Python词云图
松鼠爱吃饼干 人气:2
知识点介绍
爬虫基本思路流程
requests模块的使用
pandas保存表格数据
pyecharts做词云图可视化
环境介绍
python 3.8
pycharm
requests >>> pip install requests
pyecharts >>> pip install pyecharts
网站分析
打开X讯视频的网页,点开《开端》,播放视频,弹幕随之出现再屏幕之上。
首先我们需要找到相应的弹幕出自于哪里,打开网页开发者工具,Ctrl+F输入:“那么多座位你俩非要挤一起吗”,找到弹幕所在的页面
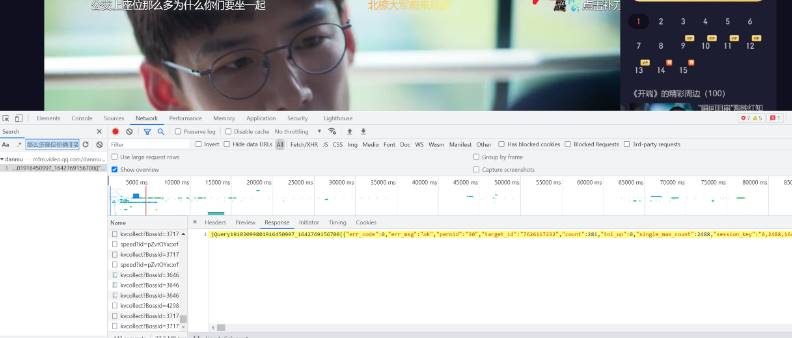
观察发现这是一个json,其弹幕内容包含在该json中的comments之中

找到页面之后观察该页面的请求头,请求方式为get,target_id为该电视剧的网页ID,得到该电视剧的链接地址主要由target_id和timestamp时间戳构成,形如 http://mfm.video.qq.com/danmu?timestamp=0&target_id=xxxxx 且该json表明时间戳每30会更新一次弹幕信息,单位为秒,对网站进行分析之后,我们直接看到代码。
完整爬虫代码实现
timestamp每增加30就会更改整个弹幕页面,在循环中每次增加30,并更改target_id即电视剧的每一集来获取每一集的弹幕信息,下面便是编写的获取弹幕的函数。这里以第一集为例子。
import requests
import pandas as pd
# 构建一个列表存储数据
data_set = []
for page in range(15, 600, 30):
try:
# 1. 发送请求
url = f'https://mfm.video.qq.com/danmu?otype=json&target_id=7626117232%26vid%3Dn0041aa087e&session_key=0%2C0%2C0×tamp={page}&_=1641804763748'
response = requests.get(url=url)
# 2. 获取数据
json_data = response.json()
# 3. 解析数据
comments = json_data['comments']
for comment in comments:
data_dict = {}
data_dict['commentid'] = comment['commentid']
data_dict['content'] = comment['content']
data_dict['opername'] = comment['opername']
print(data_dict)
data_set.append(data_dict)
except:
pass
# 4. 保存数据
df = pd.DataFrame(data_set)
df.to_csv('data.csv', index=False)
结果展示
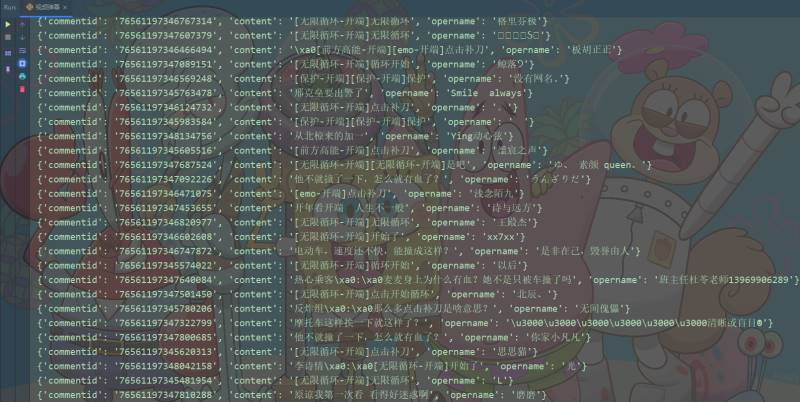
word = dfword3['word'].tolist()
count = dfword3['count'].tolist()
a = [list(z) for z in zip(word, count)]
c = (
WordCloud()
.add('', a, word_size_range=[10, 50], shape='circle')
.set_global_opts(title_opts=opts.TitleOpts(title="词云图"))
)
c.render_notebook()

总结
加载全部内容