Python朴素贝叶斯
柚子味的羊 人气:0朴素贝叶斯(Naive Bayes,NB):朴素贝叶斯分类算法是学习效率和分类效果较好的分类器之一。朴素贝叶斯算法一般应用在文本分类,垃圾邮件的分类,信用评估,钓鱼网站检测等。
1、鸢尾花案例
#%%库函数导入
import warnings
warnings.filterwarnings('ignore')
import numpy as np
# 加载莺尾花数据集
from sklearn import datasets
# 导入高斯朴素贝叶斯分类器
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
#%%数据导入&分析
X, y = datasets.load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
#%%查看数据集
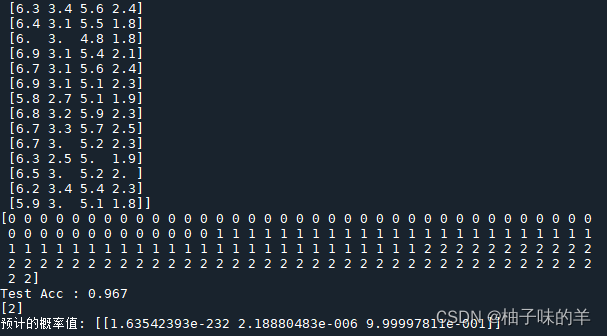
print(X)#特征集
print(y)#现象
#%%模型训练
# 假设每个特征都服正态分布,使用高斯朴素贝叶斯进行计算
clf = GaussianNB(var_smoothing=1e-8)
clf.fit(X_train, y_train)
#%%模型预测
# 评估
y_pred = clf.predict(X_test)
acc = np.sum(y_test == y_pred) / X_test.shape[0]
print("Test Acc : %.3f" % acc)
# 预测
#对第一行数据预测
y_proba = clf.predict_proba(X_test[:1])
#使用predict()函数得到预测结果
print(clf.predict(X_test[:1]))
#输出预测每个标签的概率,预测标签为0,1,2的概率分别为数组的三个值
print("预计的概率值:", y_proba)
运行结果
2、小结
predict()函数和predict_proba()函数的区别: predict()函数用于预测标签,直接得到预测标签。predict_proba()函数得到的是测试集预测得到的每个标签的概率。如果测试集一共有30个数据集,数据原本有3个标签,那么使用predict()函数将会得到30个具体预测得到的标签值,是一个【130】的数组,使用predict_proba()函数得到的是30个数据集分别取得3个标签的概率,是一个【303】的数组。
我又回来了,继续更新~ 欢迎交流
加载全部内容