Java网站聚合
炒鸡辣鸡123 人气:0互联网上有数以万亿计的网站,每个网站大都具有一定的功能。搜索引擎虽然对互联网上的部分网站建立了索引,但是其作为一个大而全的搜索系统,无法很好的定位到一些特殊的需求,基于这样的背景,我尝试了写了一个网站数据聚合的程序。现在将原理和实现代码分享给大家。
原理
可以把互联网上的网站看做一张巨大的连通图,不同的网站处于不同的连通块中,然后以广度优先算法遍历这个连通块,就能找到所有的网站域名,利用广度优先算法遍历该连通块的结构可以抽象为:
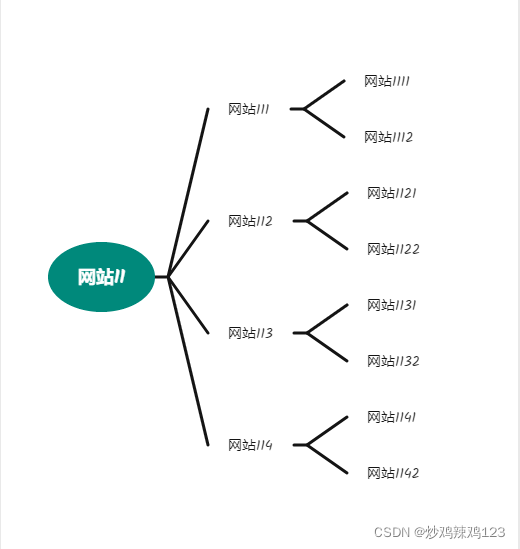
然后,我们对该网站的返回内容进行分词,剔除无意义的词语和标点符号,就得出该网站首页的关键词排序,我们可以取词频在(10,50)区间范围内的为关键词,然后将这些关键词作为网站主题,把网站的信息放到以该词为名字的markdown文件中备用。
同理,我们也对该网站返回内容的title部分进行分词,因为title是网站开发者对网站功能的浓缩,也比较重要,同理,也将这些关键词作为网站主题,把网站的信息放到以该词为名字的markdown文件中备用。
最后,我们只需要从这些文件中人工做筛选,或者以这些数据放到elasticsearch中,做关键词搜索引擎即可。以达到想用的时候随时去拿的目的。
不过,当你遍历连通块没有收敛时,得到的数据还是很少的,某些分类往往只有一两个网站。
实现代码
页面下载
页面下载我使用的是httpClient,前期考虑用playwrite来做,但是两者性能差距太大,后者效率太低了,所以舍弃了部分准确性(即web2.0技术的网站,前者无法拿到数据),所以准确的说我实现的仅仅是web1.0的网站分类搜索引擎的页面下载功能。
public SendReq.ResBody doRequest(String url, String method, Map<String, Object> params) {
String urlTrue = url;
SendReq.ResBody resBody = SendReq.sendReq(urlTrue, method, params, defaultHeaders());
return resBody;
}
其中,SendReq是我封装的一个httpClient的类,只是实现了一个页面下载的功能,你可以替换为RestTemplate或者别的发起http(s)请求的方法。
解析返回值中的所有链接
因为是连通块遍历,那么定义的连通网站就是该网站首页里面所有的外链的域名所在的站,所以我们需要提取链接,直接使用正则表达式提取即可。
public static List<String> getUrls(String htmlText) {
Pattern pattern = Pattern.compile("(http|https):\\/\\/[A-Za-z0-9_\\-\\+.:?&@=\\/%#,;]*");
Matcher matcher = pattern.matcher(htmlText);
Set<String> ans = new HashSet<>();
while (matcher.find()){
ans.add(DomainUtils.getDomainWithCompleteDomain(matcher.group()));
}
return new ArrayList<>(ans);
}
解析返回值中的title
title是网站开发者对网站功能的浓缩,所以很有必要将title解析出来做进一步处理
public static String getTitle(String htmlText){
Pattern pattern = Pattern.compile("(?<=title\\>).*(?=</title)");
Matcher matcher = pattern.matcher(htmlText);
Set<String> ans = new HashSet<>();
while (matcher.find()){
return matcher.group();
}
return "";
}
去除返回值中的标签
因为后续步骤需要对网站返回值进行分词,所以需要对页面中的标签和代码进行去除。
public static String getContent(String html) {
String ans = "";
try {
html = StringEscapeUtils.unescapeHtml4(html);
html = delHTMLTag(html);
html = htmlTextFormat(html);
return html;
} catch (Exception e) {
e.printStackTrace();
}
return ans;
}
public static String delHTMLTag(String htmlStr) {
String regEx_script = "<script[^>]*?>[\\s\\S]*?<\\/script>"; //定义script的正则表达式
String regEx_style = "<style[^>]*?>[\\s\\S]*?<\\/style>"; //定义style的正则表达式
String regEx_html = "<[^>]+>"; //定义HTML标签的正则表达式
Pattern p_script = Pattern.compile(regEx_script, Pattern.CASE_INSENSITIVE);
Matcher m_script = p_script.matcher(htmlStr);
htmlStr = m_script.replaceAll(""); //过滤script标签
Pattern p_style = Pattern.compile(regEx_style, Pattern.CASE_INSENSITIVE);
Matcher m_style = p_style.matcher(htmlStr);
htmlStr = m_style.replaceAll(""); //过滤style标签
Pattern p_html = Pattern.compile(regEx_html, Pattern.CASE_INSENSITIVE);
Matcher m_html = p_html.matcher(htmlStr);
htmlStr = m_html.replaceAll(""); //过滤html标签
return htmlStr.trim();
}分词
分词算法使用之前讲NLP入门的文章里面提到的hanlp即可
private static Pattern ignoreWords = Pattern.compile("[,.0-9_\\- ,、:。;;\\]\\[\\/!()【】*?“”()+:|\"%~<>——]+");
public static Set<Word> separateWordAndReturnUnit(String text) {
Segment segment = HanLP.newSegment().enableOffset(true);
Set<Word> detectorUnits = new HashSet<>();
Map<Integer, Word> detectorUnitMap = new HashMap<>();
List<Term> terms = segment.seg(text);
for (Term term : terms) {
Matcher matcher = ignoreWords.matcher(term.word);
if (!matcher.find() && term.word.length() > 1 && !term.word.contains("�")) {
Integer hashCode = term.word.hashCode();
Word detectorUnit = detectorUnitMap.get(hashCode);
if (Objects.nonNull(detectorUnit)) {
detectorUnit.setCount(detectorUnit.getCount() + 1);
} else {
detectorUnit = new Word();
detectorUnit.setWord(term.word.trim());
detectorUnit.setCount(1);
detectorUnitMap.put(hashCode, detectorUnit);
detectorUnits.add(detectorUnit);
}
}
}
return detectorUnits;
}获取分词结果的数量前十个
这里为了去掉词频过多的词的干扰,所以只取词频小于50的词的前十
public static List<String> print2List(List<Word> tmp,int cnt){
PriorityQueue<Word> words = new PriorityQueue<>();
List<String> ans = new ArrayList<>();
for (Word word : tmp) {
words.add(word);
}
int count = 0;
while (!words.isEmpty()) {
Word word = words.poll();
if (word.getCount()<50){
ans.add(word.getWord() + " " + word.getCount());
count ++;
if (count >= cnt){
break;
}
}
}
return ans;
}
方法就是放到优先队列中一个一个取出来,优先队列是使用大顶堆实现的,所以取出来一定是有序的。如果想了解大顶堆的朋友,可以看我前面的文章。
值得注意的是,优先队列中放入的类必须是可排序的,所以,这里的Word也是可排序的,简化的代码如下:
public class Word implements Comparable{
private String word;
private Integer count = 0;
... ...
@Override
public int compareTo(Object o) {
if (this.count >= ((Word)o).count){
return -1;
}else {
return 1;
}
}
}好了,现在准备工作已经做好了。下面开始实现程序逻辑部分。
遍历网站连通块
利用广度优先遍历网站连通块,之前的文章有专门讲利用队列写广度优先遍历。现在就使用该方法。
public void doTask() {
String root = "http://" + this.domain + "/";
Queue<String> urls = new LinkedList<>();
urls.add(root);
Set<String> tmpDomains = new HashSet<>();
tmpDomains.add(DomainUtils.getDomainWithCompleteDomain(root));
while (!urls.isEmpty()) {
String url = urls.poll();
SendReq.ResBody html = doRequest(url, "GET", new HashMap<>());
System.out.println("当前的请求为 " + url + " 队列的大小为 " + urls.size() + " 结果为" + html.getCode());
if (html.getCode().equals(0)) {
ignoreSet.add(DomainUtils.getDomainWithCompleteDomain(url));
try {
GenerateFile.createFile2("moneyframework/generate/ignore", "demo.txt", ignoreSet.toString());
} catch (IOException e) {
e.printStackTrace();
}
continue;
}
OnePage onePage = new OnePage();
onePage.setUrl(url);
onePage.setDomain(DomainUtils.getDomainWithCompleteDomain(url));
onePage.setCode(html.getCode());
String title = HtmlUtil.getTitle(html.getResponce()).trim();
if (!StringUtils.hasText(title) || title.length() > 100 || title.contains("�")) continue;
onePage.setTitle(title);
String content = HtmlUtil.getContent(html.getResponce());
Set<Word> words = Nlp.separateWordAndReturnUnit(content);
List<String> wordStr = Nlp.print2List(new ArrayList<>(words), 10);
handleWord(wordStr, DomainUtils.getDomainWithCompleteDomain(url), title);
onePage.setContent(wordStr.toString());
if (html.getCode().equals(200)) {
List<String> domains = HtmlUtil.getUrls(html.getResponce());
for (String domain : domains) {
int flag = 0;
for (String i : ignoreSet) {
if (domain.endsWith(i)) {
flag = 1;
break;
}
}
if (flag == 1) continue;
if (StringUtils.hasText(domain.trim())) {
if (!tmpDomains.contains(domain)) {
tmpDomains.add(domain);
urls.add("http://" + domain + "/");
}
}
}
}
}
}调用测试
@Service
public class Task {
@PostConstruct
public void init(){
new Thread(new Runnable() {
@Override
public void run() {
while (true){
try {
HttpClientCrawl clientCrawl = new HttpClientCrawl("http://www.mengwa.store/");
clientCrawl.doTask();
}catch (Exception e){
e.printStackTrace();
}
}
}
}).start();
}
}大家也可以用自己的个人博客作为起点试一下,看下自己在哪个连通块里面。
加载全部内容