python中pandas读取csv文件
bulabula2022 人气:0优点:
- 方便,有专门支持读取csv文件的pd.read_csv()函数。
- 将csv转换成二维列表形式
- 支持通过列名查找特定列。
- 相比csv库,事半功倍
1.读取csv文件
import pandas as pd
file="c:\data\test.csv"
csvPD=pd.read_csv(file)
df = pd.read_csv('data.csv', encoding='gbk') #指定编码
read_csv()方法参数介绍
filepath_or_buffer:文件所在路径
encoding :编码,字符型,通常为'utf-8',如果中文读取不正常,可以将encoding设为'gbk'
sep:分隔符,默认为一个英文逗号,即','
delimiter :备选分隔符,如果指定了delimiter则sep失效
header :整数或者由整数组成的列表,以用来指定由哪一列或者哪几列作为列名,默认为header=0,表示第一列作为列名
eg: pd.read_csv('data.csv', encoding='gbk', header=1) # 指定第二列作为列名
pd.read_csv('data.csv', encoding='gbk', header=[0,1,3])
pd.read_csv('data.csv', encoding='gbk', header=None) #表示不从文件数据中指定行作为列名,这是Pandas会自动生成从零开始的序列作为列名
names:一个列表,为数据额外指定列名。
pd.read_csv('data.csv', encoding='gbk', names=['第一列', '第二列', '第三列', '第四列'])
2.#指定列:通过索引指定列名获取列
data_new[] 建立空表存储行信息 for i in range(len(csvPD)): lst_new = [] # 建立空列表存储行信息 if "未知版本" in str(csvPD['版本组件'][i]): print(csvPD['版本组件'][i]) # print(csvPD['匹配数量'][i]) # print(csvPD['git'][i]) # print(csvPD['来源链接'][i]) lst_new.append(csvPD['版本组件'][i]) lst_new.append(csvPD['匹配数量'][i]) lst_new.append(csvPD['git'][i]) lst_new.append(csvPD['来源链接'][i]) data_new.append(lst_new) # 添加每行信息
3.根据index查询
条件:首先导入的数据必须的有index
或者自己添加吧,方法简单,读取excel文件时直接加index_col
代码示例:
import pandas as pd #导入pandas库 excel_file = './try.xlsx' #导入excel数据 data = pd.read_excel(excel_file, index_col='姓名') #这个的index_col就是index,可以选择任意字段作为索引index,读入数据 print(data.loc['李四']) #使用loc函数来查找
4.已知数据在第几行找到想要的数据
假如我们的表中,有某个员工的工资数据为空了,那我们怎么找到自己想要的数据呢。
代码如下:
for i in data.columns: for j in range(len(data)): if (data[i].isnull())[j]: bumen = data.iloc[j, [0]] #找出缺失值所在的部门 data[i][j] = charuzhi(bumen)
首先检索全部的数据,然后我们可以用pandas中的iloc函数。上面的iloc[j, [2]]中j是具体的位置,【0】是你要得到的数据所在的column
"""根据条件查询某行数据""" import pandas as pd #导入pandas库 excel_file = './try.xlsx' #导入文件 data = pd.read_excel(excel_file) #读入数据 print(data.loc[data['部门'] == 'A', ['姓名', '工资']]) #部门为A,打印姓名和工资 print(data.loc[data['工资'] < 3000, ['姓名','工资']]) #查找工资小于3000的人
若要把这些数据独立生成excel文件或者csv文件:
添加以下代码:
"""导出为excel或csv文件"""
dataframe_1 = data.loc[data['部门'] == 'A', ['姓名', '工资']]
dataframe_2 = data.loc[data['工资'] < 3000, ['姓名', '工资']]
dataframe_1.to_excel('dataframe_1.xlsx')
dataframe_2.to_excel('dataframe_2.xlsx')
data.iloc[:,:2] #即全部行,前两列的数据
data['columns'] #columns即你需要的字段名称即可
#注意这列的columns不能是index的名称
#如果要打印index的话就data.index
data.columns #与上面的一样
data.iloc[:10,:][data.工资>6000] #找出前11行里工资大于6000的所有人的信息了5.指定单元格:1001A列23时的AQI值
keyWord="1001A" for i in range(len(csvPD)): if str(csvPD['hour'][i])=="23" and str(csvPD['type'][i])== "AQI": result=csvPD[keyWord][i] print(result)
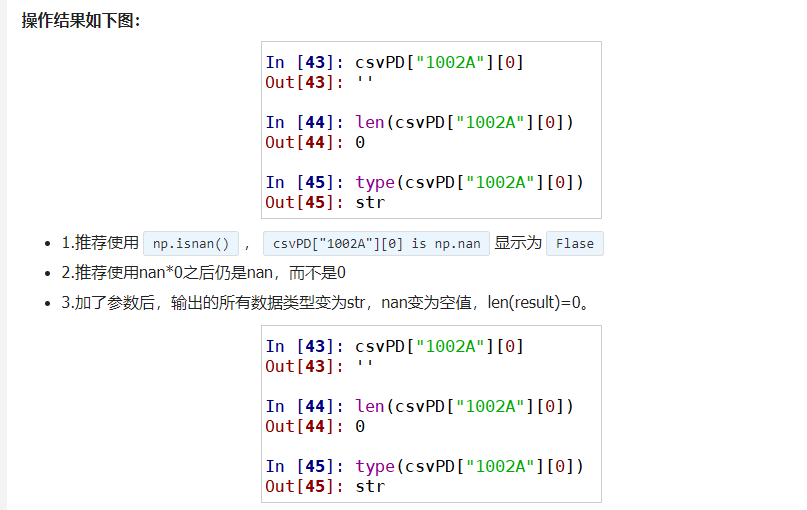
解决遇到的"NAN":
- csv文件中:1001A站点0时的AQI为空白值,返回的结果为NAN
- NAN全称:Not A Number
常规解决思路:
使用numpy函数来判断:np.isnan() 和 xxx is np.nan
通过运算操作判断:任何数字乘上0都是0
读取文件时加参数:pd.read_csv(file, keep_default_na=False)
加载全部内容