MySQL中的count(*) 与 count(1)
码农小宋 人气:0先说结论:这两个性能差别不大。
1.实践
我准备了一张有 100W 条数据的表,表结构如下:
CREATE TABLE `user` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `username` varchar(255) DEFAULT NULL, `address` varchar(255) DEFAULT NULL, `password` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
可以看到,有一个主键索引。我们来用两种方式统计一下表中的记录数,如下:
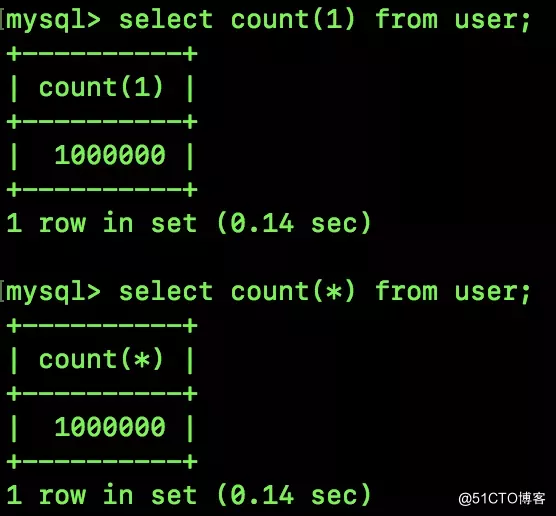
可以看到,两条 SQL 的执行效率其实差不多,都是 0.14s。
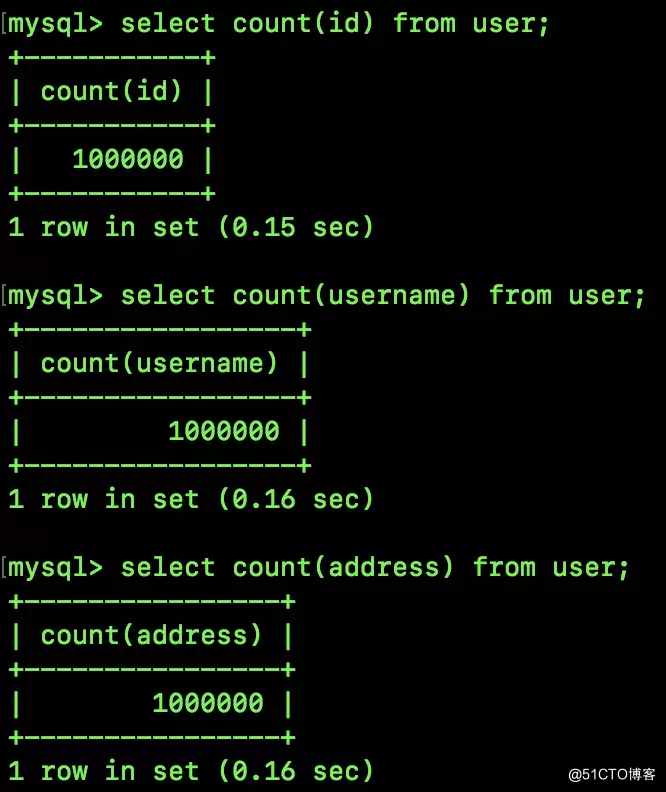
再来看另外两个统计:
id 是主键,username 以及 address 则是普通字段。可以看出,用 id 来统计,也有一丢丢优势。松哥这里因为测试数据样板比较小,所以效果不明显,小伙伴们可以加大测试数据量,那么这种差异会更加明显。
那么到底是什么原因造成的这种差异,接下来我们就来简单分析一下。
2. explain 分析
我们先用 explain 来看下这几个 SQL 不同的执行计划:
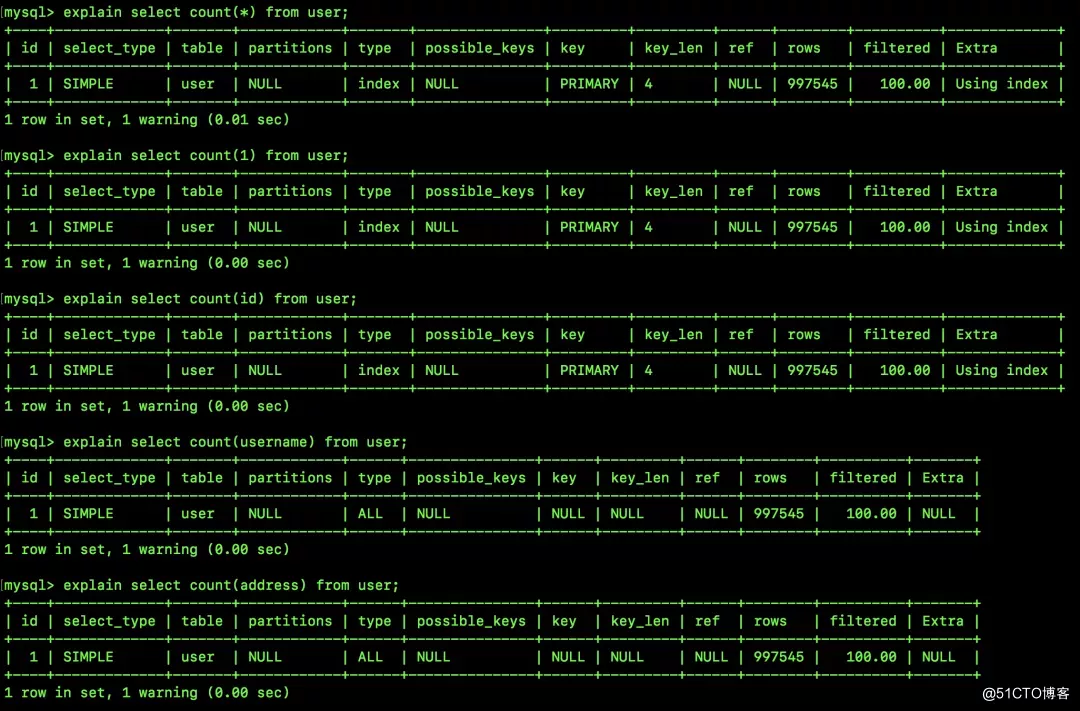
可以看到,前三个统计方式的执行计划是一样的,后面两个是一样的。我这里和大家比较下 explain 中的不同项:
- type:前三个的 type 值为 index,表示全索引扫描,就是把整个索引过一遍就行(注意是索引不是整个表);后两个的 type 值为 all,表示全表扫描,即不会使用索引。
- key:这个表示 MySQL 决定采用哪个索引来优化对该表的访问,PRIMARY 表示利用主键索引,NULL 表示不用索引。
- key_len:这个表示 MySQL 使用的键长度,因为我们的主键类型是 INT 且非空,所以值为 4。
- Extra:这个中的 Using index 表示优化器只需要通过访问索引就可以获取到需要的数据(不需要回表)。
通过 explain 我们其实也能大概看出来前三种统计方式的执行效率是要高一些的(因为用到了索引),而后面两种的统计效率相对来说要低一些的(没用索引,需要全表扫描)。仅有上面的分析还不够,我们再来从原理角度来分析一下。
3. 原理分析
3.1 主键索引与普通索引
在开始原理分析以前,我想先带领大家看一下 B+ 树,这对于我们理解接下来的内容有重要作用。大家都知道,InnoDB 中索引的存储结构都是 B+ 树(至于什么是 B+ 树,和 B 树有什么区别,这个本文就不讨论了,这两个单独都能整出来一篇文章),主键索引和普通索引的存储又有所不同,
如下图表示主键索引:
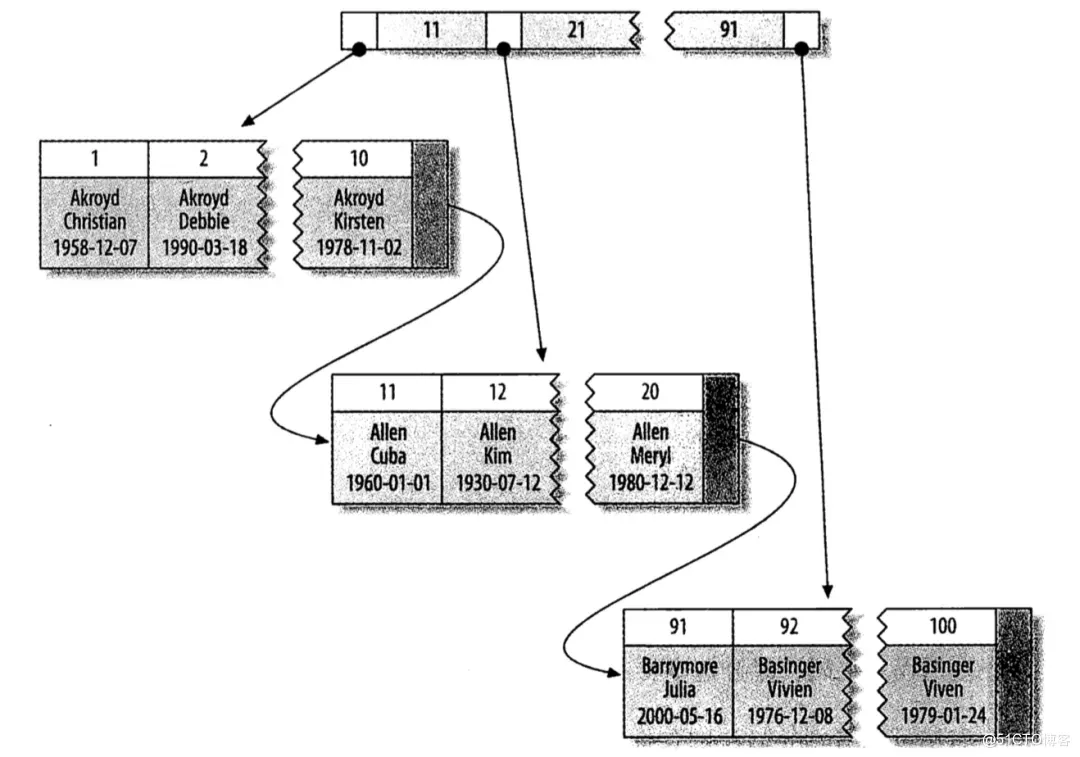
可以看到,在主键索引中,叶子结点保存了每一行的数据。而在普通索引中,叶子结点保存的是主键值,当我们使用普通索引去搜索数据的时候,先在叶子结点中找到主键,再拿着主键去主键索引中查找数据,相当于做了两次查找,这也就是我们平常所说的回表操作。
3.2 原理分析
不知道小伙伴们有没有注意过,我们学习 MySQL 的时候,count 函数是归在聚合函数那一类的,就是 avg、sum 等,count 函数和这些归在一起,说明它也是一个聚合函数。既然是聚合函数,那么就需要对返回的结果集进行一行行的判断,这里就涉及到一个问题,返回的结果是啥?我们分别来看:对于 select count(1) from user; 这个查询来说,InnoDB 引擎会去找到一个最小的索引树去遍历(不一定是主键索引),但是不会读取数据,而是读到一个叶子节点,就返回 1,最后将结果累加。对于 select count(id) from user; 这个查询来说,InnoDB 引擎会遍历整个主键索引,然后读取 id 并返回,不过因为 id 是主键,就在 B+ 树的叶子节点上,所以这个过程不会涉及到随机 IO(并不需要回表等操作去数据页拿数据),性能也是 OK 的。对于select count(username) from user; 这个查询来说,InnoDB 引擎会遍历整张表做全表扫描,读取每一行的 username 字段并返回,如果 username 在定义时候设置了 not null,那么直接统计 username 的个数;如果 username 在定义的时候没有设置 not null,那么就先判断一下 username 是否为空,然后再统计。最后再来说说 select count(*) from user; ,这个 SQL 的特殊之处在于它被 MySQL 优化过,当 MySQL 看到 count(*) 就知道你是想统计总记录数,就会去找到一个最小的索引树去遍历,然后统计记录数。因为主键索引(聚集索引)的叶子节点是数据,而普通索引的叶子节点则是主键值,所以普通索引的索引树要小一些。然而在上文的案例中,我们只有主键索引,所以最终使用的就是主键索引。现在,如果我修改上面的表,为 username 字段也添加索引,然后我们再来看 explain select count(*) from user; 的执行计划:

可以看到,此时使用的索引就是 username 索引了,和我们前面的分析结果是一致的。从上面的描述中我们就可以看出,第一个查询性能最高,第二个次之(因为需要读取 id 并返回),第三个最差(因为需要全表扫描),第四个的查询性能则接近第一个。
4. MyISAM 呢?
可能有小伙伴知道,MyISAM 引擎中的 select count(*) from user; 操作执行起来是非常快的,那是因为 MyISAM 把表中的行数直接存在磁盘中了,需要的时候直接读取出来就行了,所以非常快。MyISAM 引擎之所以这样做,主要是因为它是不支持事务的,所以它的统计实际上就非常容易,添加一行记录一行就行了。而我们常用的 InnoDB 却不能这样做!为啥?因为 InnoDB 支持事务!为了支持事务,InnoDB 引入了 MVCC 多版本并发控制,所以在数据读取的时候可能会有脏读、幻读以及不可重复读等问题。所以,InnoDB 需要将每一行数据拿出来,判断该行数据对当前会话是否可见,如果可见,就统计该行数据,否则不予统计。
加载全部内容