python爬取酷狗音乐榜单
Ding Jiaxiong 人气:0网页情况
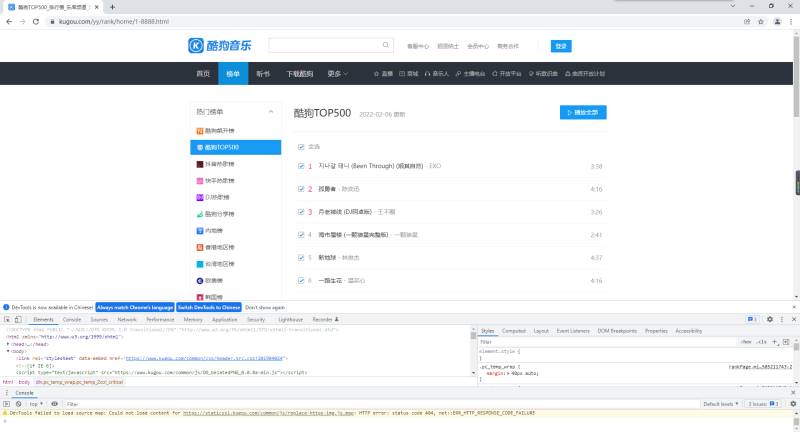
爬取数据包含
歌曲排名、歌手、歌曲名、歌曲时长
python 代码
import requests #请求网页获取网页数据
from bs4 import BeautifulSoup #解析网页数据
import time #时间库
#user-Agent,伪装成浏览器,便于爬虫的稳定性
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
}
def get_info(url):
web_data = requests.get(url,headers= headers)
soup = BeautifulSoup(web_data.text,'lxml')
ranks = soup.select('span.pc_temp_num')
titles = soup.select('div.pc_temp_songlist > ul > li > a')
times = soup.select('span.pc_temp_tips_r > span')
for rank,title,time in zip(ranks,titles,times):
data = {
"rank":rank.get_text().strip(),
"singer":title.get_text().replace("\n","").replace("\t","").split('-')[1],
"song":title.get_text().replace("\n","").replace("\t","").split('-')[0],
"time":time.get_text().strip()
}
print(data)
if __name__ == '__main__':
urls = ["https://www.kugou.com/yy/rank/home/{}-8888.html".format(str(i)) for i in range(1,24)]
for url in urls:
get_info(url)
time.sleep(1)
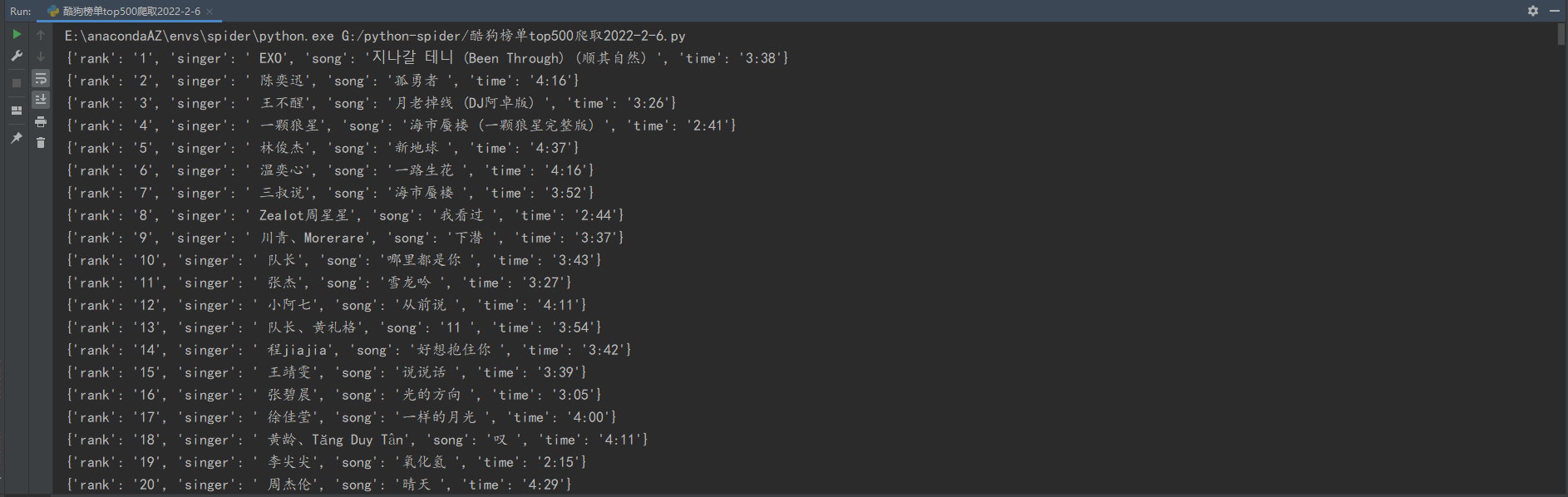
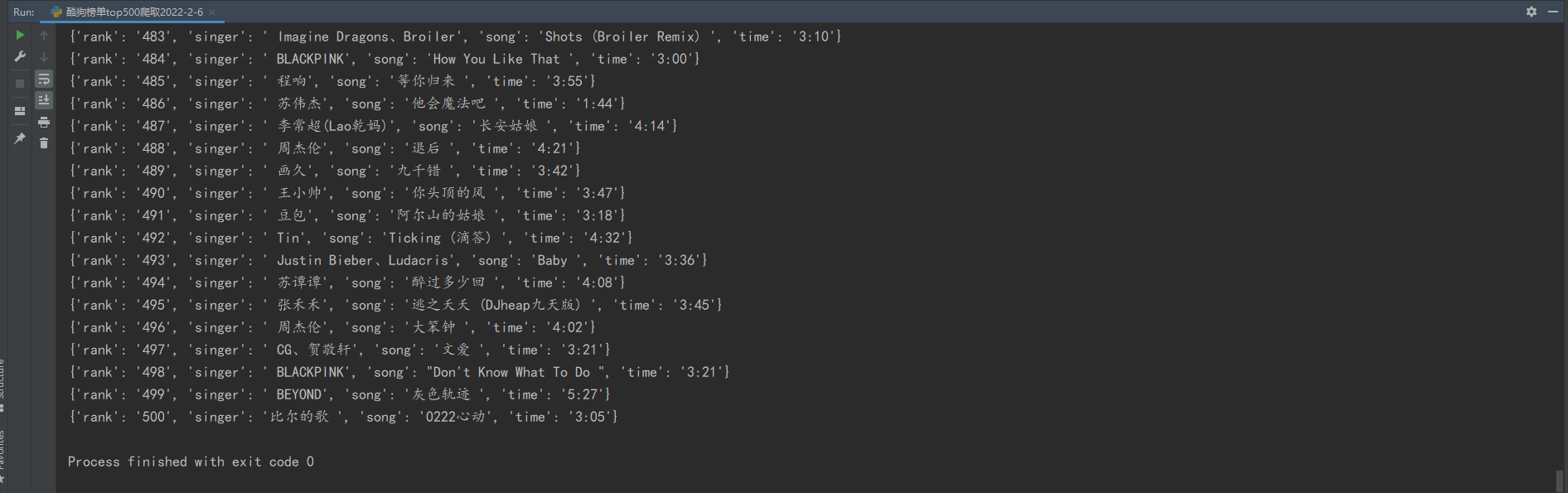
运行效果
总结
加载全部内容