python爬取中国大学排名信息
海岛码农 人气:0程序解决问题如下:
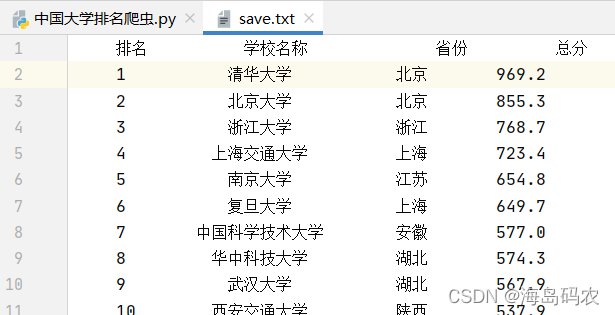
利用python网络爬虫爬取中国大学排名网站上的排名信息,将排名前20的大学的信息保存为文本文件,并在窗口打印出这20所大学的信息,按列打印和保存。
程序代码如下:
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
hdfd = tds[0].find('div')
tt = hdfd.string.split()
ff = "".join(tt)
attr = tds[1].find('a')
hh = tds[4].string.split()
hg = "".join(hh)
shf=tds[2].text.split()
shfn="".join(shf)
ulist.append([ff, attr.string,shfn,hg])
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{4}^10}\t{2:^10}\t{3:^10}"
print(tplt.format("排名","学校名称","省份","总分", chr(12288)))
with open('save.txt', 'w+', encoding='utf-8') as f:
f.write(tplt.format("排名","学校名称","省份","总分", chr(12288)))
f.write('\n')
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2],u[3],chr(12288)))
with open('save.txt', 'a', encoding='utf-8') as f:
f.write(tplt.format(u[0], u[1], u[2],u[3],chr(12288)))
f.write('\n')
def main():
with open('save.txt', 'w+', encoding='utf-8') as f:
f.write("排名,学校,省份,总分\n")
f.close()
uinfo = []
url = 'https://www.shanghairanking.cn/rankings/bcur/2021'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20)
main()程序运行结果如下:

加载全部内容