C++继承忽视的点
^jhao^ 人气:0前言
继承是使代码复用的一种重要的手段,我们在C语言时期写的swap函数逻辑,通常会单独写出来再给其他函数复用,这个继承可以理解成是类级别的一个复用,它允许我们在原有类的基础上进行扩展,增加新的功能。
一、什么是继承
举个例子,当我们使用一个结构体去描述一个学生的信息时,我们可以用到以下的这样一个组织方式:
struct Student
{
char sex[20];//性别
int age;//年龄
char stu_id;//学号
//.....
};
当我们要描述一名老师的时候我们这个时候可能就是更改学生信息当中的部分的信息,例如上面的性别和年龄是可以通用的,而学号只需更改成工号即可。那么我们应该怎么去达到复用的逻辑呢?
:我们可以写一个struct People,让struct Student和struct Teacher去复用它。
struct People
{
char sex[20];//性别
int age;//年龄
};
struct Student
{
struct People p;
char stu_id;//学号
//.....
};
struct Teacher
{
struct People p;
char work_id;//工号
//.....
};
这样子我们用之前的C语言的知识就可以完成一个简单的复用,这样子做会有几个不好的地方:
- 对于People内部的访问会比起访问他自己内部定义的变量麻烦一点(就是如定义了Teacher t;要访问age需要 t.p.age)。
- 若基类(父类)想要对于派生类(子类)有所隐藏,即并不想让所有的成员函数/成员变量都给子类所继承的时候,我们用这种方式很难做到。
基于以上的问题,C++给出了一套继承逻辑。
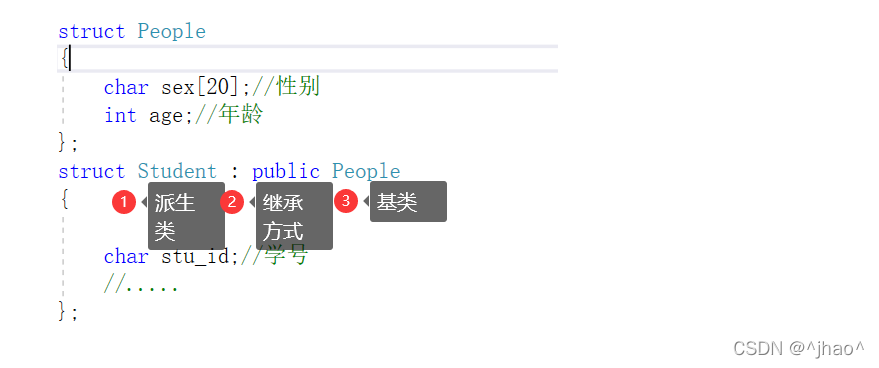
上述第一个问题就解决了,我们可以直接在People t,直接访问基类的成员,第二个问题,对于一些我们想要隐藏的成员函数/成员变量(即不让子类可见),我们可以通过继承方式来控制,在此之前先铺垫一个知识点。
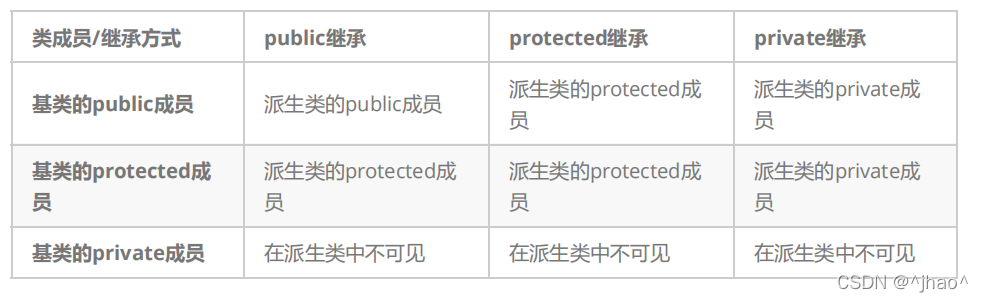
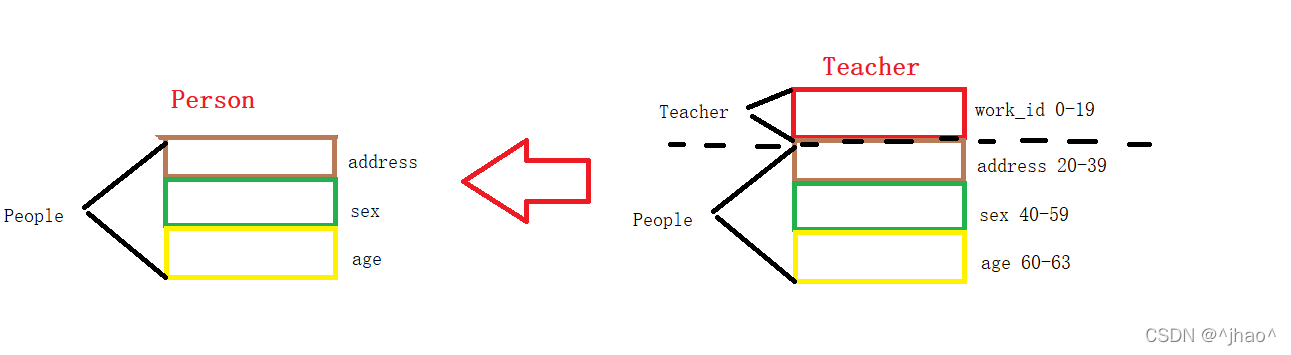
上图若是开过c++这门课的同学肯定都有见过,其中的最左列是表明基类的被继承的成员是什么类型的,第一行则是以哪种形式继承。
基类的其他成员在子类的访问方式 == Min(成员在基类的访问限定符,继承方式),public > protected > private 。
其中protected成员变量我们在继承这块见得会比较多,下面我们比较一下public/protected/private的在继承当中的作用。
- 若基类的成员当中为public,则说明他支持类内,类外部都可以去访问他,而这时候我们常用public继承,因为基类都已经开放了这个成员变量,派生类用其他两种方式继承都会让他在派生类的类外部无法访问,所以实际上public继承是最常用的。
- 若基类的成员当中是protected类型,表明基类允许子类当中可以使用这个成员,但是不希望类外部使用,protected的访问限定符只是对类外部上锁,而类内是可以随意使用的,这样实际上也是封装性的一种体现。
- 若基类的成员是private类型,表明不希望子类和外部访问,在子类当中不可见,不可见即子类当中无法访问该成员。但是他是否存在于派生类当中?是存在的。
实践是检验真知的唯一标准,下面我们试试是否private的成员在子类真的存在:
class People
{
public:
char address;//住址
protected:
double sex;//性别
private:
int age;//年龄
};
class Student : protected People
{
char stu_id[20];//学号
//.....
};
struct Teacher :public People
{
double work_id;//工号
//.....
};
int main()
{
Teacher t;
cout << sizeof(t) << endl;//对t变量的大小测试
printf("%p,%p", &t.address,&t.work_id);
return 0;
}
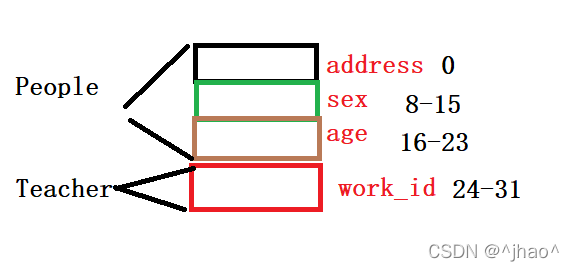
验证结果为32,即下图所示,我们可以得知People的元素是在Teacher之上的。
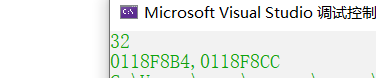
示意图:
倘若强行访问,则会报错。到此问题2的答案也清晰了。
不推荐protected继承的原因:
class People
{
public:
char address;//住址
protected:
double sex;//性别
private:
int age;//年龄
};
struct Student : protected People
{
char stu_id[20];//学号
//.....
};
int main()
{
Student s1;
People p = s1;//error
return 0;
}
上面这个protected继承后子类对象赋值给基类报错!

其实是因为父类的public对象address在以protected方式继承时相当于在类外部不可访问,当赋值给People对象时,权限被放大,即若支持赋值,子类address是不对外开放的,而父类却把成员变量公开了!
解决方案:使用public继承!
二、基类与派生类的赋值转换
2.1天然支持的理解
这个点是一个十分重要的点,在学习java语言的时候,经常听到上转型,其实也就是c++当中将子类的对象赋值给父类,即People t = student s;类似这种,这个过程是天然支持的,接下来叙述一下天然支持的含义。
预备知识:
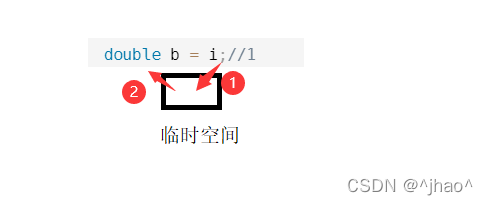
int i = 0; double b = i;//1 double& b =i ;//2 error const double& b = i ;//3
从初识c语言的时候,我们就发现上面代码的第一条是没有问题的,这是因为相近类型在精度低给精度高的时候是不会出现问题的。这是因为编译器会在此期间生成一块临时空间(临时空间具有常性),用i生成一个double类型的i再赋值给b。
在上面的2代码的时候为什么会出错呢?原因很简单,临时空间具有常性,临时空间是放到静态区当中的,不可修改,当用double&时相当于会对权限进行放大(即b可能会更改i的内容),所以我们加入const属性的时候代码3也就能够跑过了。
上面的子类给父类为什么就是天然支持的呢?
int main()
{
Teacher t;
People& p = t;//true
People* p2 = &t;//true
People p3 = t;//true
return 0;
}
上面的程序正常运行,父类引用子类对象完全没有问题!所以我们才说这是天然支持的,不像上面例子是通过转换而来的。
这种派生类对象赋值给基类的对象/基类的指针/基类的引用,称之为切片,这种说法是十分贴切的。通过切去子类的自己定义的部分在给到基类。
这里会有一些值得注意的点:
基类的对象不能赋值给派生类对象!!
基类的指针是可以通过强制类型转换来赋值给派生类的指针,但是基类的指针必须原先是指向派生类对象才是安全的。倘若基类是多态类型,可以用RTTI当中的dynamic cast来进行识别后进行安全转换。(后序博客会将,这里简单说明就是使用dynamic cast,他会判断指针指向的是不是派生类对象,如果是就转换成功,不是就会返回null)
对于上面第二点做一个解释,就是如果People * pp指向的是一个People的对象,那么当他给到派生类的指针的时候,派生类指针是有可能访问到未初始化的那部分。因为站在派生类指针的角度,他并不知道自己的成员是没有被定义的,倘若它使用了未初始化数据,就会产生越界报错!!
相反,如果原先的pp指针指向的是派生类对象(天然支持的),那么当我们pp给到派生类的时候,对于派生类的而言,它的数据都是初始化好的,所以这个时候是没有问题的。
三、继承当中的作用域
在继承体系中基类和派生类都有独立的作用域!!
代码如下:
class People
{
public:
char address[20] = "chang an";//住址
void func(int i)
{
cout << "People func\n";
}
protected:
char sex[20] = "nan";//性别
private:
int age = 19;//年龄
};
struct Student : public People
{
char stu_id[20] = "1010";//学号
//.....
void func()
{
cout << "Student func\n";
}
};
int main()
{
People p;
Student s;
s.func(); //true
s.func(1);//err
return 0;
}
从上面的例子可以看出,倘若基类和子类都在同一个作用域,那么func的有参和无参是构成重载的,但是编译器这里报错,说明重载的一个重要条件不满足,即函数不在同一作用域当中。
这种子类成员将父类的成员屏蔽的情况,叫做隐藏,也叫重定义,倘若需要调用父类的函数需要在函数前显示调用(指名类域)即可。
注意:
- 继承体系当中不建议定义同名的成员,因为会引发误解。
- 但是在派生类的默认成员函数当中会用到这种语法,所以这种语法也是必不可少的!!
- 成员函数和成员变量都如此,基类定义相同名字的都会对父类进行隐藏,调用都要显示调用。
四、派生类的默认构造成员函数
1. 派生类的构造函数必须调用基类的构造函数初始化基类的那一部分成员。如果基类没有默认的构造函数,则必须在派生类构造函数的初始化列表阶段显示调用。
2. 派生类的拷贝构造函数必须调用基类的拷贝构造完成基类的拷贝初始化。
3. 派生类的operator=必须要调用基类的operator=完成基类的复制。
4. 派生类的析构函数会在被调用完成后自动调用基类的析构函数清理基类成员。因为这样才能保证派生类对象先清理派生类成员再清理基类成员的顺序。
5. 派生类对象初始化先调用基类构造再调派生类构造。
6. 派生类对象析构清理先调用派生类析构再调基类的析构。
总结前面的6个规则,个人的结论:
- 构造函数,拷贝构造,operator=三种情况,都要调用父类对应的构造函数/拷贝构造/operator=进行对父类的成员变量的初始化,并且倘若父类没有默认的构造函数的时候(比如父类写了带参的构造函数),我们就要显式调用(Person(参数…),Person::operator=(参数…))
- 析构函数只需要清理子类定义的资源,由于在构造函数当中我们是先对父类的成员先进行构造,后对子类的成员进行构造。由先构造后析构的顺序,所以我们是在析构函数当中析构子类的资源,析构函数调用完后编译器自动帮我们调用父类的析构函数。
在派生类当中基类为一个自定义类型,会自动调用父类的构造函数进行初始化。在拷贝构造当中,由于子类把父类的部分当做自定义类型,倘若没有显示调用拷贝构造,就会调用到构造函数上面对父类的部分进行构造。
在子类当中直接对父类单独的成员初始化是错误的,一定要把父类当做一个整体进行初始化!
4.0什么时候需要写6个默认成员函数
抛出结论:
1. 若父类没有默认构造函数/默认拷贝构造函数或者有需要对成员的初始化(可以在声明处给缺省值),或者编译器提供的浅拷贝行为不能满足我们的需求。
2. 当我们成员变量中采用T*,自己维护在堆上开的空间时,我们往往需要对除取地址重载外的其余默认成员函数进行编写。因为我们没有选择容器,自己动手维护堆上的资源时,若采用编译器默认生成的值拷贝的方式,分分钟出错!
4.1构造函数
#include<iostream>
using namespace std;
class People
{
public:
People()
{
cout << "People()\n";
}
//p1(p)
People(const People& p)
{
cout << "People(const People& p)" << endl;
}
// p1 = p
People& operator=(const People& p)
{
cout << "People& operator=(const People& p)" << endl;
return *this;
}
private:
char name[20];
char address[20];
char tele[20];
};
class Student :public People
{
public:
//无写构造
private:
int id;
};
int main()
{
Student t;
return 0;
}
在没有写派生类的构造函数时,派生类会在编译器生成的默认构造函数当中在初始化列表处调用父类的构造函数对父类的资源进行初始化。
当我们写了子类的构造函数,但是没有显示调用父类的构造函数,编译器依旧会在初始化列表处帮我们调用父类的构造函数对父类的资源进行初始化。

C++规定了派生类要先对父类资源进行初始化,所以不管我们有没有显示调用父类的构造函数,编译器都会帮我们调用。下面展示一下如何显示调用
Student()
:People()
{
cout << "Student()" << endl;
}
倘若父类没有写默认的构造函数,这个时候只能用显示调用的方法对父类的资源初始化了。
调用方法看起来有点奇怪,用起来有点像创建匿名对象,但是便于理解,我们可以把他理解成子类当中将父类看做自定义类型,所以会去默认调用它的构造函数,而我们没有显示写出父类的对象,所以初始化父类的形式用的是类名+(参数...)
4.2拷贝构造
1.当我们没有编写拷贝构造函数的时候,我们发现编译器帮我们默认生成的拷贝构造会自动调用父类的拷贝构造。
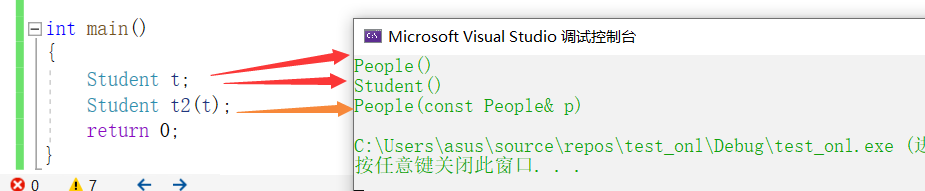
那么我们是否跟构造函数一样只拷贝子类的资源即可,编译器是否会帮我们也在初始化列表处对父类资源进行拷贝?
不会
看下面这张图,我们发现拷贝构造当中调用了父类的构造函数
有的同学就会有疑惑了,实际上拷贝构造也是构造,在初始化列表处,对于子类而言,父类相当于一个自定义类型对象,子类会调用父类的构造函数对父类的资源进行初始化。
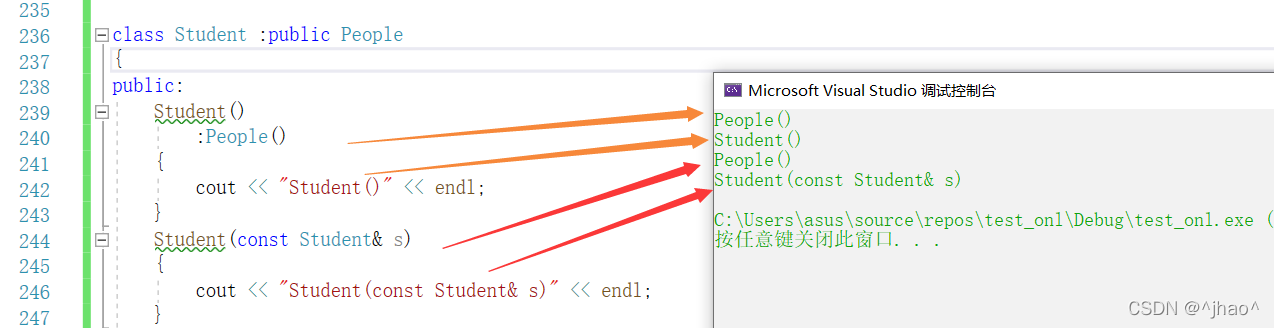
解决方法:显示调用父类的拷贝构造即可,所以拷贝构造这里我们一定要要写就一定要显示调用父类的拷贝构造。
Student(const Student& s)
:People(s)
{
cout << "Student(const Student& s)" << endl;
}
4.3赋值重载
老样子,先看看编译器生成的默认的operator=是怎样的。
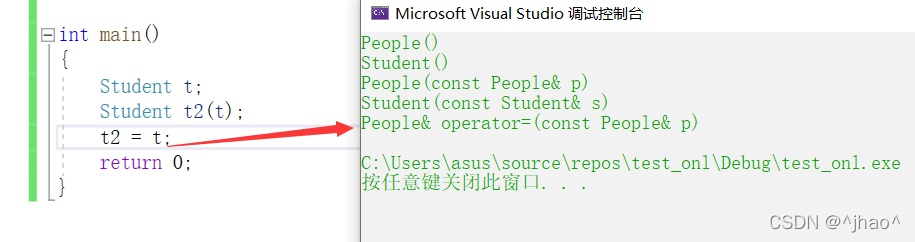
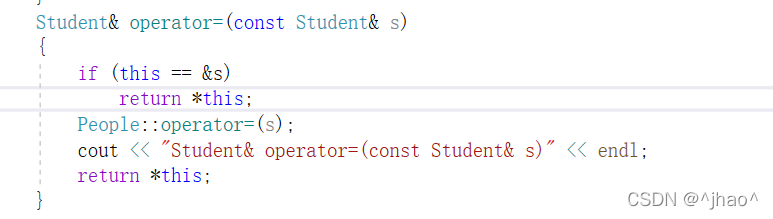
很显然,编译器会自动调用父类的operator=对父类的部分进行赋值,赋值重载与拷贝构造一样,需要我们显示调用父类的赋值重载,否则虽然不会报错,但是不满足我们所需要的行为。
所以我们在函数体内调用父类oeperator=即可:
五、菱形继承和菱形虚拟继承
单/多继承的定义:
单继承:一种继承机制。其中每个子类只能继承单一的超类。
多继承:多继承可以看作是单继承的扩展。所谓多继承是指派生类具有多个基类,派生类与每个基类之间的关系仍可看作是一个单继承。
多继承本身并没有问题,但是它的扩展形成菱形继承出现了问题,让我们学习的过程中需要学习更加复杂的解决方案。
5.1菱形继承
以下面这张图为例。
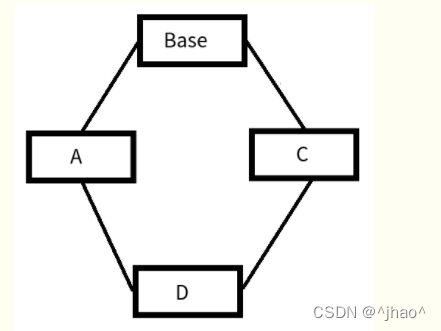
struct Base {
int base;
};
struct A :public Base
{
int a;
};
struct C :public Base
{
int c;
};
struct D :public A ,public C
{
int d;
};
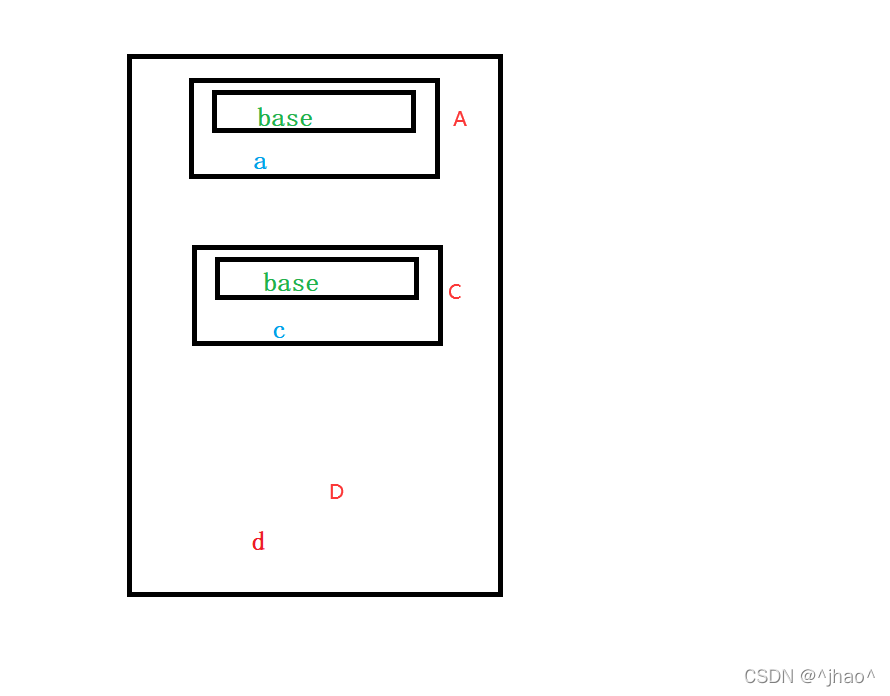
在没有虚继承前,对象模型如下图,可以看出base在D有出现了两份,也就是在D所创建的对象当中都会出现二义性和数据冗余的问题!
解决方案
虚继承,在腰部的类继承时添加virtual关键字。
struct Base {
int base;
};
struct A :virtual public Base
{
int a;
};
struct C :virtual public Base
{
int c;
};
struct D :public A ,public C
{
int d;
};
int main()
{
D d;
d.c = 1;
d.d = 2;
d.a = 3;
return 0;
}
测试平台:vs2013/32位
虚继承后的内存对象成员模型,其中每个腰部虚继承的A,C的对象都多了一个指针,由于我们是小端机,所以对应过去我们能看到指向的空间当中对应8字节,表中头4字节00 00 00 00与多态有关,下面的则是偏移量,由于虚继承后只有一份A对象的成员变量,并且表结构需要8字节的空间,所以A,C对象当中存放的是虚基表指针,指向的是虚基表,虚基表一般是放在代码段 当中的。
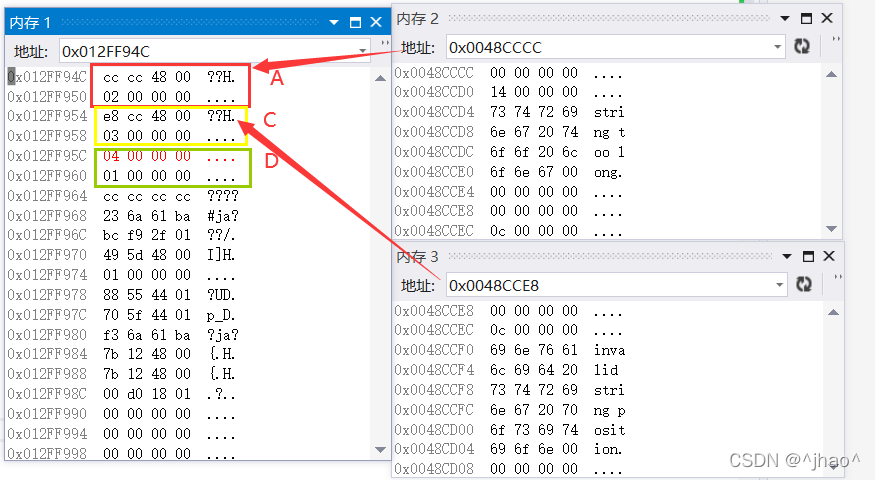
为什么C,A需要去找属于自己的Base?
基类与派生类的赋值转换时,需要进行切片,需要将A,C当中的base变量才能赋值给b。
int main()
{
Base b = A();
Base b2 = C();
return 0;
}
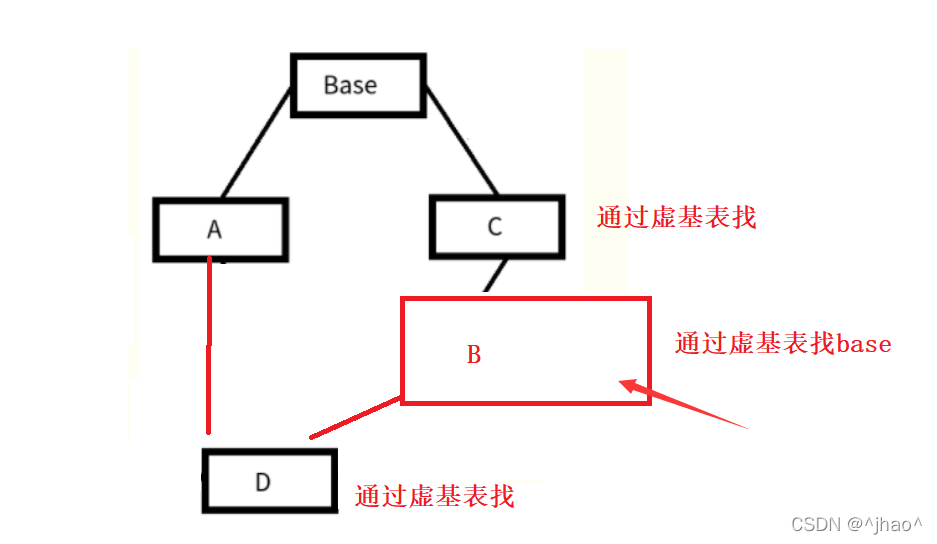
上述图中B是否虚继承都可以,只要A,C虚继承,D中都不会出现二义性了。
六、继承的总结
在继承这块实际上是c++语法复杂的一处体现了,有了多继承,就有了菱形继承,相对应他的解决方案来了,但是我们可以发现这套解决方案让他的底层实现必定变得复杂了起来,所以正常使用的时候我们并不推荐去折腾菱形继承,在java等语言都把多继承这一块砍掉了,使用多继承的同时就要考虑复杂度和性能上的问题。
继承和组合
继承是一种复用的方式,但不是唯一方式!
- public继承是一种is-a的关系,每一个派生类都是一个基类对象。
- 组合是一种has-a的关系,假设B组合了A,则每个B对象都有一个A对象。
- 继承方式的复用常称之为白箱复用,在继承方式中,基类的内部细节对子类可见,这一定程度上破坏了基类的封装,伴随着基类的改变,对派生类的改变很大。并且两者依赖关系强,耦合度大。
- 对象组合式继承之外的复用选择,对象组合要求被组合对象提供良好的接口定义。这种复用称之为黑箱复用,对象的内部实现细节是不可见的。耦合度低。
实际工程中能用继承和组合就用组合,组合的耦合度低,代码的维护性好,但是继承在有些关系就适合用继承就用继承,并且要实现多态就一定要用继承。
总结
继承作为c++的一块难点,本篇博客不免有些错误,欢迎各位大佬指出批评!
加载全部内容