sqlite实现kafka延时消息
余生若晖 人气:11、需求
延时消息(或者说定时消息)是业务系统里一个常见的功能点。常用业务场景如:
1) 订单超时取消
2) 离线超过指定时间的用户,召回通知
3) 手机消失多久后通知监护人……
现流行的实现方案主要有:
1)数据库定时轮询,扫描到达到延时时间的记录,业务处理,删除该记录
2)jdk 自带延时队列(DelayQueue),或优化的时间轮算法
3)redis 有序集合
4)支持延时消息的分布式消息队列
但以上方案,都存在各种缺陷:
1)定时轮询间隔小,则对数据库造成很大压力,分布式微服务架构不好适配。
2)jdk 自带延时队列,占用内存高,服务重启则丢失消息,分布式微服务架构不好适配。
3)redis 有序集合比较合适,但内存贵,分布式微服务架构不好适配。
4)现在主流的 RocketMQ 不支持任意延时时间的延时消息,RabbitMQ或ActiveMQ 性能不够好,发送配置麻烦,kafka不支持延时消息。
因此,我想实现一个适配分布式微服务架构、高性能、方便业务系统使用的延时消息转发中间件。
2、实现思路
要保证高性能,推荐使用 kafka 或者 RocketMQ 做分布式消息队列。当前是基于 sqlite 实现 kafka 延时消息。
当前实现思路是基于kafka的,实际适用于任意MQ产品。
2.1 整体实现思路
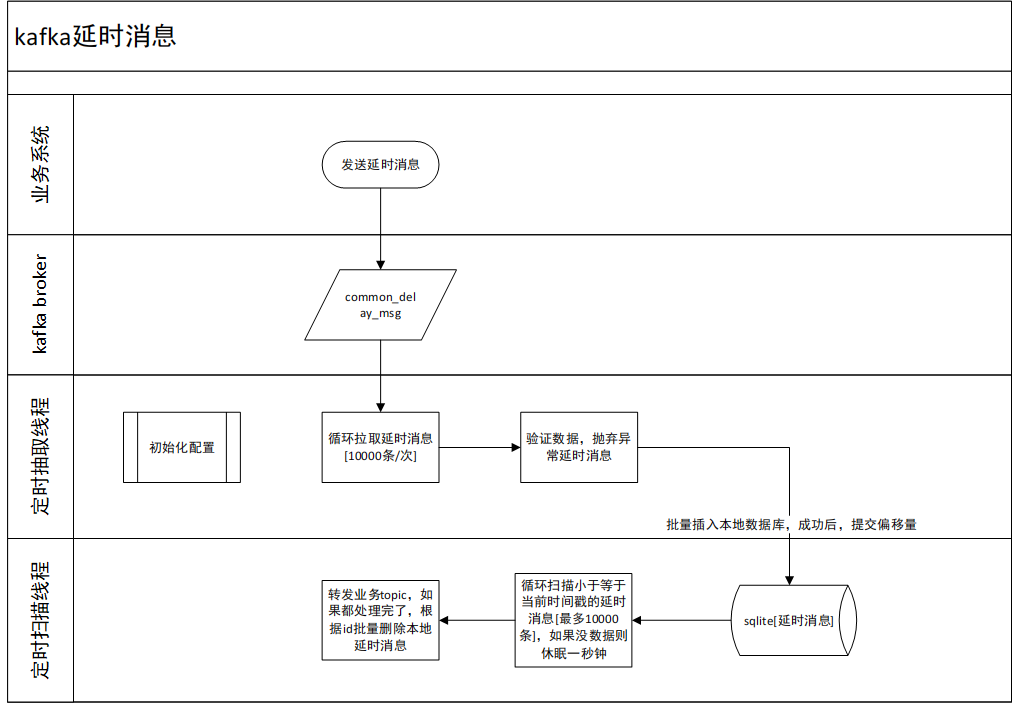
2.2 程序业务逻辑
1)业务系统先推送延时消息到统一延时消息队列
2)定时读取延时消息队列的延时消息,保存于本地,提交偏移量
3)定时扫描本地到达延时期限的消息,转发到实际业务消息队列
4)删除本地延时消息
2.3 实现细节
1)一个业务处理流程使用一个sqlite数据库文件,可并发执行提高性能。
2)使用雪花算法生成 id 。
3)没有延时消息时,线程休眠一定时间,减低kafka集群、和本地io压力。
4)本地存储使用 sqlite。
2.4 依赖框架
1)kafka-client
2)sqlite
3)slf4j+log4j2
4)jackson
3、性能测试
测试机器: i5-6500,16GB内存,机械硬盘
延时消息大小: 1kb
并发处理数:1
已本地简单测试,性能表现:
1) 1个并发处理数就可以达到1秒存储、转发、删除 约15000条延时消息,2 个可以达到 30000条/s ……
2) 一次性处理1万条记录,是经过多次对比试验得出的合适批次大小
也测试了其它两个本地存储方案的性能:
1)直接存读 json 文件,读写性能太差(约1200条记录/s,慢在频繁创建、打开、关闭文件,随机磁盘io);
2)RocksDB 存读,写入性能非常好(97000条记录/s),但筛选到期延时消息性能太差了,在数据量大于100w时,表现不如 sqlite,而且运行时占用内存、cpu 资源非常高。
4、部署
4.1 系统环境依赖
1)jdk 1.8
2)kafka 1.1.0
可以自行替换为符合实际kafka版本的jar包(不会有冲突的,jar包版本和kafka服务版本不一致可能会有异常[无法拉取消息、提交失败等])。
可修改pom.xml内的 kafka_version
<kafka_version>1.1.0</kafka_version>
重新打包即可。当前程序可以独立部署,对现有工程项目无侵入性。
4.2 安装
1)在项目根目录执行 maven 打包后,会生成 dev_ops 文件
2)在 dev_ops 目录下执行 java -jar kafka_delay_sqlite-20220102.jar 即可启动程序
3)如需修改配置,可在dev_ops目录内创建kafka.properties文件,设置自定义配置
默认配置如下:
# kafka 连接url [ip:port,ip:port……] kafka.url=127.0.0.1:9092 # 延时消息本地存储路径,建议使用绝对值 kafka.delay.store.path=/data/kafka_delay # 统一延时消息topic kafka.delay.topic=common_delay_msg # 消费者组id kafka.delay.group.id=common_delay_app # 并发处理数。限制条件: workers 小于等于topic分区数 kafka.delay.workers=2
4)业务方发送 kafka 消息到 topic (common_delay_msg)
消息体参数说明:
{
"topic": "实际业务topic",
"messageKey": "消息的key,影响发送到那个分区",
"message": "业务消息内容",
"delayTime": 1641470704
}
delayTime: 指定延时时限,秒级别时间戳
消息体案例:
{
"topic": "cancel_order",
"messageKey": "123456",
"message": "{\"orderId\":123456789123456,\"userId\":\"yhh\"}",
"delayTime": 1641470704
}
4.3 程序迁移
复制 延时消息保存目录 到新机器,重启部署、启动程序即可。(该配置项所在目录 kafka.delay.store.path=/data/kafka_delay)
4.4 排查日志
日志默认输出到 /logs/kafka_delay/ ,日志输出方式为异步输出。
system.log 记录了系统 info 级别以上的日志,info级别日志不是立刻输出的,所以程序重启时,可能会丢失部分日志
exception.log 记录了系统 warn 级别以上的日志,日志配置为立即输出,程序正常重启,不会丢失日志,重点关注这个日志即可。
如需自定义日志配置,可以在 log4j2.xml 进行配置。
如果要进行本地调试,可以解开注释,否则控制台没有日志输出:
<Root level="info">
<!--非本地调试环境下,建议注释掉 console_appender-->
<!--<AppenderRef ref="console_appender"/>-->
<AppenderRef ref="system_log_appender"/>
<AppenderRef ref="system_error_log_appender"/>
</Root>
5、注意事项
1) 由于设置了线程空闲时休眠机制,延时消息最大可能会推迟8秒钟发送。
如果觉得延迟时间比较大,可以自行修改源码的配置,重新打包即可。
KafkaUtils.subscribe()
MsgTransferTask.run()
2) 当前程序严格依赖于系统时钟,注意配置程序部署服务器的时钟和业务服务器时钟一致
3) 建议配置统一延时消息队列(common_delay_msg)的分区数为 2 的倍数
4) 每个 kafka.delay.workers 约需要 200 mb 内存,默认配置为2 , jvm 建议配置 1 GB 以上内存,避免频繁gc 。
workers 增大后,不要再减小,否则会导致部分 sqlite 数据库没有线程访问,消息丢失。
并发处理数越大,延时消息处理效率越高,但需要注意不要大于topic的分区数。
需要自行测试多少个并发处理数就会达到磁盘io、网络带宽上限。
当前程序主要瓶颈在于磁盘io和网络带宽,实际内存和cpu资源占用极低。
5) 程序运行时,不要操作延时消息保存目录即里面的文件
6) 当前配置为正常情况下不会抛弃消息模式,但程序重启时,存在重复发送消息的可能,下游业务系统需要做好幂等性处理。
如果kafka集群异常,当前配置为重新发送16次,如果仍不能恢复过来,则抛弃当前消息,实际生产环境里,基本不可能出现该场景。
如果确定消息不能抛弃,需要自行修改源码(MsgTransferTask.run,KafkaUtils.send(……)),重新打包、部署。
7) 程序出现未知异常(sqlite被手动修改、磁盘满了……),会直接结束程序运行。
6、闲聊
整体思路,实现,源码里都比较清晰,如果 RocketMQ 也有自定义延时需求,参考着修改源码即可,实现逻辑是一样的。
如果要尽可能的实现延时消息的最终处理,可以再额外采用2个延迟消息处理方案:
1、每天扫描一次数据库,把符合延时条件的记录统一处理一次
2、惰性处理,当用户再次访问某功能点时,再修改相关符合延时条件的记录
作者邮箱:1950249908@qq.com ,如有问题,欢迎骚扰。也欢迎大家加群谈论,QQ群: 777804773
源码路径:
https://gitee.com/yushengruohui/delay_message
https://github.com/yushengruohui/delay_message
总结
加载全部内容