pandas apply+lambda
神芷迦蓝寺 人气:0apply(func [, args [, kwargs ]]) 函数用于当函数参数已经存在于一个元组或字典中时,间接地调用函数。args是一个包含将要提供给函数的按位置传递的参数的元组。如果省略了args,任 何参数都不会被传递,kwargs是一个包含关键字参数的字典。简单说apply()的返回值就是func()的返回值,apply()的元素参数是有序的,元素的顺序必须和func()形式参数的顺序一致,与map的区别是前者针对column,后者针对元素
lambda是匿名函数,即不再使用def的形式,可以简化脚本,使结构不冗余何简洁
a = lambda x : x + 1 a(10) 11
两者结合可以做很多很多事情,比如split在series里很多功能不可用,而index就可以做
比如有一串数据如下,要切分为总数,正确数,正确率,则可这样做
96%(1368608/1412722)
97%(1389916/1427922)
97%(1338695/1373803)
96%(1691941/1745196)
95%(1878802/1971608)
97%(944218/968845)
96%(1294939/1336576)
import pandas as pd
#先生成一个dataframe
d = {"col1" : ["96%(1368608/1412722)",
"97%(1389916/1427922)",
"97%(1338695/1373803)",
"96%(1691941/1745196)",
"95%(1878802/1971608)",
"97%(944218/968845)",
"96%(1294939/1336576)"]}
df1 = pd.DataFrame(d)
#切分原文中识别率总数,采用apply + 匿名函数
#lambda 函数的意思是选取x的序列值 ,比如 x[6:9]
#index函数的意思是把当前字符位置转变为所在位置的位数
#-1是最后一位
df1['正确数'] = df1.iloc[:,0].apply(lambda x : x[x.index('(') + 1 : x.index('/')])
df1['总数'] = df1.iloc[:,0].apply(lambda x : x[x.index('/') + 1 : -1])
df1['正确率'] = df1.iloc[:,0].apply(lambda x : x[:x.index('(')])
df1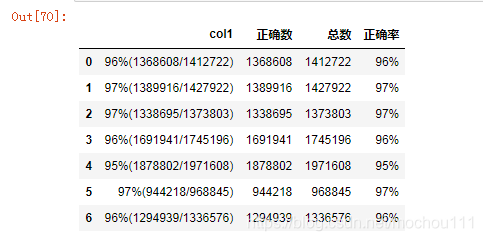
示例2
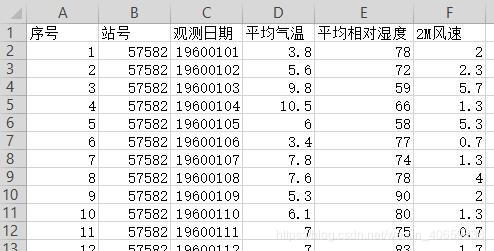
由一组dataframe数据,包括有数值型的三列气象要素,由这三列通过公式计算人体舒适指数
应用到的人体舒适指数计算公式:

import pandas as pd
import numpy as np
import math
path='D:\\data\\57582.csv' #文件路径
data=pd.read_csv(path,index_col=0,encoding='gbk') #读取数据有中文时用gbk解码
#定义舒适指数公式函数,结果保留1位小数
def get_CHB(T,RH,S):
return round(1.8*T-0.55*(1.8*T-26)*(1-RH/100)-3.2*math.sqrt(S)+32,1)
#增加一列CHB并计算数据后赋值
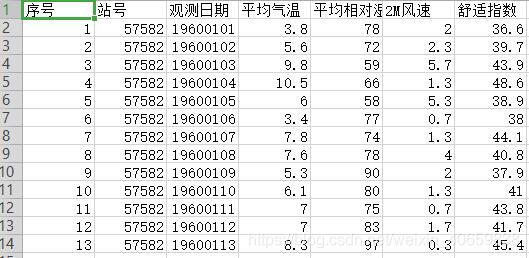
data['舒适指数']=data.apply(lambda x:get_CHB(x['平均气温'],x['平均相对湿度'],x['2M风速']),axis=1)
#打印结果
print(data)
#保存结果
data.to_csv('D:\\CHB.csv',encoding='gbk')
代码中使用了apply和lambda的组合,传入的参数x为整个data数据,在函数中引入的参数则是x[‘平均气温’],x[‘平均相对湿度’],x[‘2M风速’],与自定义的函数get_CHB对应。最后需使用axis=1来指定是对列进行运算。
结果如图所示:
到此这篇关于pandas中关于apply+lambda的应用的文章就介绍到这了,更多相关pandas apply+lambda内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
加载全部内容