定,所以编译器将一个源码文件编译成一个未链接的目标文件,然后由链接器最终将这些目标文件链接起来形成可执行文件。
链接的主要内容就是把各个模块之间相互引用的部分处理好,使各个模块之间能够正确链接,这里所有的模块之间的相互引用是指全局变量的相互引用和函数的相互调用,其实链接的工作就是把一些指令对其他符号的地址的引用加以修正
链接过程主要包括:
- 地址和空间分配
- 符号决议(静态链接)
- 重定位
什么是静态链接呢?
源代码文件经过编译器后生成目标文件,目标文件和库一起链接成可执行文件,这里的库是运行时库,库是一组目标文件的包,就是一些常用的代码编译成目标文件后打包存放
比如有两个文件A.c 和B.c A中使用了B的函数foo()和变量var, 由于每个模块都是单独编译的,所以在编译阶段并不知道函数foo和变量var的地址,所以就将他们地址暂时设置成0,等待链接器将目标文件A和B链接起来的时候再修改正,这个修正的过程叫做重定位,整个过程就是静态链接的基本过程。
以上所述是小编给大家介绍的c语言执行Hello World背后经历的步骤,希望对大家有所帮助。在此也非常感谢大家对网站的支持!
加载全部内容