python生成mysql结构文档
henghenghahei_3 人气:0最近因为项目原因需要编写数据库设计文档,但是由于数据表太多,手动编写耗费的时间太久,所以搞了一个简单的脚本快速生成数据库结构,保存到word文档中。
安装pymysql和document
pip install pymysql pip install document
脚本
# -*- coding: utf-8 -*-
import pymysql
from docx import Document
from docx.shared import Pt
from docx.oxml.ns import qn
db = pymysql.connect(host='127.0.0.1', #数据库服务器IP
port=3306,
user='root',
passwd='123456',
db='test_db') #数据库名称)
#根据表名查询对应的字段相关信息
def query(tableName):
#打开数据库连接
cur = db.cursor()
sql = "select b.COLUMN_NAME,b.COLUMN_TYPE,b.COLUMN_COMMENT from (select * from information_schema.`TABLES` where TABLE_SCHEMA='test_db') a right join(select * from information_schema.`COLUMNS` where TABLE_SCHEMA='test_db_test') b on a.TABLE_NAME = b.TABLE_NAME where a.TABLE_NAME='" + tableName+"'"
cur.execute(sql)
data = cur.fetchall()
cur.close
return data
#查询当前库下面所有的表名,表名:tableName;表名+注释(用于填充至word文档):concat(TABLE_NAME,'(',TABLE_COMMENT,')')
def queryTableName():
cur = db.cursor()
sql = "select TABLE_NAME,concat(TABLE_NAME,'(',TABLE_COMMENT,')') from information_schema.`TABLES` where TABLE_SCHEMA='test_db_test'"
cur.execute(sql)
data = cur.fetchall()
return data
#将每个表生成word结构,输出到word文档
def generateWord(singleTableData,document,tableName):
p=document.add_paragraph()
p.paragraph_format.line_spacing=1.5 #设置该段落 行间距为 1.5倍
p.paragraph_format.space_after=Pt(0) #设置段落 段后 0 磅
#document.add_paragraph(tableName,style='ListBullet')
r=p.add_run('\n'+tableName)
r.font.name=u'宋体'
r.font.size=Pt(12)
table = document.add_table(rows=len(singleTableData)+1, cols=3,style='Table Grid')
table.style.font.size=Pt(11)
table.style.font.name=u'Calibri'
#设置表头样式
#这里只生成了三个表头,可通过实际需求进行修改
for i in ((0,'NAME'),(1,'TYPE'),(2,'COMMENT')):
run = table.cell(0,i[0]).paragraphs[0].add_run(i[1])
run.font.name = 'Calibri'
run.font.size = Pt(11)
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '宋体')
for i in range(len(singleTableData)):
#设置表格内数据的样式
for j in range(len(singleTableData[i])):
run = table.cell(i+1,j).paragraphs[0].add_run(singleTableData[i][j])
run.font.name = 'Calibri'
run.font.size = Pt(11)
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '宋体')
#table.cell(i+1, 0).text=singleTableData[i][1]
#table.cell(i+1, 1).text=singleTableData[i][2]
#table.cell(i+1, 2).text=singleTableData[i][3]
if __name__ == '__main__':
#定义一个document
document = Document()
#设置字体默认样式
document.styles['Normal'].font.name = u'宋体'
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
#获取当前库下所有的表名信息和表注释信息
tableList = queryTableName()
#循环查询数据库,获取表字段详细信息,并调用generateWord,生成word数据
#由于时间匆忙,我这边选择的是直接查询数据库,执行了100多次查询,可以进行优化,查询出所有的表结构,在代码里面将每个表结构进行拆分
for singleTableName in tableList:
data = query(singleTableName[0])
generateWord(data,document,singleTableName[1])
#保存至文档
document.save('数据库设计.docx')
生成的word文档预览
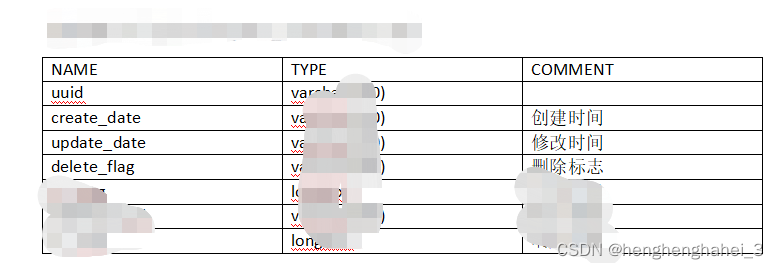
加载全部内容