Java查找算法
刘Java 人气:01.查找概述
查找表: 所有需要被查的数据所在的集合,我们给它一个统称叫查找表。查找表(Search Table)是由同一类型的数据元素(或记录)构成的集合。
查找(Searching): 根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素(或记录)。若表中存在这样的一个记录,则称查找是成功的,此时查找的结果给出整个记录的信息,或指示该记录在查找表中的位置;若表中不存在关键字等于给定值的记录,则称查找不成功,此时查找的结果可给出一个“空”记录或“空”指针。
查找表分类: 查找表按照操作方式来分有两大种:静态查找表和动态查找表。
静态查找表(Static Search Table),只作查找操作的查找表。它的主要操作有:
- 查询某个“特定的”数据元素是否在查找表中。
- 检索某个“特定的”数据元素和各种属性。
动态查找表(Dynamic Search Table),在查找过程中同时插入查找表中不存在的数据元素,或者从查找表中删除已经存在的某个数据元素。显然动态查找表的操作就是两个:
- 查找时插入数据元素。
- 查找时删除数据元素。
查找结构: 为了提高查找的效率,我们需要专门为查找操作设置数据结构,这种面向查找操作的数据结构称为查找结构。
从逻辑上来说,查找所基于的数据结构是集合,集合中的记录之间没有本质关系。可是要想获得较高的查找性能,我们就不能不改变数据元素之间的关系,在存储时可以将查找集合组织成表、树等结构。
例如,对于静态查找表来说,我们不妨应用线性表结构来组织数据,这样可以使用顺序查找算法,如果再对主关键字排序,则可以应用二分查找等技术进行高效的查找。
如果是需要动态查找,则会复杂一些,可以考虑二叉排序树的查找技术。
另外,还可以用散列表结构来解决一些查找问题。
2.顺序查找
顺序查找(Sequential Search)又叫线性查找,是最基本的查找技术,它的查找过程是:从表中第一个(或最后一个)记录开始,逐个进行记录的关键字和给定值比较,若某个记录的关键字和给定值相等,则查找成功,找到所查的记录;如果直到最后一个(或第一个)记录,其关键字和给定值比较都不等时,则表中没有所查的记录,查找不成功。
顺序查找一般是一种在数组中查找数据的算法,是一种静态查找。
顺序查找的实现: 顺序查找非常简单,就是从头开始遍历内部数组,查看有没有关键字(key)。有的话就返回对应的索引。
设数组元素数量为n,则顺序查找的查找成功最短时间为O(1),最长为O(n),查找失败时间为O(n)。记作O(n)。
3.二分查找
3.1 二分查找概述
每次取中间记录查找的方法叫做二分查找。二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,二分查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
二分查找的基本思想是:在有序表中,取中间记录作为比较对象,若给定值与中间记录的关键字相等,则查找成功;若给定值小于中间记录的关键字,则在中间记录的左半区继续查找;若给定值大于中间记录的关键字,则在中间记录的右半区继续查找。不断重复上述过程,直到查找成功,或所有查找区域无记录,查找失败为止。
设有序数组元素数量为n,将其长度减半log n 次后,其中便只剩一个数据了,这样就能百分之百确定元素是否存在,则二分查找的查找成功最短时间为O(1),最长为O(logn)。查找失败最短时间为时间为O(1),最长为O(logn)。记作O(logn)。
二分查找的时间复杂度为O(logn),与线性查找的O(n) 相比速度上得到了指数倍提高(x = log2n,则n = 2^x)。但是,二分查找必须建立在数据已经排好序的基础上才能使用,因此添加数据时必须加到合适的位置,这就需要额外耗费维护数组的时间。 而使用线性查找时,数组中的数据可以是无序的,因此添加数据时也无须顾虑位置,直接把它加在末尾即可,不需要耗费时间。
综上,具体使用哪种查找方法,可以根据查找和添加两个操作哪个更为频繁来决定。
3.2 二分查找实现
对如下数据{0,1,16,24,35,47,59,62,73,88,99}进行二分查找,是否存在73、72这两个数。
public class Bisearch {
/**
* 有序的数组
*/
public int[] elements = new int[]{1, 16, 24, 35, 47, 59, 62, 73, 88, 99};
@Test
public void test1() {
//7
System.out.println(bisearch(73));
//4
System.out.println(bisearch(47));
//-1
System.out.println(bisearch(72));
//求logn
System.out.println(Math.log((double) 10) / Math.log((double) 2));
}
/**
* 折半查找的实现
*
* @param key 要查找的数据
* @return 查找到的索引, 或者-1 表示查找到
*/
public int bisearch(int key) {
int low = 0;
int high = elements.length - 1;
int mid;
//不在范围内,直接返回-1
if (elements[low] > key || elements[high] < key) {
return -1;
}
//开始折半查找
while (low <= high) {
//折半
mid = (low + high) / 2;
/*若查找值比中值小*/
if (elements[mid] > key) {
//最高下标调整到中位下标小一位
high = mid - 1;
/*若查找值比中值大*/
} else if (elements[mid] < key) {
//最低下标调整到中位下标大一位
low = mid + 1;
/*若查找值等于中值*/
} else {
//说明mid即为查找到的位置
return mid;
}
}
//未查找到,返回-1
return -1;
}
}上面的数据,采用二分查找之后其查找结构如下图:
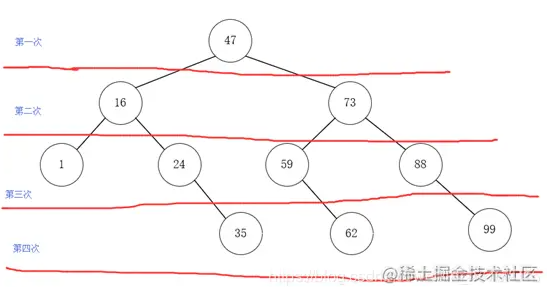
从上图可以看出来二分查找等于是把静态有序查找表分成了两棵子树,即查找结果只需要找其中的一半数据记录即可,等于工作量少了一半,然后继续二分查找,循环重复执行该操作就可以找到目标数据,或得出目标数据不存在的结论,最高需要查找logn≈4次。效率当然是非常高了。
4.插值查找
4.1 插值查找概述
插值查找(Interpolation Search),有序表的一种查找方式。 插值查找算法类似于二分查找,不同的是插值查找每次从自适应 mid 处开始查找。
这里的自适应,很好解释,比如要在取值范围0~10000之间100个元素从小到大均匀分布的数组中查找5,我们自然会考虑从数组下标较小的开始查找。 将二分查找中的求 mid 索引的公式,变换一下格式得到:
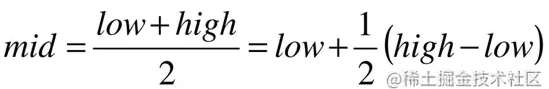
也就是mid等于最低下标low加上最高下标high与low的差的一半。算法科学家们考虑的就是将这个1/2进行改进,改进为下面的计算方案:
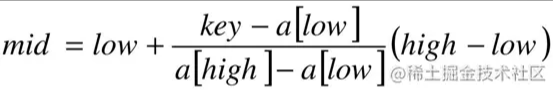
假设a[10]={1,16,24,35,47,59,62,73,88,99},low=0,high=9,则a[low]=1,a[high]=99,如果我们要找的是key=16时,按原来折半的做法,我们需要四次才可以得到结果,但如果用新办法,计算(key-a[low])/(a[high]-a[low])=(16-1)/(99-1)≈0.153,即mid≈0+0.153×(9-0)=1.377,取整得到mid=1,我们只需要一次就查找到结果了,显然大大提高了查找的效率。
这就是插值查找和二分查找的不同之处,插值查找是根据要查找的关键字key与查找表中最大最小记录的关键字比较后的查找方法,其核心就在于插值的计算公式(key-a[low])/(a[high]-a[low])。从时间复杂度来看,它也是O(logn),但对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好得多。反之,由于插值的计算依赖于最大值和最小值,因此数组中如果分布类似{0,1,2,2000,2001,......,999998,999999}这种极端不均匀的数据,用插值查找效率比二分查找低。因此插值查找应用有限。
4.2 插值查找实现
public class FibonacciSearch {
/**
* 有序的数组
*/
public int[] elements = new int[]{1, 16, 24, 35, 47, 59, 62, 73, 88, 99};
/**
* 插值查找的实现
*
* @param key 要查找的数据
* @return 查找到的索引, 或者-1 表示查找到
*/
public int interpolationSearch(int key) {
int low = 0;
int high = elements.length - 1;
int mid;
//不在范围内,直接返回-1
if (elements[low] > key || elements[high] < key) {
return -1;
}
//开始插值查找
while (low <= high) {
//插值
mid = low + (high - low) * (key - elements[low]) / (elements[high] - elements[low]);
/*若查找值比中值小*/
if (elements[mid] > key) {
//最高下标调整到中位下标小一位
high = mid - 1;
/*若查找值比中值大*/
} else if (elements[mid] < key) {
//最低下标调整到中位下标大一位
low = mid + 1;
/*若查找值等于中值*/
} else {
//说明mid即为查找到的位置
return mid;
}
}
//未查找到,返回-1
return -1;
}
@Test
public void test1() {
System.out.println(interpolationSearch(315));
}
}5.斐波那契查找
5.1 斐波那契查找概述
斐波那契查找(Fibonacci Search)也是有序表的一种查找方式,同样属于二分查找的一个优化,它是利用了黄金分割原理(斐波那契数列)来实现的。改变了中间结点(mid)的位置,mid不再是中间或插值得到,而是位于黄金分割点附近,即mid=low+F(k-1)-1(F代表斐波那契数列)。
斐波那契数列:即1,1,2,3,5,8,13...,从第三个数开始,后面的数都等于前两个数之和,而斐波那契查找就是利用的斐波那契数列来实现查找的。初始化的斐波那契数列最后一位要大于等于数组元素的size-1。
查找步骤:
假设表中有 n 个元素,查找过程为获取区间的下标 mid=low + fibonacci[k - 1] - 1 ,对 mid 的关键字与给定值的关键字比较:
- 如果与给定关键字相同,则查找成功,返回mid和high的最小值;
- 如果给定关键字大,向右查找并减小2个斐波那契区间;
- 如果给定关键字小,向左查找并减小1个斐波那契区间;
- 重复过程,直到找到关键字(成功)或区间为空集(失败)。
5.2 斐波那契查找实现
public class FibonacciSearch {
/**
* 有序的数组
*/
public int[] elements = new int[]{1, 16, 24, 35, 47, 59, 62, 73, 88, 99};
/**
* 对应的斐波拉契数组,数组的最大值>=elements.length-1
*/
public int[] fibonacci = new int[]{1, 1, 2, 3, 5, 8, 13};
@Test
public void test1() {
//3
System.out.println(fibonacciSearch2(35));
}
/**
* 斐波那契查找的实现
*
* @param key 要查找的数据
* @return 查找到的索引, 或者-1 表示查找到
*/
public int fibonacciSearch2(int key) {
//最小索引
int low = 0;
//最大索引
int high = elements.length - 1;
//不在范围内,直接返回-1
if (elements[low] > key || elements[high] < key) {
return -1;
}
int k = 0, i, mid;
/*计算high位于斐波那契数列的位置 */
//这里high为9,fibonacci[5]<9<fibonacci[6] ,取大的,即k=6
while (high > fibonacci[k]) {
k++;
}
/*扩展数组*/
//扩展原数组,长度扩展为fibonacci[k]=13,即多加了三个位置elements[10],elements[11],elements[12]
elements = Arrays.copyOf(elements, fibonacci[k]);
//为了保证数组的顺序,把扩展的值都设置为原始数组的最大值
for (i = high + 1; i < elements.length; i++) {
elements[i] = elements[high];
}
/*开始斐波那契查找*/
while (low <= high) {
/* 计算当前分隔的下标索引,取的是黄金分割点 7-4-2-1-0 7-10*/
mid = low + fibonacci[k - 1] - 1;
/* 若查找记录小于当前分隔记录 */
if (key < elements[mid]) {
/* 最高下标调整到分隔下标mid-1处 */
high = mid - 1;
/* 斐波那契数列下标减一位 */
k = k - 1;
}
/* 若查找记录大于当前分隔记录 */
else if (key > elements[mid]) {
/* 最低下标调整到分隔下标mid+1处 */
low = mid + 1;
/* 斐波那契数列下标减两位 */
k = k - 2;
} else {
/* 若mid <= high则说明mid即为查找到的位置,返回mid */
/* 若mid>high说明是补全数值,返回high */
return Math.min(mid, high);
}
}
return -1;
}
}具体步骤
如果查找的key等于35:
- 程序开始运行,数组elements={1,16,24,35,47,59,62,73,88,99},high =9,要查找的关键字key=35。注意此时我们已经有了事先计算好的全局变量数组fibonacci的具体数据,它是斐波那契数列,fibonacci ={1,1,2,3,5,8,13},计算原则是斐波那契数列的最大值是大于等于elements.length-1的最小值。
- 计算high=9位于斐波那契数列的索引位置,可能是位于某两个索引位置之间,那么取最大的索引位置。fibonacci[5]<9<fibonacci[6] ,取大的,即k=6。
- fibonacci[6]=13,计算时数组长度应该为13,因此我们需要对原数组elements扩展长度10至13,扩展后后面的索引位置均没有赋值,为了保证数组的有序,赋值为原素组elements的最大值elements[10]= elements[11]= elements[12]= elements[9]。
- 然后开始斐波那契查找:
寻找mid下标,由于low=0且k=6,我们第一个要对比的数值是从下标为mid=0 + fibonacci[6 - 1] – 1 = 7开始的。

此时elements[7]=73>key=35,因此查找记录小于当前分隔记录;得到high=7-1=6,k=6-1=5。再次循环,计算mid=0+F[5-1]-1=4。

此时elements[4]=47>key=35,因此查找记录小于当前分隔记录;得到high=4-1=3,k=5-1=4。再次循环,mid=0+F[4-1]-1=2。

此时elements[2]=24<key=35,因此查找记录大于当前分隔记录;得到low=2+1=3,k=4-2=2。再次循环,mid=3+F[2-1]-1=3。

此时elements[3]=35<key=35,因此查找记录等于当前分隔记录;返回此时mid=3和high=3的最小值,斐波那契查找结束。即返回3
如果查找的key等于99:
前几步都是一样的,主要是斐波那契查找不一样:
寻找mid下标,由于low=0且k=6,我们第一个要对比的数值是从下标为mid=0 + fibonacci[6 - 1] – 1 = 7开始的。

此时elements[7]=73<key=99,因此查找记录大于当前分隔记录;得到low=7+1=8,k=6-2=4。再次循环,计算mid=8+F[4-1]-1=10。注意此时10的索引位置已经到了扩展的三个元素中了。

此时elements[10]=99=key=99,因此查找记录等于当前分隔记录;返回此时mid=10和high=9的最小值,斐波那契查找结束,即返回9。
这里可以看出来扩展数组的用意,因为mid有可能算出超出原数组索引长度的索引;同时也可以看出来最后还要比较取最小值的用意,因为扩展的元素只是我们比较时添加的,实际上原数组并不存在这个索引,因此要取high,即原数组存在的索引;同时这也是为扩展的元素赋值的用意,要保证mid有值-但是不超过最大值,因此就取最大值。
5.3 总结
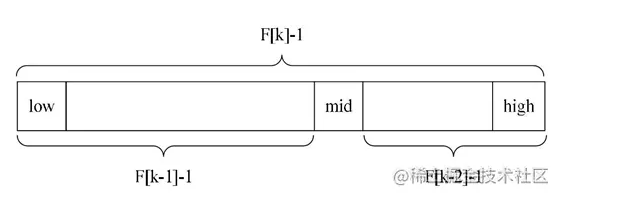
如上图,斐波那契查找的特点就是左侧半区范围大于右侧半区范围。如果要查找的记录在mid右侧,则左侧的数据都不用再判断了,不断反复进行下去,对处于右侧当中的大部分数据,其工作效率要高一些。 所以尽管斐波那契查找的时间复杂也为O(logn),但就平均性能来说,斐波那契查找要优于二分查找。可惜如果是最坏情况,比如这里key=1,那么始终都处于左侧长半区在查找,则查找效率要低于二分查找。
还有比较关键的一点,二分查找是进行加法与除法运算(mid=(low+high)/2),插值查找进行复杂的四则运算(mid=low+(highlow)*(key-a[low])/(a[high]-a[low])),而斐波那契查找只是最简单加减法运算(mid=low+F[k-1]-1),在海量数据的查找过程中,这种细微的差别可能会影响最终的查找效率,但是斐波那契额查找同样需要额外的空间。
加载全部内容