Python 决策树分类实例
柚子味的羊 人气:0一、数据集
该数据集一共包含8个变量,其中7个特征变量,1个目标分类变量。共有150个样本,目标变量为 企鹅的类别 其都属于企鹅类的三个亚属,分别是(Adélie, Chinstrap and Gentoo)。包含的三种种企鹅的七个特征,分别是所在岛屿,嘴巴长度,嘴巴深度,脚蹼长度,身体体积,性别以及年龄。
二、实现过程
1 数据特征分析
## 基础函数库
import numpy as np
import pandas as pd
## 绘图函数库
import matplotlib.pyplot as plt
import seaborn as sns
#%%读入数据
#利用Pandas自带的read_csv函数读取并转化为DataFrame格式
data = pd.read_csv('D:\Python\ML\data\penguins_raw.csv')
#我选取了四个简单的特征进行研究
data = data[['Species','Culmen Length (mm)','Culmen Depth (mm)',
'Flipper Length (mm)','Body Mass (g)']]
data.info()
#查看数据
print(data.head())
#发现数据中存在的NAN,缺失值此处使用-1将缺失值进行填充
data=data.fillna(-1)
print(data.tail())
#查看对应标签
print(data['Species'].unique())
#统计每个类别的数量
print(pd.Series(data['Species']).value_counts())
#对特征进行统一描述
print(data.describe())
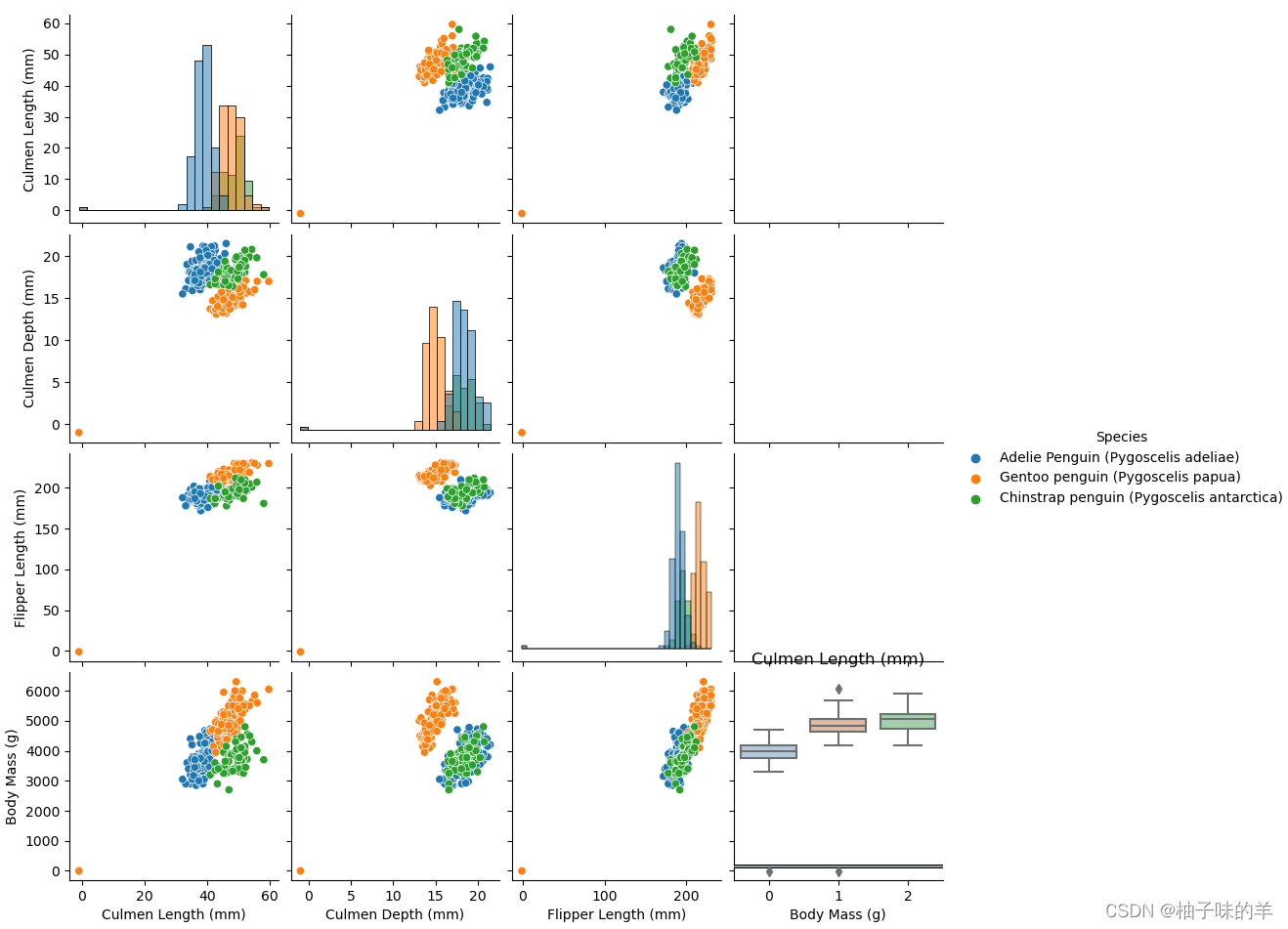
#可视化描述
sns.pairplot(data=data,diag_kind='hist',hue='Species')
plt.show()
#%%为了方便处理,将标签数字化
# 'Adelie Penguin (Pygoscelis adeliae)' ------0
# 'Gentoo penguin (Pygoscelis papua)' ------1
# 'Chinstrap penguin (Pygoscelis antarctica) ------2
def trans(x):
if x == data['Species'].unique()[0]:
return 0
if x == data['Species'].unique()[1]:
return 1
if x == data['Species'].unique()[2]:
return 2
data['Species'] = data['Species'].apply(trans)
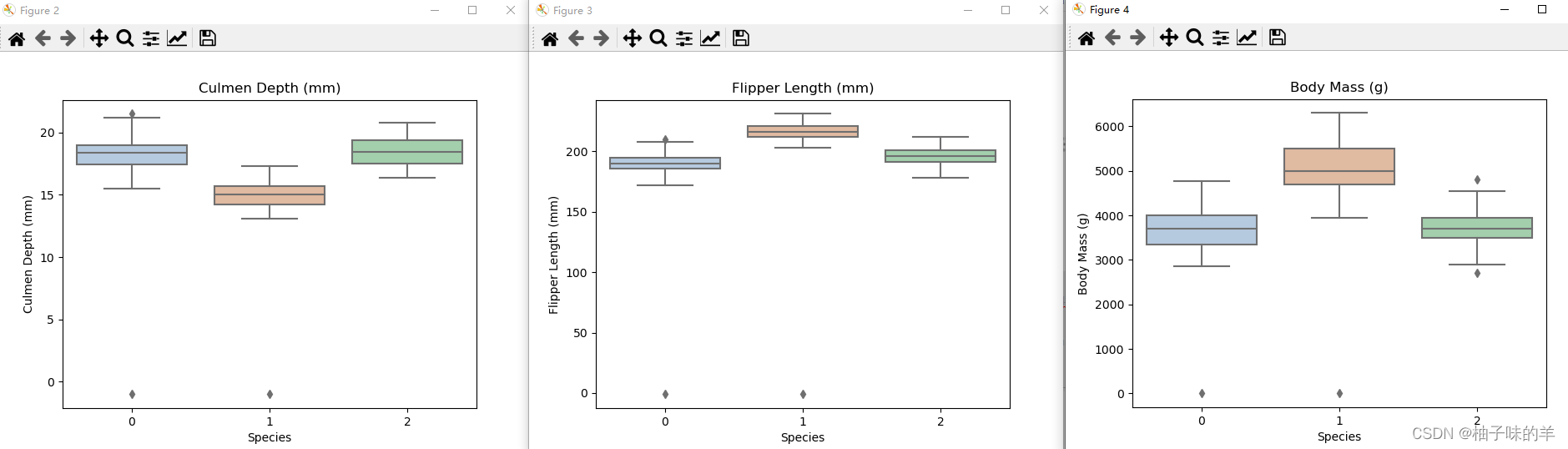
#利用箱图得到不同类别在不同特征上的分布差异
for col in data.columns:
if col != 'Species':
sns.boxplot(x='Species', y=col, saturation=0.5, palette='pastel', data=data)
plt.title(col)
plt.show()
plt.figure()
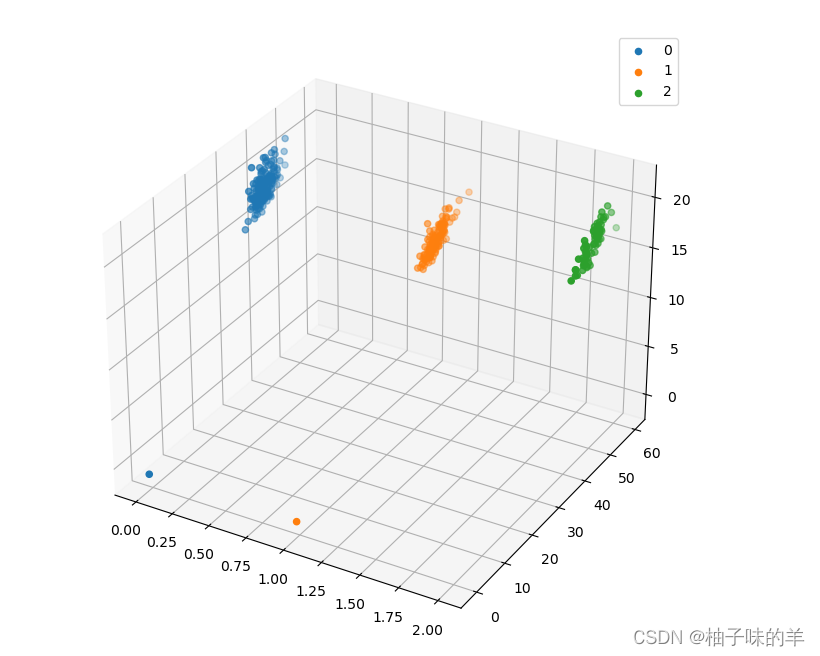
#%%选取species,culmen_length和culmen_depth三个特征绘制三维散点图
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111, projection='3d')
data_class0 = data[data['Species']==0].values
data_class1 = data[data['Species']==1].values
data_class2 = data[data['Species']==2].values
# 'setosa'(0), 'versicolor'(1), 'virginica'(2)
ax.scatter(data_class0[:,0], data_class0[:,1], data_class0[:,2],label=data['Species'].unique()[0])
ax.scatter(data_class1[:,0], data_class1[:,1], data_class1[:,2],label=data['Species'].unique()[1])
ax.scatter(data_class2[:,0], data_class2[:,1], data_class2[:,2],label=data['Species'].unique()[2])
plt.legend()
plt.show()
运行结果
2 利用决策树模型在二分类上进行训练和预测
#%%利用决策树模型在二分类上进行训练和预测——选取0和1两类样本,样本选取其中的四个特征
## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。
from sklearn.model_selection import train_test_split
data_target_part = data[data['Species'].isin([0,1])][['Species']]
data_features_part = data[data['Species'].isin([0,1])][['Culmen Length (mm)','Culmen Depth (mm)',
'Flipper Length (mm)','Body Mass (g)']]
## 测试集大小为20%, 80%/20%分
x_train, x_test, y_train, y_test = train_test_split(
data_features_part, data_target_part, test_size = 0.2, random_state = 2020)
## 从sklearn中导入决策树模型
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
## 定义 决策树模型
clf = DecisionTreeClassifier(criterion='entropy')
# 在训练集上训练决策树模型
clf.fit(x_train, y_train)
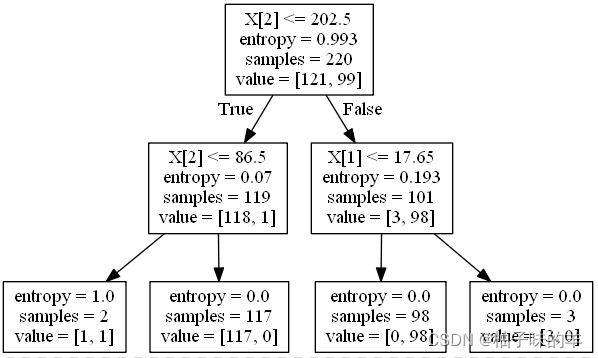
#%% 可视化决策树
import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_png("D:\Python\ML\DTpraTree.png")
#%% 在训练集和测试集上利用训练好的模型进行预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
from sklearn import metrics
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
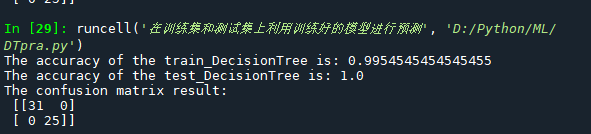
print('The accuracy of the train_DecisionTree is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the test_DecisionTree is:',metrics.accuracy_score(y_test,test_predict))
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
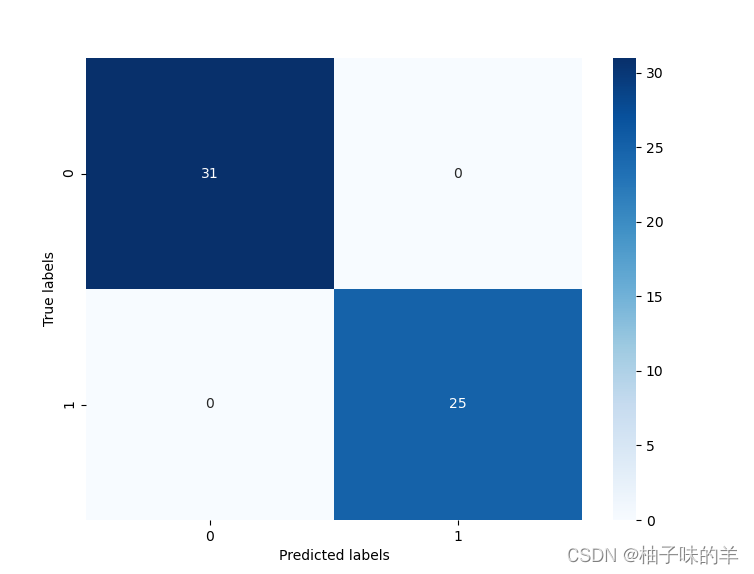
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
运行结果
3 利用决策树模型在多分类(三分类)上进行训练与预测
#%%利用决策树在多分类(三分类)上进行训练和预测
## 测试集大小为20%, 80%/20%分
x_train, x_test, y_train, y_test = train_test_split(data[['Culmen Length (mm)','Culmen Depth (mm)',
'Flipper Length (mm)','Body Mass (g)']], data[['Species']], test_size = 0.2, random_state = 2020)
## 定义 决策树模型
clf = DecisionTreeClassifier()
# 在训练集上训练决策树模型
clf.fit(x_train, y_train)
## 在训练集和测试集上分布利用训练好的模型进行预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
train_predict_proba = clf.predict_proba(x_train)
test_predict_proba = clf.predict_proba(x_test)
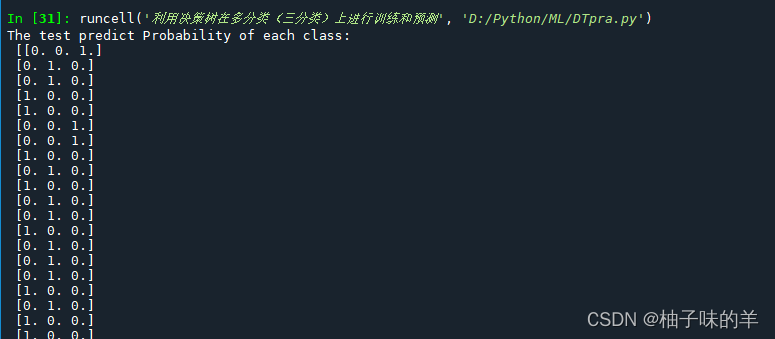
print('The test predict Probability of each class:\n',test_predict_proba)
## 其中第一列代表预测为0类的概率,第二列代表预测为1类的概率,第三列代表预测为2类的概率。
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the train_DecisionTree is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the test_DecisionTree is:',metrics.accuracy_score(y_test,test_predict))
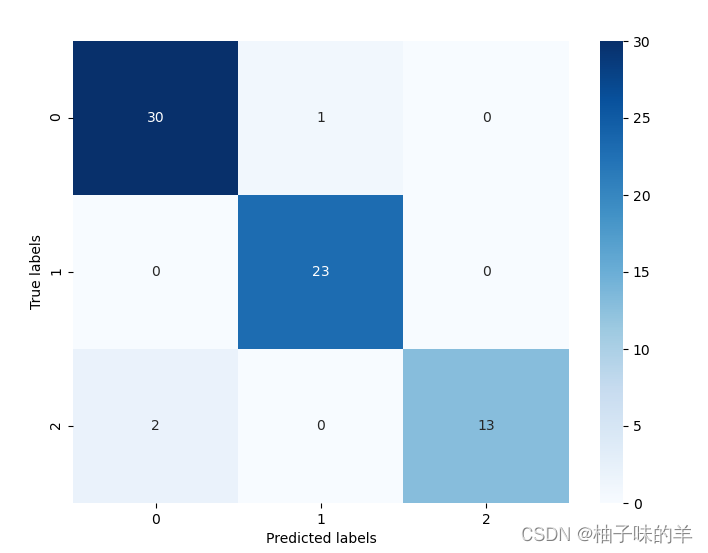
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
运行结果

三、KEYS
1 构建过程
决策树的构建过程是一个递归的过程,函数存在三种返回状态:
- 当前节点包含的样本全部属于同一类别,无需继续划分
- 当前属性集为空或者所有样本在某个属性上的取值相同,无法继续划分
- 当前节点包含的样本几何为空,无法划分
2 划分选择
决策树构建的关键是从特征集中选择最优划分属性,一般大家希望决策树每次划分节点中包含的样本尽量属于同一类别,也就是节点的“纯度”最高
- 信息熵:衡量数据混乱程度的指标,信息熵越小,数据的“纯度”越高
- 基尼指数:反应了从数据集中随机抽取两个类别的标记不一致的概率
3 重要参数
- criterion:用来决定模型特征选择的计算方法,sklearn提供两种方法:
entropy:使用信息熵
gini:使用基尼系数
- random_state&splitte:
random_state用于设置分支的随机模式的参数
splitter用来控制决策树中的随机选项
- max_depth:限制数的深度
- min_samples_leaf:一个节点在分支之后的每个子节点都必须包含至少几个训练样本。该参数设置太小,会出现过拟合现象,设置太大会阻止模型学习数据
886~~
加载全部内容