Python 爬取微博热搜页面
小叮当的幻想 人气:0前期准备:
fiddler 抓包工具
Python3.6
谷歌浏览器
分析:
1.清理浏览器缓存cookie以至于看到整个请求过程,因为Python代码开始请求的时候不带任何缓存。
2.不考虑过多的header参数,先请求一次,看看返回结果
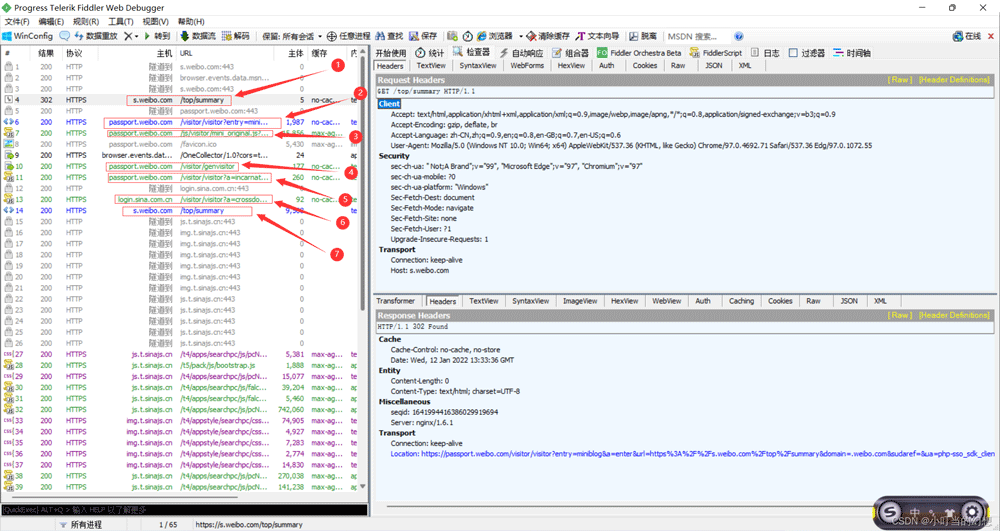
图中第一个链接是无缓存cookie直接访问的,状态码为302进行了重定向,用返回值.url会得到该url后面会用到(headers里的Referer参数值)
2 ,3 链接没有用太大用处为第 4 个链接做铺垫但是都可以用固定参数可以不用访问
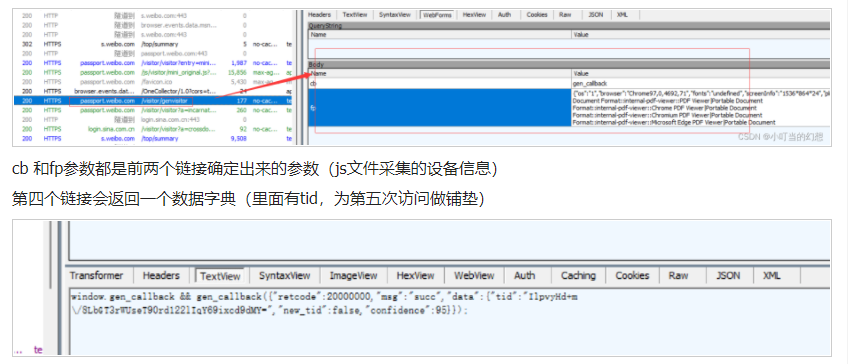
访问http://passport.weibo.com/visitor/genvisitor ,cookie为tid=__095,注意tid需要去掉转义字符‘\’,get传的参数有用的只有t也就是tid 其他都是固定值 、_rand是浮点随机数没啥具体的意义可以用Python的random.random()函数,需要导入random库,get传参使用params=,post传参用data=,不是随便都能用的
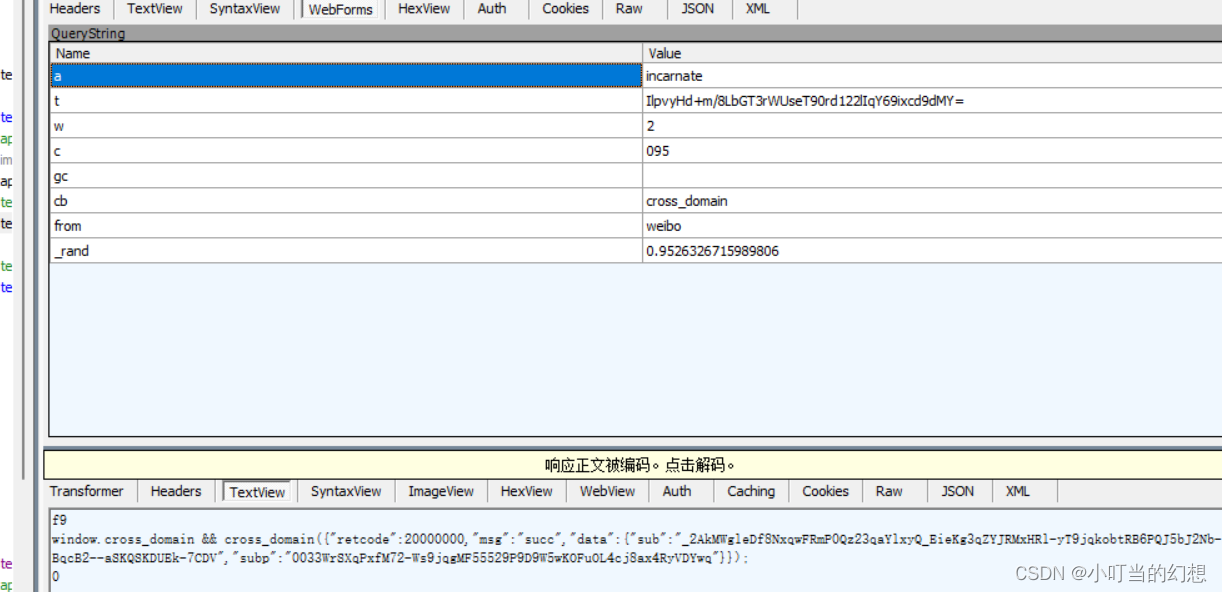
得到返回值 含有SUB 和SUBP参数的值
正好是访问最后一个链接也就是热搜榜需要的cookie的值
到此分析结束
代码:
import requests
import random
import re
import urllib3
#警告忽略
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
class Wb():
def __init__(self):
#利用session保持回话
self.session=requests.Session()
#清理headers字典,不然update好像不会起作用
self.session.headers.clear()
self.header={
"Host": "weibo.com",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/86.0.4240.198 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;"
"q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,"
"application/signed-exchange;v=b3;q=0.9",
"Sec-Fetch-Site": "cross-site",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Dest": "document",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
}
#设置代理如果需要fiddler抓包分析代码提交的参数使用下面代理如果不使用选择下面的代码self.fiddler_proxies=None
self.fiddler_proxies = {'http': 'http://127.0.0.1:8888', 'https': 'http://127.0.0.1:8888'}
# self.fiddler_proxies=None
def get_top_summary(self):
#更新添加header headers.update只会覆盖相同键值的值不会覆盖全部
self.session.headers.update(self.header)
#verify=False 不检查证书
response=self.session.get(url="https://weibo.com/",proxies=self.fiddler_proxies,verify=False)
print(response.url)
response.encoding='gbk'
data1={
"cb":"gen_callback",
"fp":'{"os":"1","browser":"Chrome86,0,4240,198",'
'"fonts":"undefined","screenInfo":"1920*1080*24",'
'"plugins":"Portable Document Format::internal-pdf-viewer::'
'Chromium PDF Plugin|::mhjfbmdgcfjbbpaeojofohoefgiehjai::'
'Chromium PDF Viewer|::internal-nacl-plugin::Native Client"}'
}
header1={
"Host": "passport.weibo.com",
"Cache-Control": "max-age=0",
"If-Modified-Since": "0",
"Content-Type": "application/x-www-form-urlencoded",
"Accept": "*/*",
"Origin": "http://passport.weibo.com",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Dest": "empty",
"Referer": response.url,
}
self.session.headers.update(header1)
response1=self.session.post(url="http://passport.weibo.com/visitor/genvisitor"
,data=data1,proxies=self.fiddler_proxies,verify=False)
#利用正则表达式解析tid参数的值
t=re.search('{"tid":"(.*)","new_tid"',response1.text).groups()[0]
data2={
"a":"incarnate",
"t":t.replace("\\",""),
"w": "2",
"c": "095",
"gc":"",
"cb":"cross_domain",
"from":"weibo",
"_rand":random.random()
}
header2={
"Sec-Fetch-Mode": "no-cors",
"Sec-Fetch-Dest": "script",
"Cookie":"tid="+t.replace("\\","")+"__095"
}
self.session.headers.update(header2)
response2 = self.session.get(url="http://passport.weibo.com/visitor/visitor",
params=data2,proxies=self.fiddler_proxies,verify=False)
#从返回值中获取cookie字典
cookie = requests.utils.dict_from_cookiejar(response2.cookies)
header3={
"Cookie":"SUB="+cookie["SUB"]+";"+"SUBP="+cookie["SUBP"],
"Host": "s.weibo.com",
"Upgrade-Insecure-Requests": "1"
}
self.session.headers.update(header3)
response3=self.session.get(url="https://s.weibo.com/top/summary",
proxies=self.fiddler_proxies,verify=False)
# print(response3.text)
if __name__ == '__main__':
wb=Wb()
wb.get_top_summary()至此只能得到原始的html页面,想要进一步操作需要在HTML里面提取有用的数据。。。。。。
爬虫初期需要更多的是耐心
加载全部内容