C++ STL容器
__JAN__ 人气:0各大容器的特点:
1.可以用下标访问的容器有(既可以插入也可以赋值):vector、deque、map;
特别要注意一下,vector和deque如果没有预先指定大小,是不能用下标法插入元素的!
2. 序列式容器才可以在容器初始化的时候制定大小,关联式容器不行;
3.注意,关联容器的迭代器不支持it+n操作,仅支持it++操作。
适配器的概念
适配器的意思就是将某些已经存在的东西进行限制或者组合变成一个新的东西,这个新的东西体现一些新的特性,但底层都是由一些已经存在的东西实现的。
STL中的容器
vector :矢量(并非数学意义上的) STL最简单的序列类型,也是一些适配器的默认底层类
deque:双端队列可从头尾出队入队
list:双向链表
forwardd_list:单向链表,功能少一些,不可反转。
queue:队列,一个适配器类(底层模板类默认deque),不允许随机访问和历遍;展示队列的接口
priority_queue:优先队列,一个适配器类(底层模板类默认vector),默认大根堆(最大的元素在最前面)。
stack:栈,一个适配器类(底层模板类默认vector),给底层类提供典型的栈接口。
特别的
array:并非STL容器,长度固定,但也能使用一些STL算法
容器基本都有以下几种功能,具体情况视容器而定
p,q,i,j表示迭代器
序列基本要求,拿vector举例,p , q , i , j 表示迭代器
vector <int> vec (n,t); //创建并初始化 vector <int> (n,t); //创建匿名对象并初始化 vector <int> vec (i,j); //创建并初始化为另一个容器[i,j)内容 vector <int> (i,j); //创建匿名对象并初始化为另一个容器[i,j)内容 vec.insert(p,t); //插入t到p的前面 vec.insert(p,n,t); //插入n个t到p的前面 vec.insert(p,i,j); //将区间[i,j)插入到p的前面(可以为自己的区间后者其他容器的区间) vec.erase(p); //删除p指向的元素 vec.erase(p,q); //删除[p,q)区间的元素 vec.clear(); //清空容器,等价于vec.erase(vec.begin(),vec.end());
一些可选要求,见名知义了,不解释。
.front(); .back(); .push_front(); .push_back(); .pop_front(); .pop_back(); [n] .at(n);
.at()和 [ ]很像,不过前者在越界是会引发一个异常,我们可以进行捕获
deque
用双端队列演示上面的一些
#include <iostream>
#include <deque>
#include <algorithm>
using namespace std;
void show(int & t)
{
cout << t << " ";
}
int main()
{
deque<int> a(10,5);
a.push_front(10);
a.push_back(20);
for_each(a.begin(),a.end(),show);
cout << endl;
a.pop_front();
a.pop_back();
for_each(a.begin(),a.end(),show);
a.push_back(999);
cout << endl << a.at(10) << " " << a[10];
try{
cout << endl << a.at(100);
}
catch (out_of_range){
cout << "越界访问";
}
return 0;
}运行结果

queue
一些queue的方法
priority_queue
可以用其进行堆排序
int main()
{
srand((unsigned)time(NULL));
priority_queue<int> pq;
for(int i=0;i<100;i++){
int x = rand() %1000+1;
pq.push(x);
}
for(int i=0;i<100;i++){
cout << pq.top() << " ";
if(i%10 == 0)
cout << endl;
pq.pop();
}
return 0;
}运行结果

时间复杂度O(nlogn),因为是基于树形结构,每次pop时间复杂度O(logn),进行n次。
一些方法
list
list的一些基本成员函数
void merge(list<T, Alloc> & X)
链表x与调用链表合并,在合并之前必须进行排序。合并后的链表存储在调用链表中,x变为空链表。线性时间复杂度
void remove(const T &val)
删除表中的所有val,线性时间复杂读。
void sort()
因为 list 不支持随机访问,不能使用 std::sort(),但是可以使用自带的 sotr,时间复杂度 O(nlogn)
void (iterator pos, list <T, Alloc> x)
将x链表插入到pos的前面,x变为空。固定时间复杂度。
void unique() 将连续的相同元素压缩为单个元素。线性时间复杂度
示例
#include <iostream>
#include <list>
#include <algorithm>
using namespace std;
void show(int & t)
{
cout << t << " ";
}
ostream & operator<<(ostream & os, list<int> & s)
{
for_each(s.begin(),s.end(),show);
return os;
}
int main()
{
list <int> one (5,2);
list <int> two (5,3);
list <int> three;
int num[5] = {1,6,3,5,2};
three.insert(three.begin(),num,num+5);
cout << "list one is " << one << endl;
cout << "list two is " << two << endl;
cout << "list three is(use insert) " << three << endl;
three.sort();
cout << "list three use sort " << three << endl;
three.merge(two);
cout << "list three use merge to list two \n" << "now list two is empty: ";
cout << "list two is " << two << endl;
cout << "now list three is " << three << endl;
three.splice(three.begin(),one);
cout << "three use splice to one \n" << "now list one is empty: ";
cout << "now list one is " << one << endl;
cout << "now list three is " << three << endl;
three.unique();
cout << "three use unique is " << three << endl;
three.sort();
cout << "list three use sort and unique: " << three << endl;
three.remove(3);
cout << "now use remove delete 3: " << three;
return 0;
}运行结果
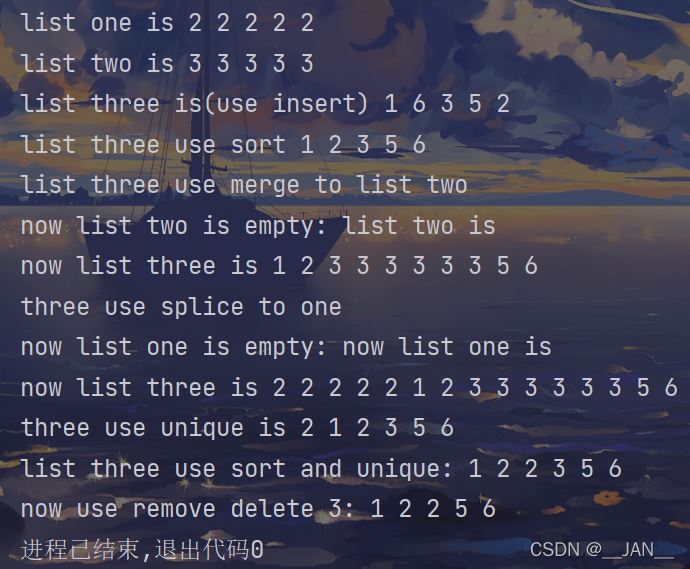
注意merge(),不是简单的拼接,是有顺序的合并。而spille()才是拼接(插入)。
forwarrd_list
一些方法
stack
一些方法
关联容器
关联容器是队容器概念的另一个改进,关联容器将数据和关键字(key)存放在一起,用关键字来快速的查找数据。
STL提供了四种关联容器,set, multiset, map, multimap。
set(关联集合)
可翻转,可排序,并且存储进去的时候自动排好序。关键字唯一即一个数据有且只有一个关键字并且与存储类型相同。
#include <iostream>
#include <algorithm>
#include <set>
#include <iterator>
using namespace std;
int main()
{
const int n =6;
string str[n] = {"hello", "world", "i am", "set use","C++","union"};
//构造函数接受两个迭代器表示区间,初始化为区间内的内容
set<string> A(str,str+6);
ostream_iterator<string,char> out(cout,"\n");
copy(A.begin(),A.end(),out);
return 0;
}运行结果
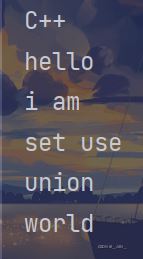
可以看见其已经自动排序
一些set的类方法
lower_bound()——接受一个关键字参数,返回一个迭代器,该迭代器指向第一个不小于关键字成员的参数(可能以关键字对应数开头,也可能不是)。
upper_bound()——同上,该迭代器指向第一个大于关键词的成员(类似超尾)。
演示
#include <iostream>
#include <algorithm>
#include <set>
#include <iterator>
using namespace std;
int main()
{
const int n =6;
string str[n] = {"hello", "world", "i am", "set use","C++","union"};
set<string> A(str,str+6);
ostream_iterator<string,char> out(cout,"\n");
//find string from b to r
copy(A.lower_bound("b"),A.upper_bound("s"),out);
return 0;
}运行结果

因为upper_bound()返回的是类似超尾迭代器的迭代器,所以不包括以‘s’开头的字符串
因为底层以树形结构实现得以快速查找,所以用户不能指定插入位置。并且插入后自动排序。
multimap(多关联图)
可反转,自动排序,关键字可与数据类型不同,一个关键字可与多个数据关联。
//<const key,type_name> mutimap <int,string> mp;
为了将信息结合在一起,数据与关键字用一个pair存储,所以插入等操作要插入pair
一些方法
count()——接受一个关键字参数,返回该关键字所对应得数据个数。
lower_bound(), upper_bound(),同set。
equal_range()——接受一个关键字参数,返回两个迭代器,表示与该关键字所对应的区间,并且用一个二元组封装。
演示
#include <iostream>
#include <iterator>
#include <map>
using namespace std;
typedef pair<int,string> Pair;
int main()
{
Pair p[6]={{6,"啤酒"},
{10,"炒饭"},
{80,"烤猪头"},
{10,"冷面"},
{5,"早餐"},
{80,"给你一锤子"}};
multimap<int,string> mulmap;
// no operator <
cout << "现在图中存储的关键字和数据是:" << endl;
multimap<int,string> ::iterator i;
for(int i =0;i<6;i++){
mulmap.insert(p[i]);
}
for(auto i=mulmap.begin(); i!=mulmap.end(); i++){
cout << i->first << " " << i->second << endl;
}
cout << "使用count函数找到价格为80的菜品个数为:" << mulmap.count(80) << endl;
pair<multimap<int,string>::iterator,multimap<int,string>::iterator> temp;
cout << "使用equal_range函数找到价格为80的菜品" << endl;
temp = mulmap.equal_range(80);
for(auto i = temp.first;i!=temp.second;i++){
cout << i->second;
}
return 0;
}运行结果

map(图)和multiset(多关联集合)的使用与上面类似。
无序关联容器
可以感觉到,关联容器底层基于某种数据结构,像树,能使其快速的进项操作。但又是因为树的原因,使得每个节点必须有着严格规定。
还有无序关联容器,底层数据结构基于哈希表(每个元素对应其映射,就像关键字一样)。
有四种:
- unordered_set
- unordered_multiset
- unordered_map
- unordered_multimap
和关联序列的方大同小异,在应用场景上会有些许不同。
加载全部内容