python selenium登录豆瓣
侯小啾 人气:0使用python爬虫selenium访问豆瓣https://www.douban.com/,实现模拟登录过程。
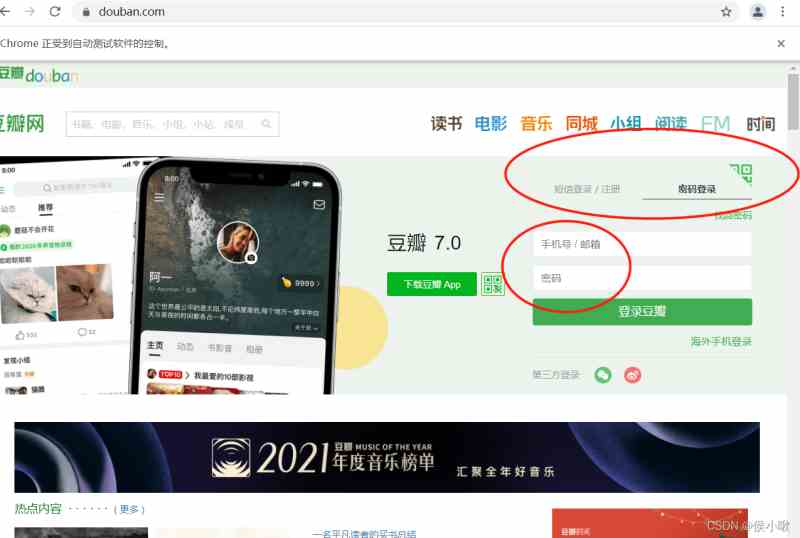
网页界面如图所示
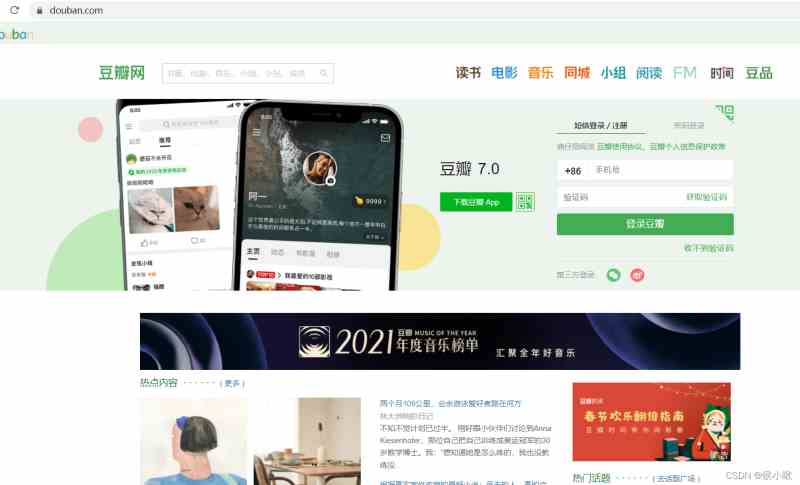
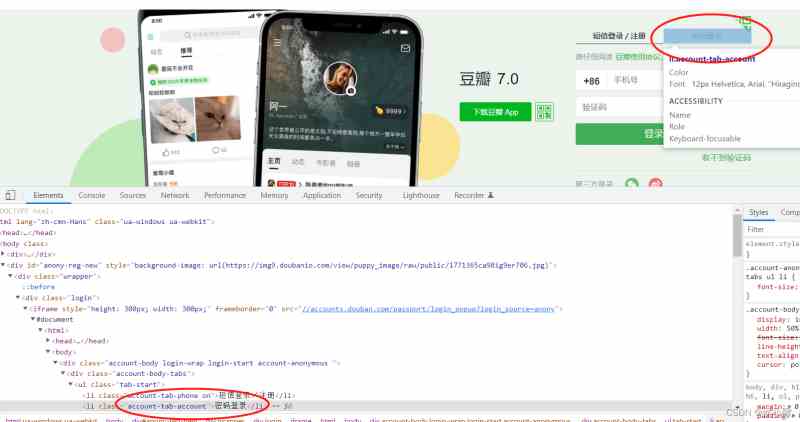
首先导包后,定位图中 密码登录 的element,并点击。
经分析,该标签的class_name为’account-tab-account’。
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('https://www.douban.com/')
# 点击 密码登录 按钮 。但是找不到该element,不存在网页中
driver.find_element_by_class_name('account-tab-account').click()
但是该段代码结果出现了报错,定位不到目标元素。
经核实,发现该element并不存在与网页源码中。
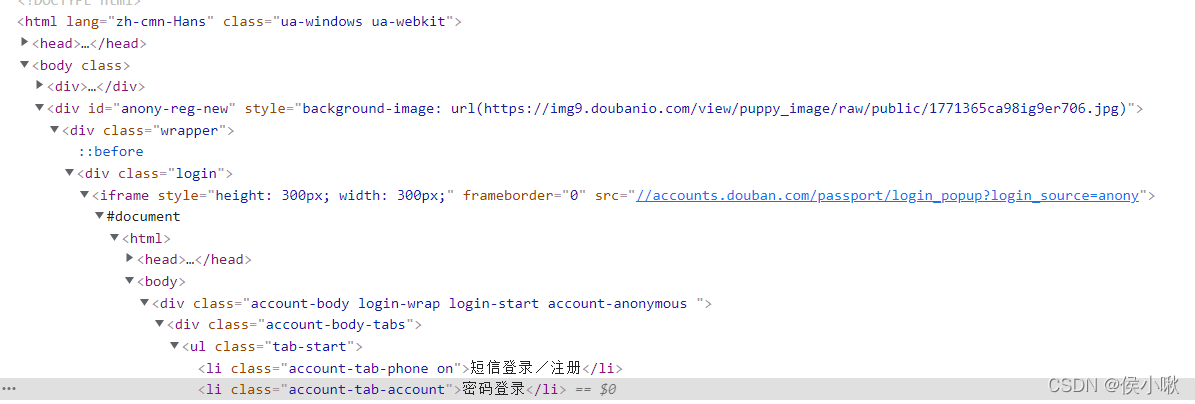
经分析,登录界面存在于一个叫iframe的标签中。iframe这个标签是嵌套在这个网页中的,单独拿出来也能用。所以并不存在于网页源码中。
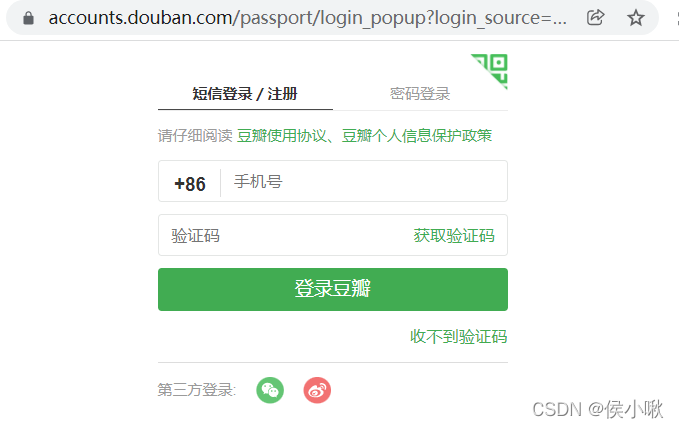
访问该src链接可以看到如下界面:
iframe中的元素不属于原网页的元素,但是iframe在网页源码中,要获取其元素,先定位iframe:

# 找到登陆的iframe
login_iframe = driver.find_element_by_xpath('//div[@class="login"]/iframe')
# 切换到iframe
driver.switch_to.frame(login_iframe)
# 点击密码登陆
driver.find_element_by_class_name('account-tab-account').click()
找到之后,还要切换进去,使用 switch_to 方法。
经测试,点击成功。
接下来,就是输入账号和密码过程了
# 填写账号
driver.find_element_by_id('username').send_keys('123456789@163.com')
time.sleep(2)
# 填写密码
driver.find_element_by_id('password').send_keys('xxxx')
登录
# 点击登陆按钮
driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[1]/div[5]/a').click()
也可以通过JS点击
execute_script() 方法
login_button = driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[1]/div[5]/a')
driver.execute_script("arguments[0].click()", login_button)
此外,在输入账号密码前,有时也会遇到输入框中有诸如“请输入账号”、“请输入密码”这样的文字(默认值),需要清除掉后才能输入,否则输入内容会重叠。(此例中不会,此例中输入新内容后自动覆盖原有的“手机号/邮箱”、“密码”字样)清楚输入框中的文字,使用 clear 方法。
# 以清除用户名一栏的内容为例
driver.find_element_by_id('username').clear()
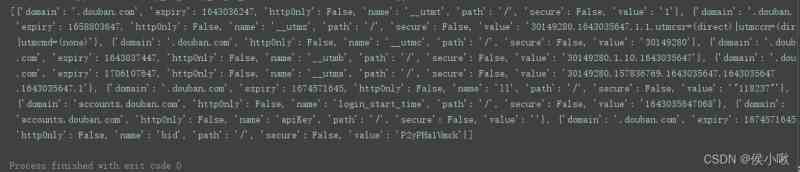
最后,模拟登陆的目的,一般是为了获取cookie。使用到以下命令。
get_cookies()
print(driver.get_cookies())
加载全部内容