R语言数据类型与相应运算
洋洋菜鸟 人气:0一、常量与变量
1.常量
R 语言基本的数据类型有数值型,逻辑型(TRUE, FALSE),文本(字符串)。 支持缺失值,有专门的复数类型。
常量是指直接写在程序中的值。
数值型常量包括整型、单精度、双精度等,一般不需要区分。写法如 123, 123.45, -123.45,-0.012, 1.23E2, -1.2E-2 等。为了表示 123 是整型,可以写成 123L。
字符型常量用两个双撇号或两个单撇号包围,如"Li Ming" 或'Li Ming'。字符型支持中文,如"李明" 或'李明'。国内的中文编码主要有 GBK 编码和 UTF-8 编码,有时会遇到编码错误造成乱码的题,MS Windows 下 R 程序 一般用 GBK 编码,但是 RStudio 软件采用 UTF-8 编码。在 R 软件内字符串一般用 UTF-8 编码保存。
逻辑型常量只有 TRUE 和 FALSE。
缺失值用 NA 表示。统计计算中经常会遇到缺失值,表示记录丢失、因为错误而不能用、节假日没有数据等。除了数值型,逻辑型和字符型也可以有缺失值,而且字符型的空白值不会自动辨识为缺失值,需要自己规定。R 支持特殊的 Inf 值,这是实数型值,表示正无穷大,不算缺失值。
复数常量写法如 2.2 + 3.5i, 1i 等。
2.变量
程序语言中的变量用来保存输入的值或者计算得到的值。在 R 中,变量可以保存所有的数据类型,比如标量、向量、矩阵、数据框、函数等。
变量都有变量名,R 变量名必须以字母、数字、下划线和句点组成,变量名的第一个字符不能取为数字。在中文环境下,汉字也可以作为变量名的合法字符使用。变量名是区分大小写的,y 和 Y 是两个不同的变量名。
变量名举例: x, x1, X, cancer.tab, clean_data, diseaseData。
用 <-赋值的方法定义变量。<-也可以写成 =,但是 <-更直观。如
x5 <- 6.25 x6 = sqrt(x5)
二、数据类型
R 语言基本的数据类型有数值,逻辑型(TRUE, FALSE),文本(字符串)。支持缺失值,有专门的复数类型。
R 语言数据结构包括向量,矩阵和数据框,多维数组,列表,对象等。数据中元素、行、列还可以用名字访问。最基本的是向量类型。向量类型数据的访问方式也是其他数据类型访问方式的基础。
三、数值型向量
向量是将若干个基础类型相同的值存储在一起,各个元素可以按序号访问。如 果将若干个数值存储在一起可以用序号访问,就叫做一个数值型向量。
3.1 c() 函数
用 c() 函数把多个元素或向量组合成一个向量。如:
marks <- c(10, 6, 4, 7, 8) marks
返回:

再如:
x <- c(1:3, 10:13) x
返回:

再如:
x1 <- c(1, 2) x2 <- c(3, 4) x <- c(x1, x2) x
返回:

3.2 length(x)
length(x) 可以求 x 的长度
x <- c(1:3, 10:13) length(x)
返回:

3.3 numeric()
numeric() 函数可以用来初始化一个指定元素个数而元素都等于零的数值型向量,如 numeric(10) 会生成元素为 10 个零的向量,长度为零的向量表示为 numeric(0)。
numeric(10)
返回:

四、向量运算
1.标量和标量运算
单个数值称为标量,R 没有单独的标量类型,标量实际是长度为 1 的向量。 R 中四则运算用 + - * / ˆ 表示 (加、减、乘、除、乘方),如
1.5 + 2.3 - 0.6 + 2.1*1.2 - 1.5/0.5 + 2^3 ## [1] 10.72
返回:

R 中四则运算仍遵从通常的优先级规则,可以用圆括号 () 改变运算的先后次序。如
1.5 + 2.3 - (0.6 + 2.1)*1.2 - 1.5/0.5 + 2^3 ## [1] 5.56
除了加、减、乘、除、乘方,R 还支持整除运算和求余运算。用%/% 表示整除, 用%% 表示求余。如
5 %/% 3 ## [1] 1 5 %% 3 ## [1] 2
返回:

2.向量与标量运算
向量与标量的运算为每个元素与标量的运算, 如
x <- c(1, 10) x + 2 ## [1] 3 12 x - 2 ## [1] -1 8 x * 2 ## [1] 2 20 x / 2 ## [1] 0.5 5.0 x ^ 2 ## [1] 1 100 2 / x ## [1] 2.0 0.2 2 ^ x ## [1] 2 1024 x %% 2 ##[1] 1 0 x %/% 2 ##[1] 0 5
返回:
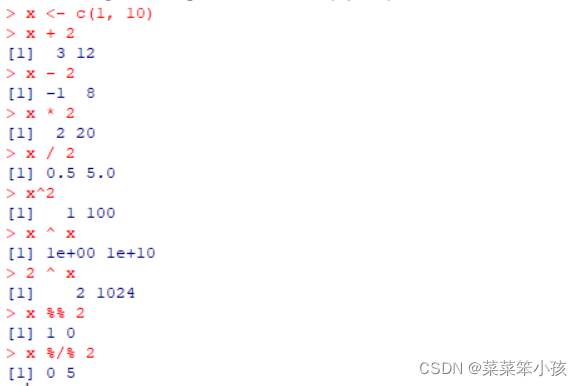
一个向量乘以一个标量,就是线性代数中的数乘运算。 四则运算时如果有缺失值,缺失元素参加的运算相应结果元素仍缺失。如
c(1, NA, 3) + 10
返回:
![]()
3.等长向量运算
等长向量的运算为对应元素两两运算。如
x1 <- c(1, 10) x2 <- c(4, 2) x1 + x2
返回:

同样也可以进行减,乘,除;如
x1 - x2 ## [1] -3 8 x1 * x2 ## [1] 4 20 x1 / x2 ## [1] 0.25 5.00
4.不等长向量的运算
两个不等长向量的四则运算,如果其长度为倍数关系,规则是每次从头重复利用短的一个。如:
x1 <- c(10, 20) x2 <- c(1, 3, 5, 7) x1 + x2
返回:

不仅是四则运算,R 中有两个或多个向量按照元素一一对应参与某种运算或函数调用时,如果向量长度不同,一般都采用这样的规则。 如果两个向量的长度不是倍数关系,会给出警告信息。如
c(1,2) + c(1,2,3)
返回:

五、向量函数
1.向量化的函数
R 中的函数一般都是向量化的: 在 R 中,如果普通的一元函数以向量为自变量,一般会对每个元素计算。这样的函数包括 sqrt, log10, log, exp, sin, cos, tan 等许多。如
sqrt(c(1, 4, 6.25))
返回:
![]()
为了查看这些基础的数学函数的列表,运行命令 help.start(),点击链接 “Search Engine and Keywords”,找到 “Mathematics” 栏目,浏览其中的 “arith” 和 “math” 链接中的说明。
常用的数学函数有:常用的数学函数有:
• 舍入:ceiling, floor, round, signif, trunc, zapsmall
• 符号函数 sign
• 绝对值 abs
• 平方根 sqrt
• 对数与指数函数 log, exp, log10, log2
• 三角函数 sin, cos, tan
• 反三角函数 asin, acos, atan, atan2
• 双曲函数 sinh, cosh, tanh
• 反双曲函数 asinh, acosh, atanh
有一些不太常用的数学函数:
• 贝塔函数 beta, lbeta
• 伽 玛 函 数 gamma, lgamma, digamma, trigamma, tetragamma, pentagamma
• 组合数 choose, lchoose
• 富利叶变换和卷积 fft, mvfft, convolve
• 正交多项式 poly
• 求根 polyroot, uniroot
• 最优化 optimize, optim
• Bessel 函数 besselI, besselK, besselJ, besselY
• 样条插值 spline, splinefun
• 简单的微分 deriv
如果自己编写的函数没有考虑向量化问题,可以用 Vectorize() 函数将其转换成向量化版本。
2.排序函数
sort(x) 返回排序结果。rev(x) 返回把各元素排列次序反转后的结果。order(x) 返回排序用的下标。如
x <- c(33, 55, 11) sort(x) ## [1] 11 33 55 rev(sort(x)) ## [1] 55 33 11 order(x) ## [1] 3 1 2 x[order(x)] ## [1] 11 33 55
返回:

order(x) 结果中 3 是 x 的最小元素 11 所在的位置下标,1 是 x 的 第二小元素 33 所在的位置下标,2 是 x 的最大元素 55 所在的位置下标。
3.统计函数
sum(求和), mean(求平均值), var(求样本方差), sd(求样本标准差), min(求最小值), max(求最大值), range(求最小值和最大值) 等函数称为统计函数,把输入向量看作样本,计算样本统计量。prod 求所有元素的乘积。
cumsum 和 cumprod 计算累加和累乘积。如
cumsum(1:5)
返回:
![]()
cumprod(1:5)
返回:
![]()
其它一些类似函数有 pmax, pmin, cummax, cummin 等。
4.生成规则序列的函数
seq 函数是冒号运算符的推广。比如
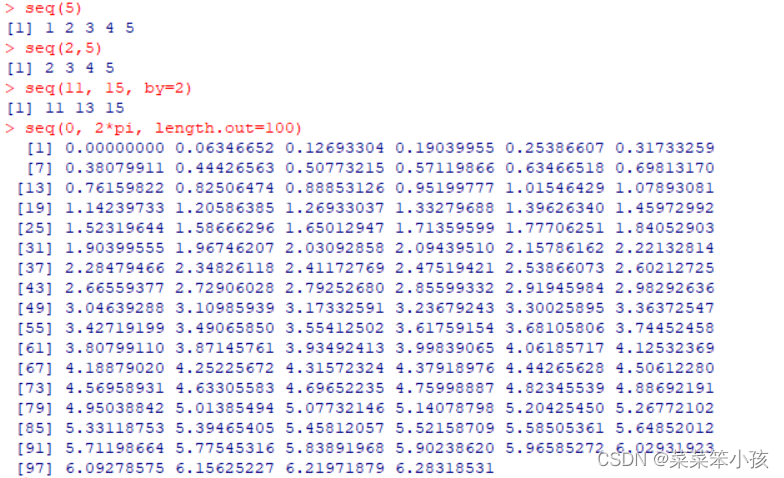
seq(5) seq(2,5) seq(11, 15, by=2) #产生从 0 到 2π 的等间隔序列,序列长度指定为 100 seq(0, 2*pi, length.out=100)
返回:
在使用变量名时次序可以颠倒,比如
seq(to=5, from=2)
返回:
![]()
rep() 函数用来产生重复数值。
为了产生一个初值为零的长度为 n 的向量,用 x <- rep(0, n) 。
rep(c(1,3), 2)
返回:
![]()
再比如:
rep(c(1,3), c(2,4))
把第一自变量的第一个元素 1 按照第二自变量中第一个元素 2 的次数重复,把第一自变量 中第二个元素 3 按照第二自变量中第二个元素 4 的次数重复,返回:
![]()
如 果 希 望 重 复 完 一 个 元 素 后 再 重 复 另 一 元 素, 用 each= 选 项, 比 如
rep(c(1,3), each=2)
返回:
![]()
六、 复数向量
复数常数表示如 3.5+2.4i, 1i。用函数 complex() 生成复数向量,指定实部和虚部。如
complex(c(1,0,-1,0), c(0,1,0,-1))
返回:
![]()
在 complex() 中可以用 mod 和 arg 指定模和辐角,如
complex(mod=1,arg=(0:3)/2*pi)
返回:
![]()
用 Re(z) 求 z 的实部,用 Im(z) 求 z 的虚部,用 Mod(z) 或 abs(z) 求 z 的模,用 Arg(z) 求 z 的辐角,用 Conj(z) 求 z 的共轭。 sqrt, log, exp, sin 等函数对复数也有定义,但是函数定义域在自变量为实数时可能有限制而复数无限制,这时需要区分自变量类型。如
sqrt(-1)sqrt(-1 + 0i)
返回:

练习
1. 显示 1 到 100 的整数的平方根和立方根(提示:立方根就是三分之一次 方)。
2. 设有 10 个人的小测验成绩为:
77 60 91 73 85 82 35 100 66 75
(1) 把这 10 个成绩存入变量 x;
(2) 从小到大排序;
(3) 计算 order(x),解释 order(x) 结果中第 3 项代表的意义。
(4) 计算这些成绩的平均值、标准差、最小值、最大值、中位数。
3. 生成 [0, 1] 区间上等间隔的 100 个格子点存入变量 x 中。
加载全部内容