Python 运动员信息的分组与聚合
a Fang 人气:03.1 数据的爬取
代码:
import pandas as pd
f = open('运动员信息表.csv')
data=pd.read_csv(f,skiprows=0,header=0)
print(data)
运行结果:
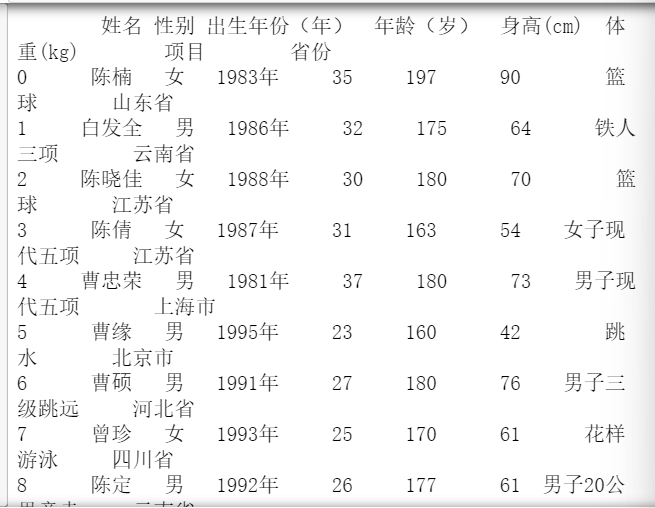
首先使用pd.read_csv(f,skiprows=0,header=0)进行数据的读取,并且将数据转换成为dataframe的格式给对象,做初始化,方便后面进行数据的分析。
3.2统计男篮、女篮运动员的平均年龄、身高、体重
代码:
sex=data[["年龄(岁)","身高(cm)","体重(kg)"]].groupby(data["性别"]) print(sex.mean())
运行结果:

首先我们先把数据提取出来做个分组,先把"年龄(岁)",“身高(cm)”,"体重(kg)"这三行数据提取出来再根据性别进行分组。
sex=data[["年龄(岁)","身高(cm)","体重(kg)"]].groupby(data["性别"])
然后再调用mean()求平均值,求出男篮、女篮运动员的平均年龄、身高、体重。
3.3统计男篮运动员年龄、身高、体重的极差值
代码:
sex=data[["年龄(岁)","身高(cm)","体重(kg)"]].groupby(data["性别"])
basketball_male=dict([x for x in sex])['男']
basketball_male
#求极差
def range_data_group(arr):
return arr.max()-arr.min()
#进行每列不同的聚合
basketball_male.agg({
"年龄(岁)":range_data_group,"身高(cm)":range_data_group,"体重(kg)":range_data_group
})
运行结果:
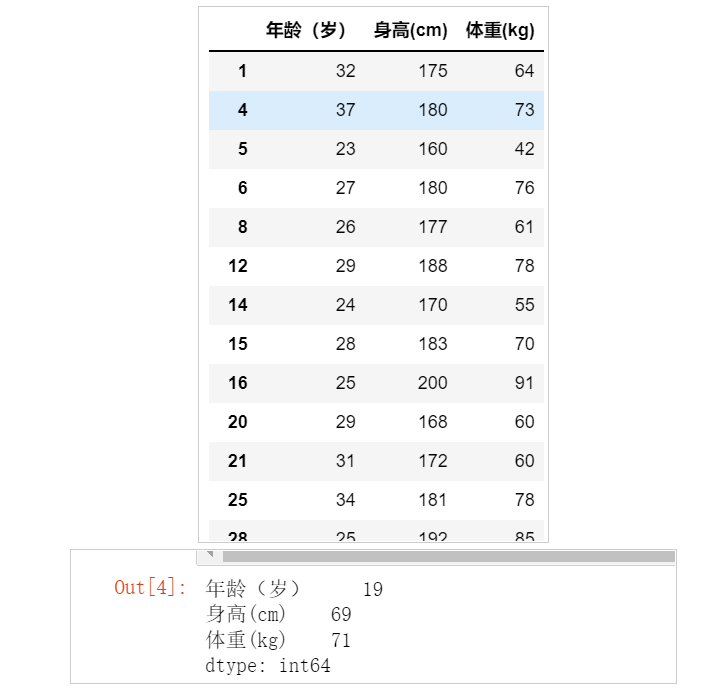
首先提取数据:
单行循环提取数据,dict([x for x in sex])在循环体内的语句只有一行的情况的下,可以简化for循环的书写。定义一个函数def range_data_group(arr):求极差;
极差的求法:使用最大值减去最小值。就得到极差。
agg()函数:DataFrame.agg(*func*,*axis = 0*,* args*,*** kwargs* )*
func : 函数,函数名称,函数列表,字典{‘行名/列名’,‘函数名’}
使用指定轴上的一个或多个操作进行聚合。
需要注意聚合函数操作始终是在轴(默认是列轴,也可设置行轴)上执行,不同于 numpy聚合函数
最后我们可以得到三列数据:分别对应"年龄(岁)",“身高(cm)”,“体重(kg)”。
3.4 统计男篮运动员的体质指数
3.4.1添加体重指数
代码:
data["体质指数"]=0 data
运行结果:
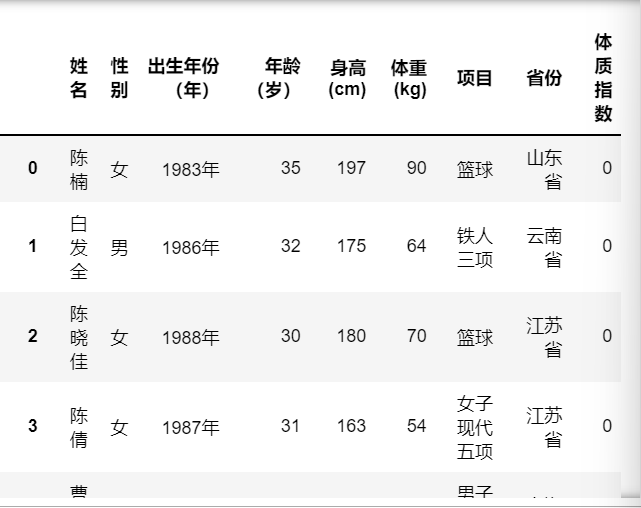
添加一行体重指数:data[“体质指数”]=0
3.4.2计算bmi值并添加数据
代码:
# 计算bmi数值
def outer(num):
def bminum(sumbim):
weight=data["身高(cm)"]
height=data["体重(kg)"]
sumbim=weight/(height/100)**2
return num+sumbim
return bminum
将该行数据添加上去:
代码:
# 调用函数 bimdata=data["体质指数"] data["体质指数"]=data[["体质指数"]].apply(outer(bimdata)) data
运行结果:

编写函数计算bmi数值 outer(num);然后再使用apply的方法将自定义的函数应用到"体质指数"这一列。然后计算出该列的值之后进行赋值。
data[“体质指数”]=data[[“体质指数”]].apply(outer(bimdata))
97622)]
编写函数计算bmi数值 outer(num) ;然后再使用apply的方法将自定义的函数应用到"体质指数"这一列。然后计算出该列的值之后进行赋值。
data[“体质指数”]=data[[“体质指数”]].apply(outer(bimdata))
加载全部内容