Python爬虫练习
路过_听雨声 人气:0一、 软件配置
安装必备爬虫环境软件:
- python 3.8
- pip install requests
- pip install beautifulsoup4
二、爬取南阳理工OJ题目
网站地址:http://www.51mxd.cn/
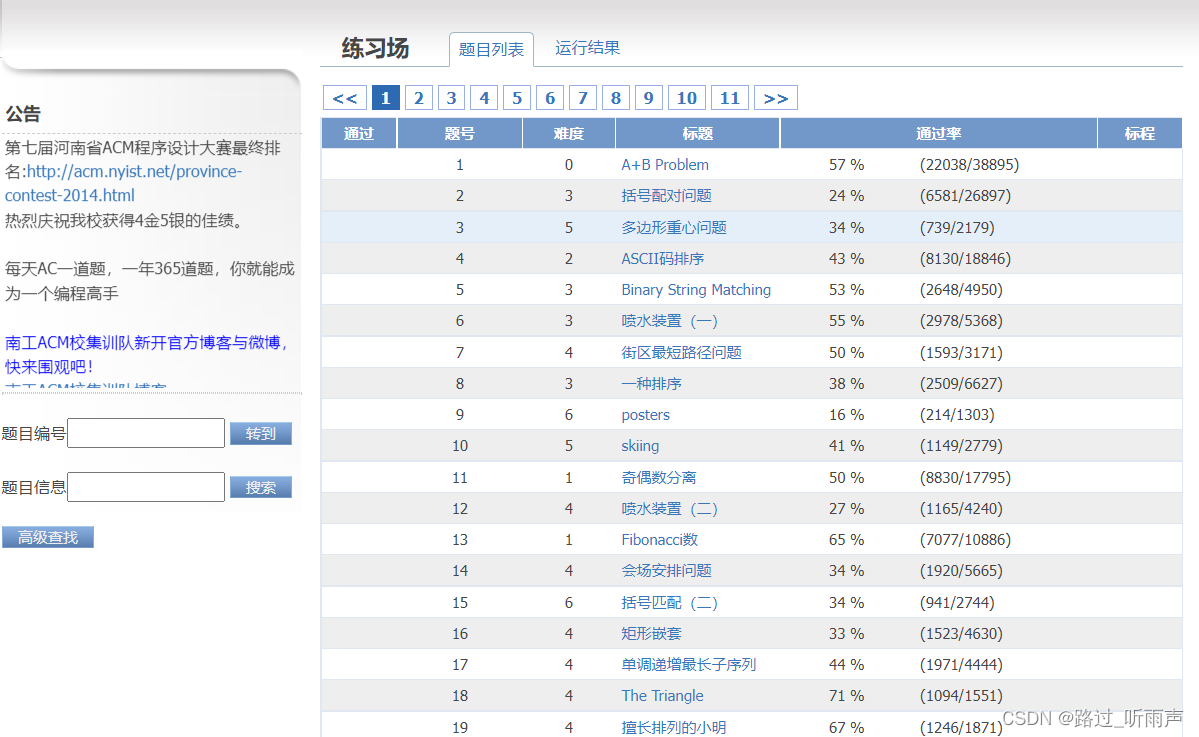
(一)页面分析
切换页面的时候url网址发生变动,因此切换页面时切换第n页则为n.html
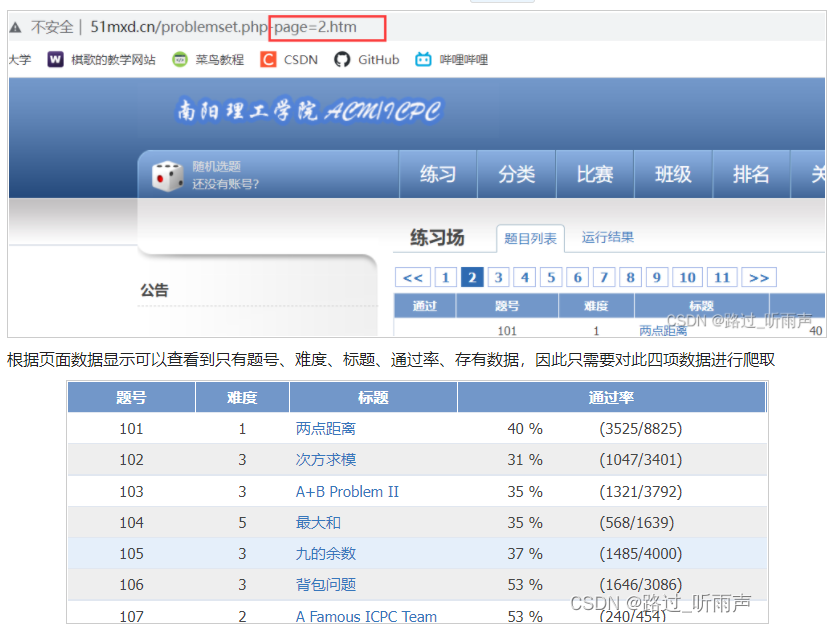
查看html代码:
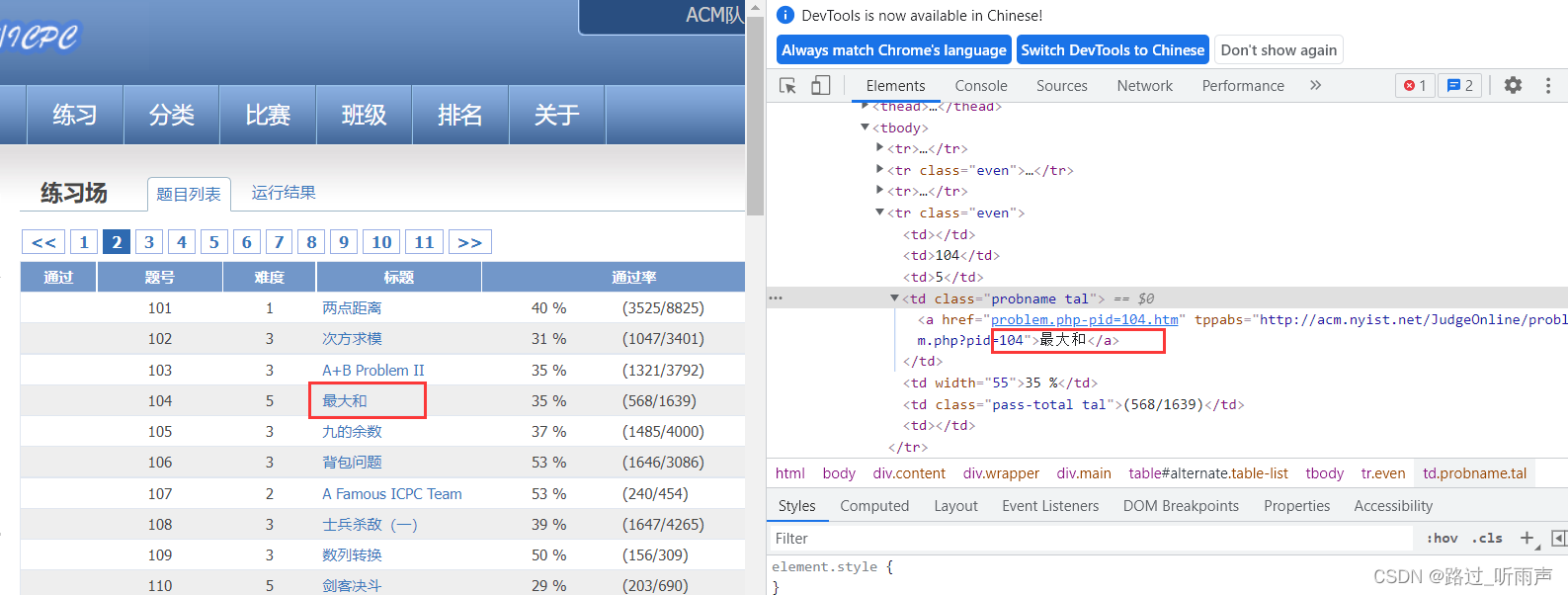
在每一个标签内都是<tr><td></td></tr>使用嵌套模式,因此可以使用爬虫进行爬取
(二)代码编写
导入相应的包
#导入包 import requests from bs4 import BeautifulSoup import csv from tqdm import tqdm#在电脑终端上显示进度,使代码可视化进度加快
定义访问浏览器所需的请求头和写入csv文件需要的表头及存储列表
# 模拟浏览器访问 Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400' # 题目数据 subjects = [] # 表头 csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
定义爬取函数,并删选信息
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html5lib')
td = soup.find_all('td')#讲所有含TD的项提取出来
subject = []
for t in td:
if t.string is not None:
#利用string方法获取其中的内容
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
写入文件
with open('D:/NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # 写入表头
fileWriter.writerows(subjects) # 写入数据
print('\n题目信息爬取完成!!!')
结果

三、爬取学校信息通知
网站地址:http://news.cqjtu.edu.cn/xxtz.htm

(一)页面分析
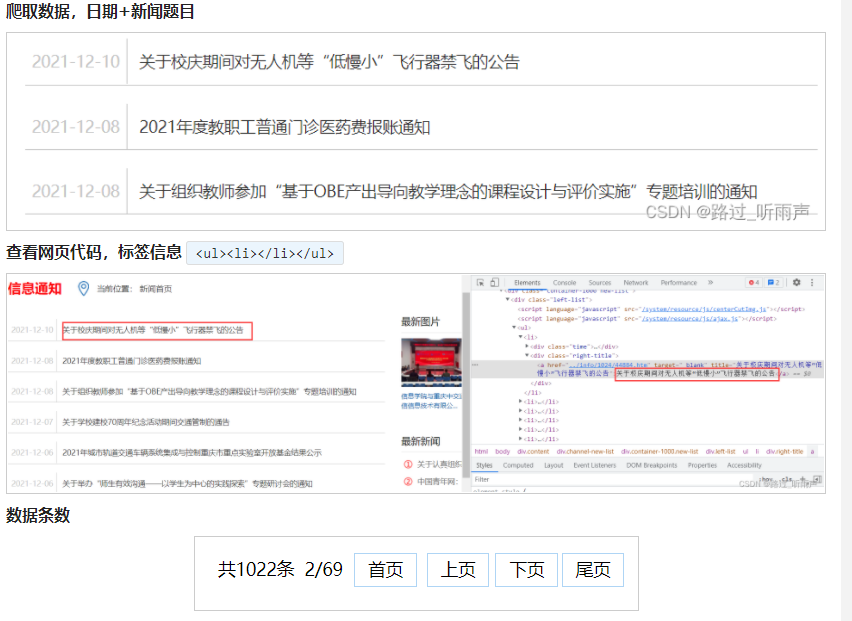
可以看到在html跳转采用 n-方式 因为为n-.html

爬取数据,日期+新闻题目
(二)代码编写
import requests
from bs4 import BeautifulSoup
import csv
# 获取每页内容
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
try:
info_list_page = [] # 一页的所有信息
resp = requests.get(url, headers=headers)
resp.encoding = resp.status_code
page_text = resp.text
soup = BeautifulSoup(page_text, 'lxml')
li_list = soup.select('.left-list > ul > li') # 找到所有li标签
for li in li_list:
divs = li.select('div')
date = divs[0].string.strip()
title = divs[1].a.string
info = [date, title]
info_list_page.append(info)
except Exception as e:
print('爬取' + url + '错误')
print(e)
return None
else:
resp.close()
print('爬取' + url + '成功')
return info_list_page
# main
def main():
# 爬取所有数据
info_list_all = []
base_url = 'http://news.cqjtu.edu.cn/xxtz/'
for i in range(1, 67):
if i == 1:
url = 'http://news.cqjtu.edu.cn/xxtz.htm'
else:
url = base_url + str(67 - i) + '.htm'
info_list_page = get_one_page(url)
info_list_all += info_list_page
# 存入数据
with open('D:/教务新闻.csv', 'w', newline='', encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(['日期', '标题']) # 写入表头
fileWriter.writerows(info_list_all) # 写入数据
if __name__ == '__main__':
main()
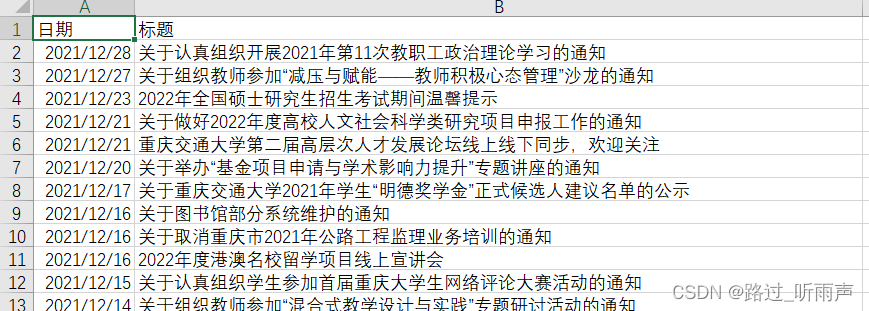
结果:
总结:
本次实验对利用Python 进行爬虫进行了学习,并实现了对网站信息的爬取。
加载全部内容