mysql多主双向+级联复制
啊欧丶 人气:0前言:
公司项目需求,要做一个内网用的物品管理的web系统,其中一个要求是要每个单位的本地PC在内网离线状态下(即无法访问总服务器)也能使用系统的服务。项目架构设计的是在线状态时访问总服务器,离线时,用户访问本地服务(是的,我们在每个本地PC上也部署了服务)。
注:
下级单位的本地PC能访问到总服务器时,称为在线,反之称为离线
一.解读
在离线状态的切换,对于web服务来说没什么影响,毕竟代码是一样的,所以不管部署在哪都一样。区别就是数据库中的数据。这就要求我们的主库,以及每个本机PC上部署的从库,他们之间能实现数据的自主同步。
关于可能的冲突,我们已经在业务层规避掉了。不同的单位,不会update相同的字段。不同的单位,不会在相同的表中insert。所以现在就只用关心mysql的自动同步,以及离线重连的自动续传了。
二.web设计
1.web后端,我设置了读写分离(只是为了装一下,其实大可不必,毕竟内网并发量不高)
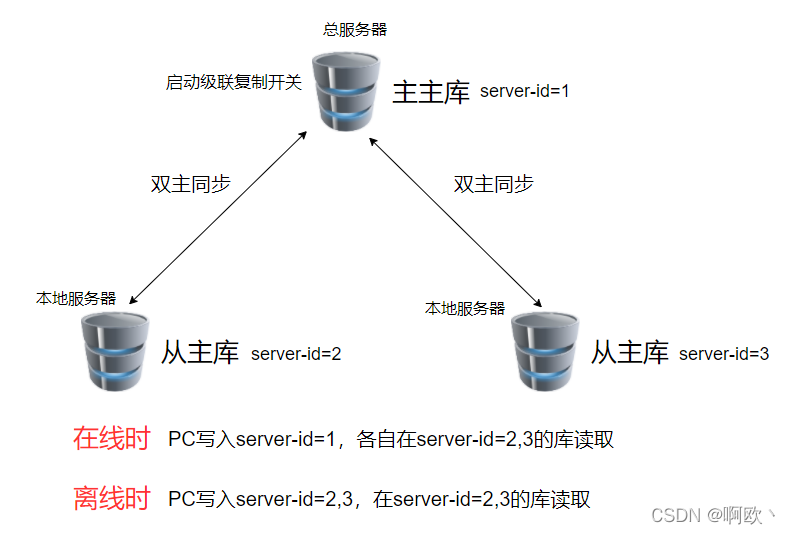
2.在线时,单位的访问,均select本地mysql,update/insert/delete总服务器mysql
3.离线时,单位的访问,均在本地mysql
(这很好实现,不同的域名地址,对应不同的项目,项目内提前设定好数据库router,由用户自主决定访问哪个域名地址即可。实际上,如果断网了,总服务器访问不通,他会自然而然的去访问本机服务的域名地址)
三.mysql设计
1.同步方式毋庸置疑用的是mysql自带的binlog,mysql版本要选择5.7及以上的版本
2.多主双向:每个本机PC上的mysql,要与总服务器上的mysql保持双主同步。
3.总服务器要开启级联复制,将下级单位PC产生的binlog,同步给其他单位的PC。以便其他单位的PC在离线时可以使用这部分数据
四、实操
1.mysql架构图(草稿)
2.配置
一阶段,先把所有库的master功能启动,同时在库中创建访问账号供其他库使用:
主主库(总服务器)
①在mysql安装路径下找到启动文件my.ini或my.cnf,将如下信息放在启动文件的[mysqld]下:
log_bin=mysql-bin binlog_format=MIXED sync_binlog=1 expire_logs_days=7 binlog-do-db=equip_system slave-skip-errors=all master_info_repository=table relay_log_info_repository=table log-slave-updates=1
各参数的释义:
log_bin=mysql-bin:配置为mysql-bin时,mysql开启binlog功能
binlog_format=MIXED:binlog的记录方式,MIXED为混合记录方式
sync_binlog=1:
触发binlog由缓存刷新到磁盘所需要提交的事务数量,默认为0表示由磁盘文件系统控制,为1表示每提交一个事务即刷新一次(此时最安全,服务异常时丢失的事务最多只有1个,但IO消耗最大,高并发下忌用),常见的DBA一般设置为100。本项目并发量低,可设置为1expire_logs_days=7:binlog有效时长,设置为7表示binlog存在7天后删除binlog-do-db=equip_system:要同步的数据库名slave-skip-errors=all:表示同步出现异常时要跳过哪些异常,设置为all表示所有异常的同步都直接跳过不管。是否可以设置为all,要结合项目的具体业务。本项目可以。master_info_repository=table:可选< table | file >,设置为table更稳定,重启服务时可以自动续传relay_log_info_repository=table:可选< table | file >,设置为table更稳定,重启服务时可以自动续传
log-slave-updates=1:配置为1表示开启级联复制
记得修改server-id,架构内互联的mysql均不能相同
server-id=100
②重启sql服务
③进入mysql命令行,执行以下命令
values为ON表示开启binlog成功
show variables like '%log_bin%';
有几个从主库,就创建几个账号,注意这个账号密码提前确定好记好,搞乱了就很头大:
CREATE USER '被同步库的账号名'@'被同步库的ip' IDENTIFIED BY '被同步库账号的密码'; GRANT REPLICATION SLAVE ON *.* TO '被同步库的账号名'@'被同步库的ip';
刷新权限:
flush privileges;
查看master状态:
show master status;
返回结果:

这个形如"mysql-bin.000003"的值要记录上,从主库连接时要用
主主库的一阶段配置完成了
从主库:
①在mysql安装路径下找到启动文件my.ini或my.cnf,将如下信息放在启动文件的[mysqld]下:
log_bin=mysql-bin binlog_format=MIXED sync_binlog=1 expire_logs_days=7 binlog-do-db=equip_system slave-skip-errors=all master_info_repository=table relay_log_info_repository=table
以上参数和主主库是一样的,区别在于从主库不需要开启级联复制。记得修改server-id
后边过程和主主库的配置是一样的,毕竟都是开启master功能的,这里就不赘述了。把产出的形如"mysql-bin.000003"的值记录下来就好了
一阶段各个库的master功能配置完成
二阶段,配置各个库的slave功能,即将其与要同步的库建立连接
从主库只需跟主主库建立连接即可
在mysql命令行中执行以下命令:
设置连接master的参数:
CHANGE MASTER TO MASTER_HOST='要同步的对方库的ip', MASTER_PORT=对方库的端口号, MASTER_USER='对方库为你创建的账号名', MASTER_PASSWORD='对方库为你创建的密码',MASTER_LOG_FILE='对方库master状态产出的File的值';
启动slave建立连接:
start slave;
查看连接状态:
show slave status\G
返回结果:
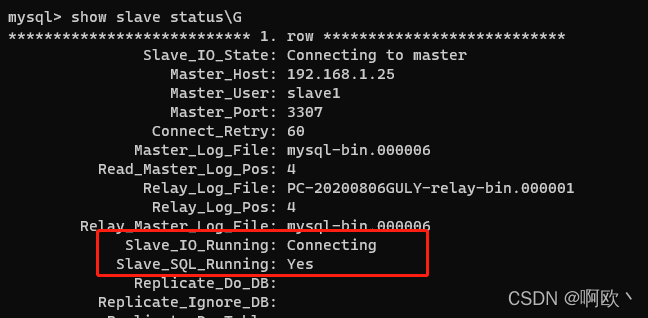
两个Running都为Yes时,表示连接成功了。不成功请自行查阅资料debug。我这里是对方库没开。
其余从主库操作一样,都是设置连接参数、启动slave建立连接、查看连接状态
主主库:
主主库流程同样是设置连接参数、启动slave建立连接、查看连接状态。不同点在于要设置多个master连接参数,所以设置连接参数的命令有一个小的变化,要多一个通道channel的设置,命令如下:
配置与从主库2的连接参数
CHANGE MASTER TO MASTER_HOST='从主库1的ip', MASTER_PORT='从主库1的端口号', MASTER_USER='从主库1为你创建的账号名', MASTER_PASSWORD='从主库1为你创建的密码',MASTER_LOG_FILE='从主库1的master状态的File值'for channel '1';
配置与从主库2的连接参数:
CHANGE MASTER TO MASTER_HOST='从主库2的ip', MASTER_PORT='从主库2的端口号', MASTER_USER='从主库2为你创建的账号名', MASTER_PASSWORD='从主库2为你创建的密码',MASTER_LOG_FILE='从主库2的master状态的File值'for channel '2';
有几个配几个:
...
启动slave:
start slave;
查看slave状态:
show slave status\G
返回结果有多个status,依次查看,依次核对即可。
结语:
该架构具有高可用强稳定的特性:具有多主一从,一主多从,双主架构的所有优势:1.上方多增加一个主主库2,形成双机热备提高容灾能力;2.增加大量从主库,进行读写分离,提高高并发下的性能;3.内网离线产生的数据在切换至在线状态时自动同步至所有其他库;
加载全部内容