Java Redis
小王曾是少年 人气:0
实际上它确实也很快 : ),但Redis底层却是单线程的!有同学可能就要有疑问了,为什么单线程的Redis却能够快到飞起?
别急,我尽量用通俗易懂的语言来给各位说道说道~~
Redis是单线程,主要是指Redis的网络IO和读写是由一个线程来完成的,但Redis的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。这不是本文讨论的重点,有个印象即可
Redis为什么用单线程?
多线程的开销
通常情况下,在采用多线程后,如果没有良好的系统设计,其实是右图所展示的那样(注意纵坐标)。刚开始增加线程数时,系统吞吐率会增加,再进一步增加线程时,系统吞吐率就增长迟缓了,甚至还会出现下降的情况。
关键瓶颈在于: 系统中通常会存在会被多线程同时访问的共享资源,为了保证共享资源的正确性,就需要有额外的机制保证线程安全性,例如加锁,这会带来额外的开销。
比如拿最常用的List类型来举例吧,假设Redis采用多线程设计,有两个线程A和B分别对List做LPUSH和LPUSH操作,为了使得每次执行都是相同的结果,即【B线程取出A线程放入的数据】就需要让这两个过程串行执行。这就是多线程编程模式面临的共享资源的并发访问控制问题。
并发访问控制一直是多线程开发中的一个难点问题:如果只是简单地采用一个互斥锁,就会出现即使增加了线程,大部分线程也在等待获取互斥锁,并行变串行,系统吞吐率并没有随着线程的增加而增加。
同时加入并发访问控制后也会降低系统代码的可读性和可维护性,所以Redis干脆直接采用了单线程模式。
Redis使用单线程为什么还这么快?
之所以使用单线程是Redis设计者多方面衡量的结果。
- Redis的大部分操作在内存上完成
- 采用了高效的数据结构,例如哈希表和跳表
- 采用了多路复用机制,使其在网络IO操作中能并发处理大量的客户端请求,实现高吞吐率
既然Redis使用单线程进行IO,如果线程被阻塞了就无法进行多路复用了,所以不难想象,Redis肯定还针对网络和IO操作的潜在阻塞点进行了设计。
网络与IO操作的潜在阻塞点
在网络通信里,服务器为了处理一个Get请求,需要监听客户端请求(bind/listen),和客户端建立连接(accept),从socket中读取请求(recv),解析客户端发送请求(parse),最后给客户端返回结果(send)。
最基本的一种单线程实现是依次执行上面的操作。

上面标红的accept和recv操作都是潜在的阻塞点:
- 当Redis监听到有连接请求,但却一直不能成功建立起连接时,就会阻塞在
accept()函数这里,其他客户端此时也无法和Redis建立连接 - 当Redis通过
recv()从一个客户端读取数据时,如果数据一直没有到达,也会一直阻塞
基于多路复用的高性能IO模型
为了解决IO中的阻塞问题,Redis采用了Linux的IO多路复用机制,该机制允许内核中,同时存在多个监听套接字和已连接套接字(select/epoll)。
内核会一直监听这些套接字上的连接或数据请求。一旦有请求到达,就会交给Redis处理,这就实现了一个Redis线程处理多个IO流的效果。
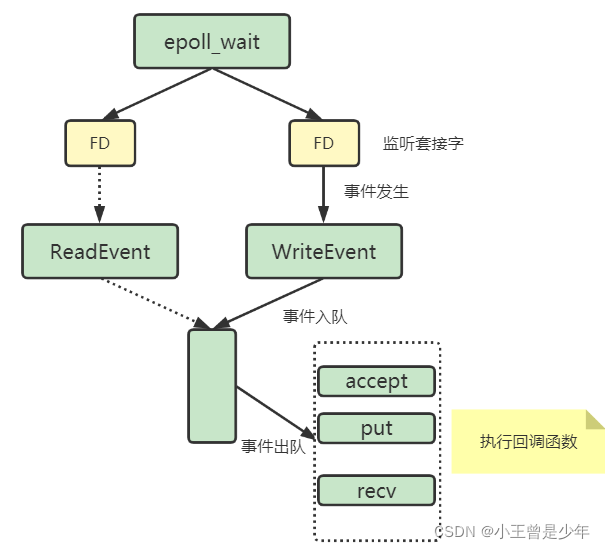
此时,Redis线程就不会阻塞在某一个特定的客户端请求处理上,所以它可以同时和多个客户端连接并处理请求。
回调机制
select/epoll一旦监测到FD上有请求到达时,就会触发相应的事件被放进一个队列里,Redis线程对该事件队列不断进行处理,所以就实现了基于事件的回调。
例如,Redis会对Accept和Read事件注册accept和get回调函数。当Linux内核监听到有连接请求或读数据请求时,就会触发Accept事件和Read事件,此时,内核就会回调Redis相应的accept和get函数进行处理。
Redis的性能瓶颈点
经过上面的分析,虽然通过多路复用机制可以同时监听多个客户端的请求,但Redis仍然有一些性能瓶颈点,这也是我们平时编程需要极力避免的情况。
1. 耗时操作
任意一个请求在Redis中一旦耗时较久,都会影响整个server的性能。后面的请求都要等前面这个耗时请求处理完成,自己才能被处理到。
这一点需要我们在设计业务场景时去规避;Redis的lazy-free机制也把释放内存的耗时操作放在了异步线程中去执行了。
2. 高并发场景
并发量非常大时,单线程读写客户端IO数据存在性能瓶颈,虽然采用IO多路复用机制,但还是只能单线程依次读取客户端的数据,无法利用到CPU多核。
Redis在6.0可以利用CPU多核多线程读写客户端数据,但只是针对客户端的读写是并行的,每个命令的真正操作还是单线程。
其他Redis相关的有趣问题
借此机会也提几个和redis相关的有意思的问题。

- 为什么要用Redis,直接访问内存不好吗?
这一条其实并没有很明确的界定,对于一些不经常变动的数据,可以直接放到内存里,不一定要放到Redis里,可以放到内存里。一致性问题:如果一个数据被修改了,数据在本地内存里的话,可能只有一台服务器上的数据被修改了。如果用Redis里面的话,我们访问Redis服务器,可以解决一致性问题。
- 数据太多内存放不下怎么办?比如我要缓存100G的数据,怎么办?
这里也要打一个广告Tair是淘宝开源的分布式KV缓存系统,它从Redis继承了丰富的操作,理论上总数据量无限制,针对可用性、可扩展性、可靠性也进行了升级,感兴趣的小伙伴们可以了解一下~
加载全部内容