线程池实现原理总结
负债程序猿 人气:0要理解实现原理,必须把线程池的几个参数彻底搞懂,不要死记硬背
一、线程池参数
- 1、corePoolSize(必填):核心线程数。
- 2、maximumPoolSize(必填):最大线程数。
- 3、keepAliveTime(必填):线程空闲时长。如果超过该时长,非核心线程就会被回收。
- 4、unit(必填):指定keepAliveTime的时间单位。常用的有:TimeUnit.MILLISECONDS(毫秒)、TimeUnit.SECONDS(秒)、TimeUnit.MINUTES(分)。
- 5、workQueue(必填):任务队列。通过线程池的execute()方法提交的Runnable对象将存储在该队列中。
- 6、threadFactory(可选):线程工厂。一般就用默认的。
- 7、handler(可选):拒绝策略。当线程数达到最大线程数时就要执行饱和策略。
说下核心线程数和最大线程数的区别
拒绝策略可选值:
1、AbortPolicy(默认):放弃任务并抛出RejectedExecutionException异常。
2、CallerRunsPolicy:由调用线程处理该任务。
3、DiscardPolicy:放弃任务,但是不抛出异常。可以配合这种模式进行自定义的处理方式。
4、DiscardOldestPolicy:放弃队列最早的未处理任务,然后重新尝试执行任务。
二、线程池执行流程
上个流程图,先试着自己看下能不能看懂
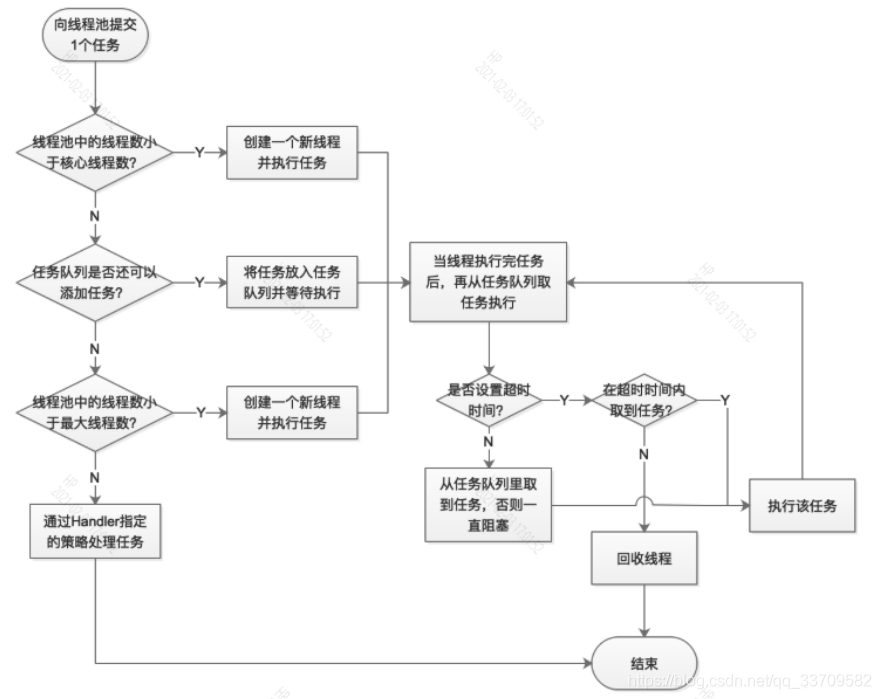
简短的总结下线程池执行流程:
- 1、一个任务提交到线程池后,如果当前的线程数没达到核心线程数,则新建一个线程并且执行新任务,注意一点,这个新任务执行完后,该线程不会被销毁;
- 2、如果达到了,则判断任务队列满了没,如果没满,则将任务放入任务队列;
- 3、如果满了,则判断当前线程数量是否达到最大线程数,如果没达到,则创建新线程来执行任务,注意,如果线程池中线程数量大于核心线程数,每当有线程超过了空闲时间,就会被销毁,直到线程数量不大于核心线程数;
- 4、如果达到了最大线程数,并且任务队列满了,就会执行饱和策略;
三、四种现成的线程池
不想自己new线程池的话,可以用现成的
1、定长线程池(FixedThreadPool)
特点:只有核心线程,线程数量固定,执行完立即回收,任务队列为链表结构的有界队列。
应用场景:控制线程最大并发数
2、定时线程池(ScheduledThreadPool )
特点:核心线程数量固定,非核心线程数量无限,执行完闲置10ms后回收,任务队列为延时阻塞队列。
应用场景:执行定时或周期性的任务。
3、可缓存线程池(CachedThreadPool)
特点:无核心线程,非核心线程数量无限,执行完闲置60s后回收,任务队列为不存储元素的阻塞队列。
应用场景:执行大量、耗时少的任务。
4、单线程化线程池(SingleThreadExecutor)
特点:只有1个核心线程,无非核心线程,执行完立即回收,任务队列为链表结构的有界队列。
应用场景:不适合并发但可能引起IO阻塞性及影响UI线程响应的操作,如数据库操作、文件操作等。
上述四个线程池虽然方便,但是阿里巴巴规范明确说明不建议使用,因为可能会造成内存溢出,具体原因如下:
FixedThreadPool和SingleThreadExecutor:主要问题是堆积的请求处理队列均采用LinkedBlockingQueue,可能会耗费非常大的内存,严重的直接导致内存溢出。CachedThreadPool和ScheduledThreadPool:主要问题是它们的最大线程数是Integer.MAX_VALUE,可能会创建数量非常多的线程,严重的直接导致内存溢出。
加载全部内容